






















































In some cases, high memory usage constitutes an issue. For example, if we want to handle a huge number of particles, we will incur a memory overhead due to the creation of many Particle instances.
The memory_profiler module summarizes, in a way similar to line_profiler, the memory usage of the process.
Just like line_profiler, memory_profiler also requires the instrumentation of the source code by placing a @profile decorator on the function we intend to monitor. In our case, we want to analyze the benchmark function.
We can slightly change benchmark to instantiate a considerable amount (100000) of Particle instances and decrease the simulation time:
def benchmark_memory():
particles = [Particle(uniform(-1.0, 1.0),
uniform(-1.0, 1.0),
uniform(-1.0, 1.0))
for i in range(100000)]
simulator = ParticleSimulator(particles)
simulator.evolve(0.001)
We can use memory_profiler from an IPython shell through the %mprun magic command as shown in the following screenshot:
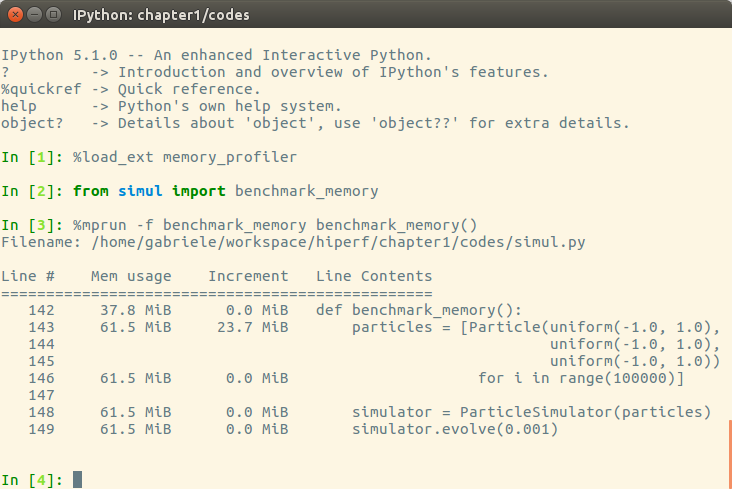
From the Increment column, we can see that 100,000 Particle objects take 23.7 MiB of memory.
We can use __slots__ on the Particle class to reduce its memory footprint. This feature saves some memory by avoiding storing the variables of the instance in an internal dictionary. This strategy, however, has a drawback--it prevents the addition of attributes other than the ones specified in __slots__ :
class Particle:
__slots__ = ('x', 'y', 'ang_vel')
def __init__(self, x, y, ang_vel):
self.x = x
self.y = y
self.ang_vel = ang_vel
We can now rerun our benchmark to assess the change in memory consumption, the result is displayed in the following screenshot:

By rewriting the Particle class using __slots__, we can save about 10 MiB of memory.





