






















































Introduction
Data science and analytics are taking over the whole world and the job of a data scientist is routinely being called the coolest job of the 21st century. But for all the emphasis on data, it is the science that makes you – the practitioner – truly valuable.
To practice high-quality science with data, you need to make sure it is properly sourced, cleaned, formatted, and pre-processed. This book teaches you the most essential basics of this invaluable component of the data science pipeline: data wrangling. In short, data wrangling is the process that ensures that the data is in a format that is clean, accurate, formatted, and ready to be used for data analysis.
A prominent example of data wrangling with a large amount of data is the one conducted at the Supercomputer Center of University of California San Diego (UCSD). The problem in California is that wildfires are very common, mainly because of the dry weather and extreme heat, especially during the summers. Data scientists at the UCSD Supercomputer Center gather data to predict the nature and spread direction of the fire. The data that comes from diverse sources such as weather stations, sensors in the forest, fire stations, satellite imagery, and Twitter feeds might still be incomplete or missing. This data needs to be cleaned and formatted so that it can be used to predict future occurrences of wildfires.
This is an example of how data wrangling and data science can prove to be helpful and relevant.
Importance of Data Wrangling
Oil does not come in its final form from the rig; it has to be refined. Similarly, data must be curated, massaged, and refined to be used in intelligent algorithms and consumer products. This is known as wrangling. Most data scientists spend the majority of their time data wrangling.
Data wrangling is generally done at the very first stage of a data science/analytics pipeline. After the data scientists identify useful data sources for solving the business problem (for instance, in-house database storage or internet or streaming sensor data), they then proceed to extract, clean, and format the necessary data from those sources.
Generally, the task of data wrangling involves the following steps:
Scraping raw data from multiple sources (including web and database tables)
Imputing, formatting, and transforming – basically making it ready to be used in the modeling process (such as advanced machine learning)
Handling read/write errors
Detecting outliers
Performing quick visualizations (plotting) and basic statistical analysis to judge the quality of your formatted data
This is an illustrative representation of the positioning and essential functional role of data wrangling in a typical data science pipeline:
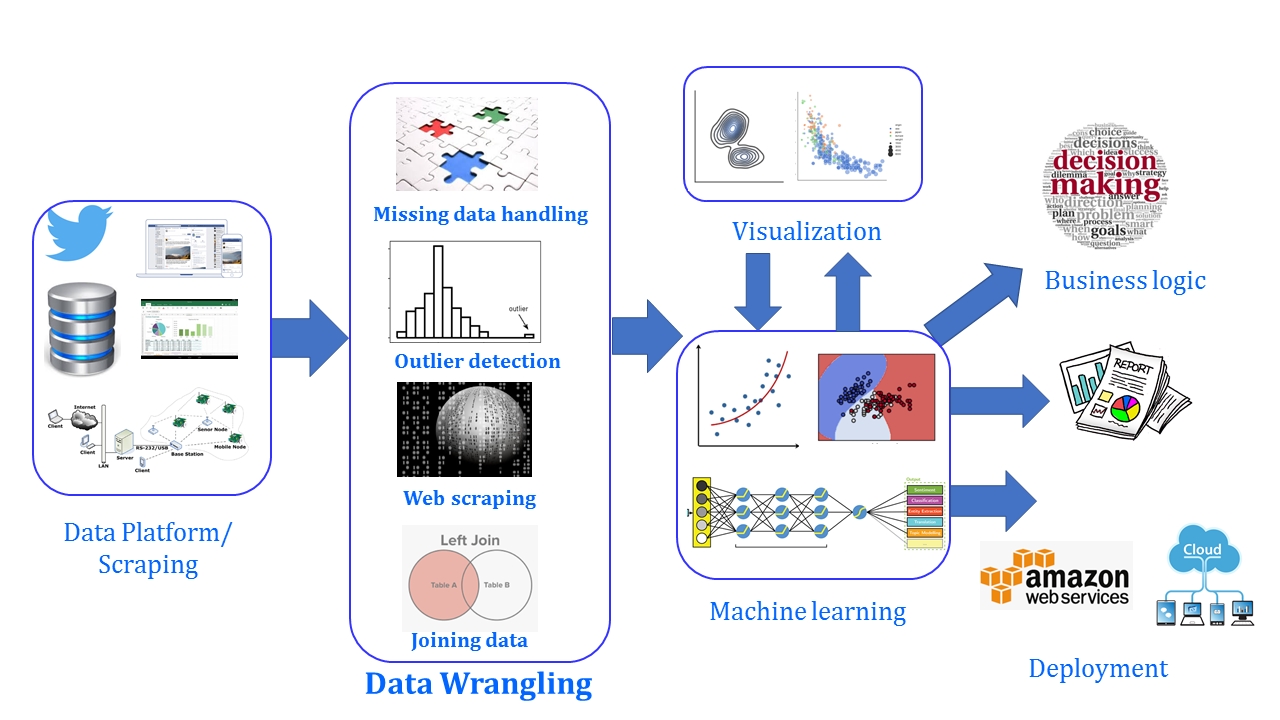
Figure 1.1: Process of data wrangling
The process of data wrangling includes first finding the appropriate data that's necessary for the analysis. This data can be from one or multiple sources, such as tweets, bank transaction statements in a relational database, sensor data, and so on. This data needs to be cleaned. If there is missing data, we will either delete or substitute it, with the help of several techniques. If there are outliers, we need to first detect them and then handle them appropriately. If data is from multiple sources, we will have to perform join operations to combine it.
In an extremely rare situation, data wrangling may not be needed. For example, if the data that's necessary for a machine learning task is already stored in an acceptable format in an in-house database, then a simple SQL query may be enough to extract the data into a table, ready to be passed on to the modeling stage.




