






















































std::list
As seen in the previous section, std::forward_list is just a nice and thin wrapper over the basic linked list. It doesn't provide functions to insert elements at the end, traverse backward, or get the size of the list, among other useful operations. The functionality is limited to save memory and to retain fast performance. Apart from that, the iterators of forward_list can support very few operations. In most practical situations in any application, functions such as those for inserting something at the end and getting the size of the container are very useful and frequently used. Hence, std::forward_list is not always the desired container, where fast insertion is required. To overcome these limitations of std::forward_list, C++ provides std::list, which has several additional features owing to the fact that it is a bidirectional linked list, also known as a doubly-linked list. However, note that this comes at the cost of additional memory requirements.
The plain version of a doubly-linked list looks something like this:
struct doubly_linked_list
{
int data;
doubly_linked_list *next, *prev;
};
As you can see, it has one extra pointer to point to the previous element. Thus, it provides us with a way in which to traverse backward, and we can also store the size and the last element to support fast push_back and size operations. Also, just like forward_list, it can also support customer allocator as a template parameter.
Common Functions for std::list
Most of the functions for std::list are either the same or similar to the functions of std::forward_list, with a few tweaks. One of the tweaks is that function names ending with _after have their equivalents without _after. Therefore, insert_after and emplace_after become simply insert and emplace. This is because, with the std::list iterator, we can also traverse backward, and hence there's no need to provide the iterator of the previous element. Instead, we can provide the iterator of the exact element at which we want to perform the operation. Apart from that, std::list also provides fast operations for push_back, emplace_back, and pop_back. The following exercise demonstrates the use of insertion and deletion functions for std::list.
Exercise 6: Insertion and Deletion Functions for std::list
In this exercise, we shall create a simple list of integers using std::list and explore various ways in which we can insert and delete elements from it:
- First of all, let's include the required headers:
#include <iostream>
#include <list>
int main()
{
- Then, initialize a list with a few elements and experiment on it with various insertion functions:
std::list<int> list1 = {1, 2, 3, 4, 5};
list1.push_back(6);
// list becomes {1, 2, 3, 4, 5, 6}
list1.insert(next(list1.begin()), 0);
// list becomes {1, 0, 2, 3, 4, 5, 6}
list1.insert(list1.end(), 7);
// list becomes {1, 0, 2, 3, 4, 5, 6, 7}
As you can see, the push_back function inserts an element at the end. The insert function inserts 0 after the first element, which is indicated by next(list1.begin()). After that, we are inserting 7 after the last element, which is indicated by list1.end().
- Now, let's take a look at the remove function, pop_back, which was not present in forward_list:
list1.pop_back();
// list becomes {1, 0, 2, 3, 4, 5, 6}
std::cout << "List after insertion & deletion functions: ";
for(auto i: list1)
std::cout << i << " ";
}
- Running this exercise should give the following output:
List after insertion & deletion functions: 1 0 2 3 4 5 6
Here, we are removing the last element that we just inserted.
Note
Although push_front, insert, pop_front, and erase have the same time complexity as equivalent functions for forward_list, these are slightly more expensive for std::list. The reason for this is that there are two pointers in each node of a list instead of just one, as in the case of forward_list. So, we have to maintain the validity of the value of both the pointers. Hence, when we are repointing these variables, we need to make almost double the effort compared to singly linked lists.
Earlier, we saw an insertion for a singly-linked list. Let's now demonstrate what pointer manipulation looks like for a doubly-linked list in the following diagram:
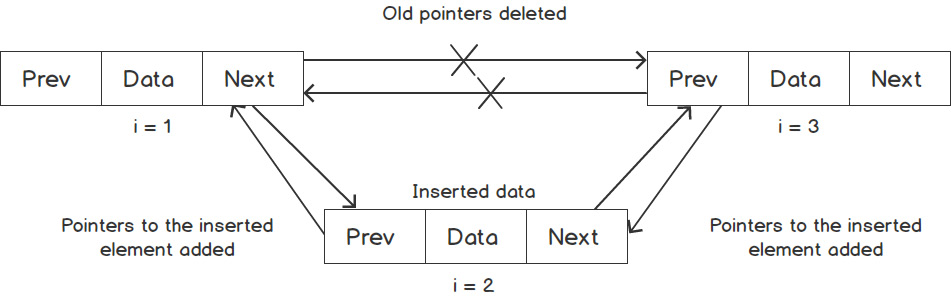
Figure 1.7: Inserting an element in a doubly linked list
As you can see, the number of operations is constant even in the case of std::list; however, compared to forward_list, we have to fix both the prev and next pointers in order to maintain a doubly-linked list, and this costs us almost double in terms of memory and performance compared to forward_list. A similar idea applies to other functions as well.
Other functions such as remove, remove_if, sort, unique, and reverse provide similar functionalities as compared to their equivalent functions for std::forward_list.
Bidirectional Iterators
In the Iterators section, we saw the difference between the flexibility of array-based random access iterators and forward_list-based forward iterators. The flexibility of std::list::iterator lies between both of them. It is more flexible compared to forward iterators, since it can allow us to traverse backward. Hence, std::list also supports functions for reverse traversal by exposing reverse iterators where the operations are inverted. Having said that, it is not as flexible as random access iterators. Although we can advance in either direction by any number of moves, since these moves have to be done by traversing the elements one by one instead of jumping directly to the desired element, the time complexity is still linear, and not a constant, as in the case of random access iterators. Since these iterators can move in either direction, they are known as bidirectional iterators.
Iterator Invalidation for Different Containers
So far, we've seen that iterators provide us with a uniform way of accessing, traversing, inserting, and deleting elements from any container. But there are some cases when iterators become invalid after modifying the container, because the iterators are implemented based on pointers, which are bound to memory addresses. So, if the memory address of any node or element changes because of modification in the container, it invalidates the iterator, and using it regardless can lead to undefined behavior.
For example, a very basic example would be vector::push_back, which simply adds a new element at the end. However, as we saw earlier, in some cases, it also requires the movement of all the elements to a new buffer. Hence, all iterators, pointers, and even the references to any of the existing elements will be invalidated. Similarly, if the vector::insert function leads to reallocation, all the elements will need to be moved. Hence, all the iterators, pointers, and references are invalidated. If not, the function will invalidate all the iterators pointing to the element that is on the right side of the insertion position, since these elements will be shifted during the process.
Unlike vectors, linked list-based iterators are safer for insertion and deletion operations because the elements will not be shifted or moved. Hence, none of the insertion functions for std::list or forward_list affect the validity of the iterators. An exception is that deletion-related operations invalidate iterators of the elements that are deleted, which is obvious and reasonable. It doesn't affect the validity of the iterators of the rest of the elements. The following example shows iterator invalidation for different iterators:
std::vector<int> vec = {1, 2, 3, 4, 5};
auto it4 = vec.begin() + 4;
// it4 now points to vec[4]
vec.insert(vec.begin() + 2, 0);
// vec becomes {1, 2, 0, 3, 4, 5}
it4 is invalid now, since it comes after the insertion position. Accessing it will lead to undefined behavior:
std::list<int> lst = {1, 2, 3, 4, 5};
auto l_it4 = next(lst.begin(), 4);
lst.insert(next(lst.begin(), 2), 0);
// l_it4 remains valid
As we saw, std::list is much more flexible compared to std::forward_list. A lot of operations, such as size, push_back, and pop_back, are provided, which operate with a time complexity of O(1). Hence, std::list is used more frequently compared to std::forward_list. forward_list is a better alternative if we have very strict constraints of memory and performance, and if we are sure that we don't want to traverse backward. So, in most cases, std::list is a safer choice.
Activity 2: Simulating a Card Game
In this activity, we'll analyze a given situation and try to come up with the most suitable data structure to achieve the best performance.
We'll try to simulate a card game. There are 4 players in the game, and each starts with 13 random cards. Then, we'll try to pick one card from each player's hand randomly. That way, we'll have 4 cards for comparison. After that, we'll remove the matching cards from those 4 cards. The remaining cards, if any, will be drawn back by the players who put them out. If there are multiple matching pairs out of which only one can be removed, we can choose either one. If there are no matching pairs, players can shuffle their own set of cards.
Now, we need to continue this process over and over until at least one of them is out of cards. The first one to get rid of all their cards wins the game. Then, we shall print the winner at the end.
Perform the following steps to solve the activity:
- First, determine which container would be the most suitable to store the cards of each player. We should have four containers that have a set of cards – one for each player.
- Write a function to initialize and shuffle the cards.
- Write a function to randomly deal all the cards among the four players.
- Write a matching function. This function will pick a card from each player and compare it as required by the rules of the game. Then, it will remove the necessary cards. We have to choose the card wisely so that removing it would be faster. This parameter should also be considered while deciding on the container.
- Now, let's write a function, to see whether we have a winner.
- Finally, we'll write the core logic of the game. This will simply call the matching function until we have a winner based on the function written in the previous step.
Note
The solution to this activity can be found on page 482.





