






















































Choosing your analysis strategy
Reverse engineering is a time-consuming process, and in many cases, there aren't the resources available to allow engineers to dive as deep as they would like to. Prioritizing the most important things and focusing on them will ensure that the best result is produced within the allocated time every time. Here is some advice that may help in this challenging task.
Understand your audience
Depending on who is going to use the result of your work, the actionable deliverables may be very different. Examples of the potential use cases for reverse engineering include the following:
- Threat intelligence: Here, the focus will be mainly on obtaining IoCs, such as hashes, filenames, and network artifacts. Therefore, extracting embedded payloads and downloading remote samples, as well as finding other related modules involved and extracting C&C information from all of them, will likely be the top priority.
- AV detection: In this case, the focus will be on anything unique enough to create a robust detection that doesn’t produce false positives (FPs). Examples are distinctive pieces of code and strings related to the malicious functionality and any custom encryption algorithms used. Understanding the main logic will help choose the right category, and code and data similarity will lead to assigning the malware family.
- Technical article or conference presentation: Here, the most important part will be interesting novel technical details related to functionality, similarities with other malware families, and actor attribution.
- Article for the general public: For non-technical people, it is common to provide a high-level description of functionality without many technical details, focusing mainly on impact.
Answer your audience’s questions
It’s very important to answer the main questions your audience is asking. Make the answers clear and easy to find in your analysis report.
Here is a list of possible questions your audience might need an answer to in your report:
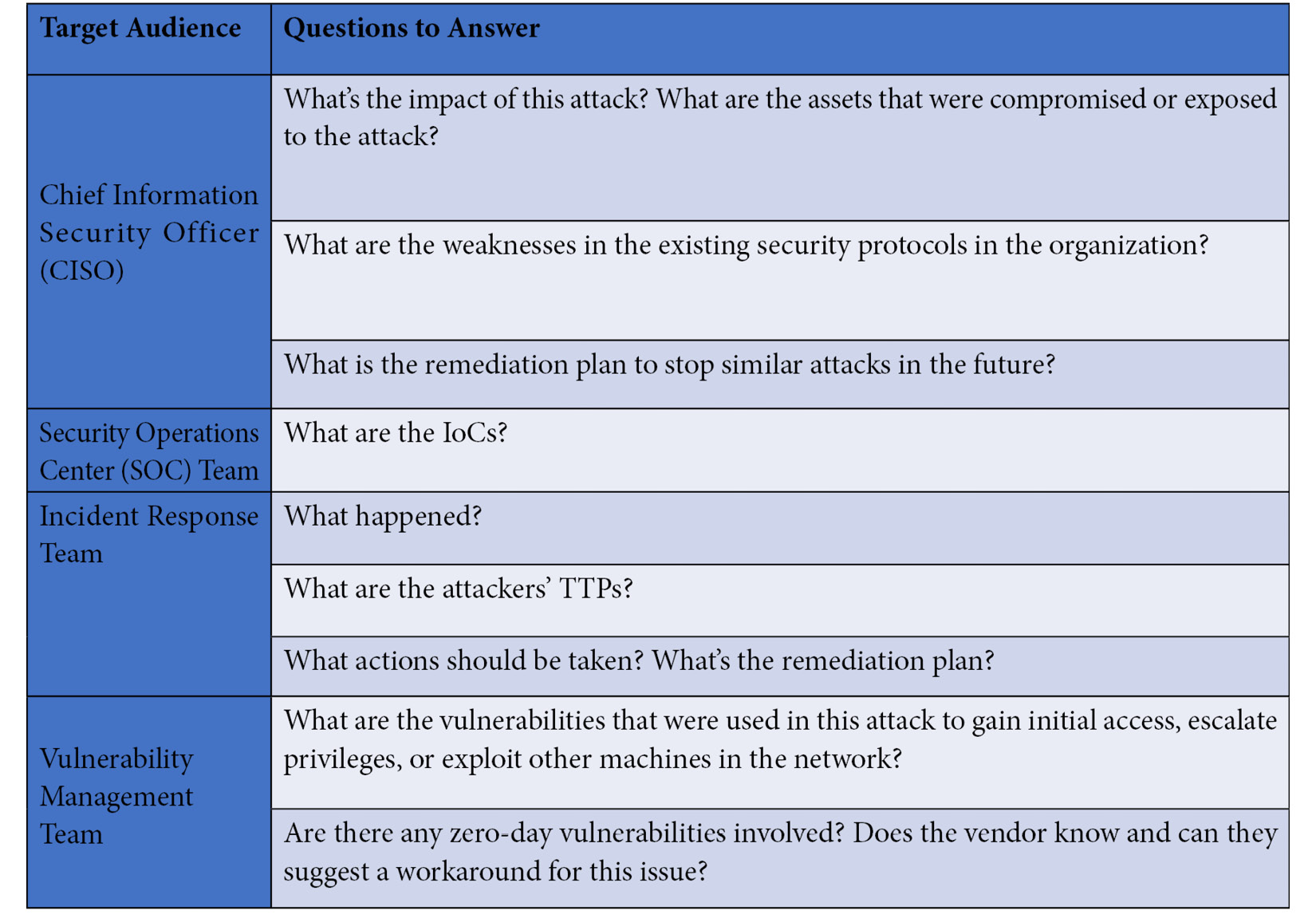
As long as this part is clear, we can start prioritizing particular topics.
Define your goals
Once the audience is confirmed, define your goals carefully based on the resources available: first, time and skillset. After this, prioritize the selected goals and focus on the most important ones first. It is very easy to get lost in assembly when doing static analysis, so having a checklist of what needs to be done and in what priority will help you get back on track.
Avoid unnecessary technical details
Regardless of who is going to consume the result of your work, having too many extra details won’t show your level of expertise but will simply complicate the understanding of the work and result in wasted time. Common examples include executed instructions, WinAPIs used, standard registry keys accessed, or mutexes created. Therefore, you should do the following:
- Choose the level of detail required depending on the target audience.
- If some fact doesn’t help the reader, avoid elaborating on it.
- Don’t just mention technical details – explain their high-level purpose and why the attackers had to explicitly use them.
Finally, make sure that the most important sections are covered in detail and are definitely correct. Never attempt to make statements based purely on gut feeling or prior knowledge without any material facts related to the current sample. You can always use the appropriate wording for something that you have spotted but don’t have time to dig deeper into (for example: “there are indications that... but more work is required to confirm it”).
Example structures
Here are some of the details that are generally included in the resulting work, depending on its format and the audience.
Technical article
In most cases, the following information will be useful:
- Sample(s) details:
- Hashes (MD5, SHA1, SHA2)
- Compilation timestamps
- File types and sizes
- In-the-wild (ITW) filenames
- AV vendors’ detections
- Modules’ relationships (if there are several involved)
- For each module:
- A description of the main functionality
- Persistence mechanisms
- Network communications:
- Protocols
- Encryption algorithms and keys
- C&C details (IP addresses, domains, URLs, unique whois details, host countries, and so on)
- Anti-reverse engineering techniques used
- IoCs
- Detection rules (YARA, Snort, and others)
General-public article
- High-level functionality description with a focus on the impact
- The scale of the attack
- Victim profile:
- Types of organizations targeted
- Victims’ geolocation
- Loss estimates
- Actor attribution:
- Sample similarity
- Matched IoCs (hashes, network artifacts, filenames, and so on)
- Language codepages and strings used
- Compilation timestamps
Typical analysis workflow
Now that we know what to focus on, the next question is: how do we organize the work to produce the best possible result in a timely fashion? The following steps are suggested for you to follow:
- Triage: Here, collect the maximum amount of easily available information on the sample:
- Analyze the PE header.
- Check whether the sample is likely to be packed or not (high-entropy blocks).
- Check public resources for known IoCs (hashes, network artifacts, AV detection names, and so on).
- Behavioral analysis: Most of the information will be obtained from file, registry, and network operations. This way, we will have an idea about the capabilities of the potential sample.
- Unpacking (if necessary): Static analysis is impossible before the sample is unpacked as the actual malware’s code and data are not readily available yet.
- Static analysis: Performed with the help of disassemblers and decompilers:
- Start from available strings and commonly misused WinAPIs.
- Dynamic analysis: Performed with the help of debuggers. May be quite expensive to set up and perform, so use it only when needed:
- Confirming certain functionality
- Handling string/APIs/embedded payloads/communications encryption



