






















































Microservices, microservices, microservices. We are all in the process of rewriting or planning to rewrite our monoliths into microservices. Some of us already did it. We are putting them into containers and deploying them through one of the schedulers. We are marching into a glorious future. There's nothing that can stop us now. Except... We, as an industry, are not yet ready for microservices. One thing is to design our services in a way that they are stateless, fault tolerant, scalable, and so on. The other is to incorporate those services into a system as a whole.
Unless you just started a new project, the chances are that you still did not reach "microservices nirvana" and that quite a few legacy services are floating around. However, for the sake of brevity and the urge to get to the point, I will assume that all the services you're in control of are truly microservices. Does that mean that the whole system reached that nirvana state? Is deployment of a service (no matter who wrote it) entirely independent from the rest of the system? Most likely it isn't.
You are practicing continuous deployment, aren't you? I will assume you are. Now, let's say that you just finished the first release of your new service. That first version is the first commit to your code repository. Your CD tool of choice detected the change in your code repository and started the CD pipeline. At the end of it, the service will be deployed to production. I can see a smile on your face. It's that expression of happiness that can be seen only after a child is born, or a service is deployed to production for the first time. That smile should not be long lasting since deploying a service is only the beginning. It needs to be integrated with the rest of the system. The proxy needs to be reconfigured. Logs parser needs to be updated with the format produced by the new service. Monitoring system needs to become aware of the new service. Alerts need to be created with the goal of sending warning and error notifications when the state of the service reaches certain thresholds. The whole system has to adapt to the new service and incorporate the new variables introduced with the commit we made a few moments ago.
How do we adapt the system so that it takes the new service into account? How do we make that service be an integral part of the system?
Unless you are writing everything yourself (in which case you must be Google), your system consists of a mixture of services developed by you and services written and maintained by others. You probably use a third-party proxy (hopefully that's Docker Flow Proxy - https://proxy.dockerflow.com/). You might have chosen the ELK stack or Splunk for centralized logging. How about monitoring? Maybe it's Nagios, or it might be Prometheus. No matter the choices you made, you are not in control of the architecture of the whole system. Heck, you're probably not even in control of all the services you wrote.
Most of the third-party services are not designed to work in a highly dynamic cluster. When you deployed that first release of the service, you might have had to configure the proxy manually. You might have had to add a few parsing rules to your LogStash config. Your Prometheus targets had to be updated. New alerting rules had to be added. And so on, and so forth. Even if all those tasks are automated, the CD pipeline would have to become too big, and the process would be too flaky.
I will try to be an optimist and assume that you survived the hurdle of configuring all your third-party tools to work seamlessly with the new service. There will be no time to rest since that same service (or some other) will soon be updated. Someone will make a change that will result in a higher memory threshold. That means that, for example, monitoring tool needs to be reconfigured. You might say that's OK since it happens occasionally but that would not be true either. If we adopted microservices and continuous deployment, "occasionally" might mean "on any of the frequent commits." Remember, teams are small, and they are independent. A change that affects the rest of the system might come at any moment, and we need to be ready for it.
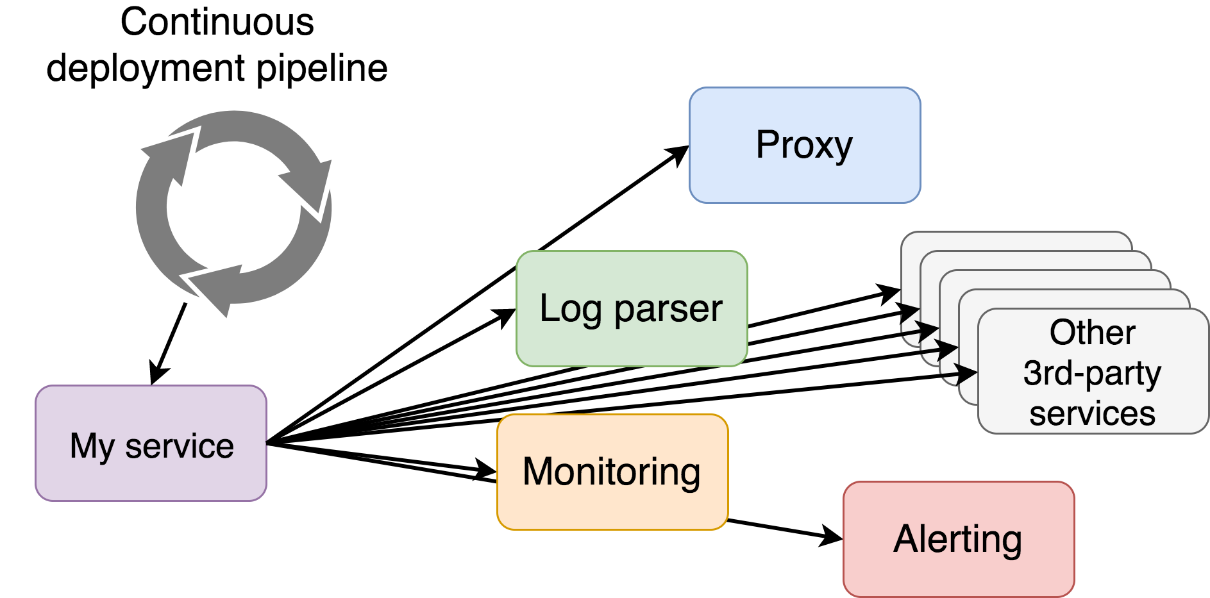
One of the major limitations of third-party services is their reliance on static configuration. Take Prometheus as an example. It is, potentially, in charge of monitoring all of your services as well as hardware, networking, and what so not. Each of the targets it observes might have a different set of metrics and a different set of conditions that will fire alerts. Every time we want to add a new target, we need to modify Prometheus configuration and reload it. That means that, for fault tolerance, we have to store that configuration file on a network drive, have some templating mechanism which updates it with every new service and, potentially, with every update of an existing service. So, we would deploy our fancy new service, update the template that generates Prometheus config, create a new config, overwrite the one stored on the network drive, and reload Prometheus. Even that is not enough because data that fuels those templates needs to be stored somewhere meaning that we need to register every service in a service registry (or use the one baked in Docker) and make sure that templating solution reads from it.
Part of the mess could be avoided if Prometheus would be configurable through its API. Still, configuration API more would remove the need for templates but would not eliminate the need for a network drive. Its configuration is its state, and it has to be preserved.
This line of thinking is historical. We are used to monolithic based systems where information is scattered all over the place. We are slowly moving towards a different model. The system is broken into many smaller services, and each of them is a complete source of truth for a problem domain it solves. If you need information about a service, ask for it, or have a mechanism that will push that information to you. A service does not know nor it should care who uses it and how.
The service itself should contain all the data that describes it. If it should reconfigure a proxy, that info should be part of the service. It should contain a pattern it uses to output logs. It should have the addresses of targets that a monitoring tool should scrape from. It should have the info that will be used to launch alerts. In other words, everything that a service needs should be defined in that service. Not somewhere else. The origin of the data we need to adapt a system to the new service should not be distributed across multiple locations, but inside the service we're deploying. Since we are all using containers (aren't we?), the best place to define all that info are service labels.
If your service should be accessible on a path /v1/my-fancy-service, define a label by using argument --label servicePath=/v1/my-fancy-service. If Prometheus should scrape metrics on port 8080, define a label --label scrapePort=8080. And so on and so forth.
Why is all that significant? Among other reasons, when we define all the data a service needs inside that service, we have a single place that contains the complete truth about a service. That makes configuration easier, it makes the team in charge of a service self-sufficient, it makes deployments more manageable and less error prone, and so on and so forth.

Defining all the info of a service we're developing inside that same service is not a problem. The problem is that most of the third-party services we're using are not designed to leverage that info. Remember, the data about a service needs to be distributed across the cluster. It needs to reach all other services that work in conjunction with the services we're developing and deploying. We do not want to define that info in multiple locations since that increases maintenance costs and introduces potential problems caused by human errors. Instead, we want to define everything inside a service we're deploying and propagate that information throughout the cluster.
We do not want to define and maintain the same info in multiple locations, and we do want to keep that info at the source, but the third-party services are incapable of obtaining that data from the source. If we discard the option of modifying third-party services, the only choice left is to extend them so that they can pull or receive the data they need.
What we truly need are third-party services capable of discovering information from services we are deploying. That discovery can be pull (a service pulls info from another service) or push based (a service acts as a middle-men and pushes data from one service to another). No matter whether discovery relies on push or pull, a service that receives data needs to be able to reconfigure itself. All that needs to be combined with a system that will be able to detect that a service was deployed or updated and notify all interested parties.
The ultimate goal is to design a system that is capable of adapting to any service we throw at it, as well as to changed conditions of a cluster. The final objective is to have a self-adapting and self-healing system that will continue operating efficiently even when we are on vacations.



