In this section, we will take a look at how to detect breast cancer with a support vector machine (SVM). We're also going to throw in a k-nearest neighbors (KNN) clustering algorithm, and compare the results. We will be using the conda distribution, which is a great way to download and install Python since conda is a package manager, meaning that it makes downloading and installing the necessary packages easy and straightforward. With conda, we're also going to install the Jupyter Notebook, which we will use to program in Python. This will make sharing code and collaborating across different platforms much easier.
Now, let's go through the steps required to use Anaconda, as follows:
- Start by downloading conda, and make sure that is in your Path variables.
- Open up a Command Prompt, which is the best way to use conda, and go into the Tutorial folder.
- If conda is in your Path variables, you can simply type conda install, followed by whichever package you need. We're going to be using numpy, so we will type that, as you can see in the following screenshot:
If you get an error saying that the command conda was not found, it means that conda isn't in the Path variables. Edit the environment variables and add conda.
- To start the Jupyter Notebook, simply type jupyter notebook and press Enter. If conda is in the path, Jupyter will be found, as well, because it's located in the same folder. It will start to load up, as shown in the following screenshot:
The folder that we're in when we type jupyter notebook is where it will open up on the web browser.
- After that, click on New, and select Python [default]. Using Python 2.7 would be preferable, as it seems to be more of a standard in the industry.
- To check that we all have the same versions, we will conduct an import step.
- Rename the notebook to Breast Cancer Detection with Machine Learning.
- Import sys, so that we can check whether we're using Python 2.7.
We will need to import numpy for computational operations and arrays, matplotlib for plotting, pandas to handle the datasets, and sklearn, to get the machine learning packages.
- We will import numpy, matplotlib, pandas, and the sklearn packages and print their versions. We can view the changes in the following screenshot:
To run the cell in Jupyter Notebook, simply press Shift + Enter. A number will pop up when it completes, and it'll print out the statements. Once again, if we encounter errors in this step and we are unable to import any of the preceding packages, we have to exit the Jupyter Notebook, type conda install, and mention whichever package we are missing in the Terminal. These will then be installed. The necessary packages and versions are shown as follows:
- Python 2.7
- 1.14 for NumPy
- Matplotlib
- Pandas
- Sklearn
The following screenshot illustrates how to import these libraries in the specific way that we're going to use them in this project:
In the following steps, we will look at how to import the different arguments in these libraries:
- First, we will import NumPy, using the command import numpy as np.
- Next, we will import the various classes and functions in sklearn - namely, preprocessing and cross_validation.
- From neighbors, we will import KNeighborsClassifier, which will be KNN.
- From sklearn.svm, we will import the support vector classifier (SVC).
- We're going to do model_selection, so that we can use both KNN and SVC in one step.
- We will then get some metrics, in which we will import the classification_report, as well as the accuracy_score.
- From pandas, we need to import plotting, which is the scatter_matrix. This will be useful when we're exploring some data visualizations, before diving into the actual machine learning.
- Finally, from matplotlib.pyplot, we will import pandas as pd.
- Now, press Shift + Enter, and make sure that all of the arguments import.
You may get a deprecation warning, as shown in the preceding screenshot. That is because some of these packages are getting old.
- Now that we have all of our packages set up, we can move on to loading the dataset. This is where we're going to be getting our information from. We're going to be using the UCI repository, since they have a large collection of datasets for machine learning, and they're free and available for everybody to use.
- The URL that we're going to use can be imported directly, if we type the whole URL. This is going to import our dataset with 11 different columns. We can see the URL and the various columns in the following screenshot:
We will then import the cell data. This will include the following aspects:
- The first column will simply be the ID of the cell
- In the second column, we will have clump_thickness
- In the third column, we will have uniform_cell_size
- In the fourth column, we will have uniform_cell_shape
- In the fifth column, we will have marginal_adhesion
- In the sixth column, we will have signle_epithelial_size
- In the seventh column, we will have bare_nuclei
- In the eighth column, we will have bland_chromatin
- In the ninth column, we will have normal_nucleoli
- In the tenth column, we will have mitoses
- And finally, in the eleventh column, we will have class
These are factors that a pathologist would consider to determine whether or not a cell had cancer. When we discuss machine learning in healthcare, it has to be a collaborative project between doctors and computer scientists. While a doctor can help by indicating which factors are important to include, a computer scientist can help by carrying out machine learning. Now, let's move on to the next steps:
- Since we've got the names of our columns, we will now start a DataFrame.
- The next step will be to add pd, which stands for pandas. We're going to use the function read_csv_url, which means that the names will be equal to those listed previously.
- Press Shift + Enter, and make sure that all of the imports are right.
- We will then have to preprocess our data and carry out some visualizations, as we want to explore the dataset before we begin.
In machine learning, it's very important to understand the data that you're going to be using. This will help you pick which algorithm to use, and understand which results you're actually looking for. It is important to understand, for example, what is considered a good result, because accuracy is not always the most important classification metric. Take a look at the following steps:
- First, our dataset contains some missing data. To deal with this, we will add a df.replace method.
- If df.replace gives us a question mark, it means that there's no data there. We're simply going to input the value -99999 and tell Python to ignore that data.
- We will then perform the print(df.axes) operation, so that we can see the columns. We can see that we have 699 different data points, and each of those cases has 11 different columns.
- Next, we will print the shape of the dataset using the print(df.shape) operation.
We will drop the Id class, as we don't want to carry out machine learning on the ID column. That is because it won't tell us anything interesting.
Let's view the output of the preceding steps in the following screenshot:
As we now have all of the columns, we can detect whether the tumor is benign (which means it is non-cancerous) or malignant (which means it is cancerous). We now have 10 columns, as we have dropped the ID column.
In the following screenshot, we can see the first cell in our dataset, as well as its different features:
Now let's visualize the parameters of the dataset, in the following steps:
- We will print the first point, so that we can see what it entails.
- We have a value of between 0 and 10 in all of the different columns. In the class column, the number 2 represents a benign tumor, and the number 4 represents a malignant tumor. There are 699 cells in the datasets.
- The next step will be to do a print.describe operation, which gives us the mean, standard deviation, and other aspects for each of our different parameters or features. This is shown in the following screenshot:
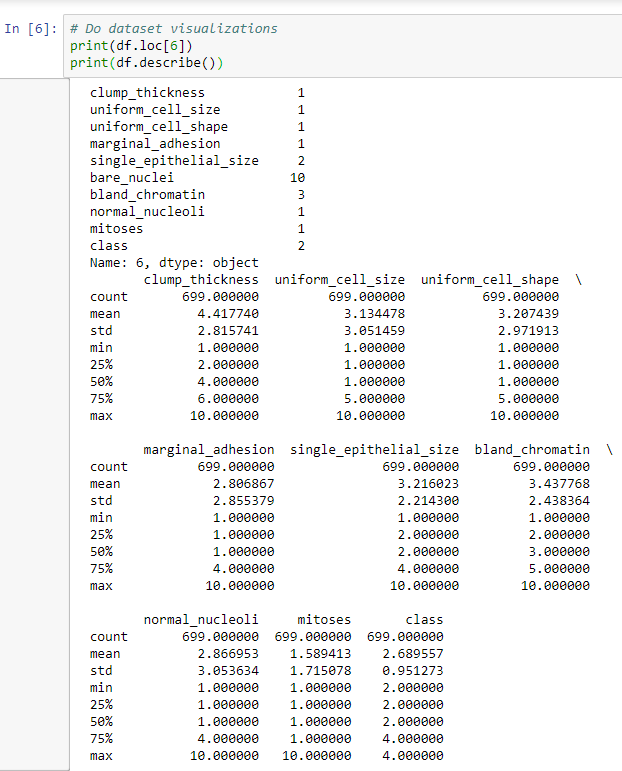
Here, we have a max value of 10 for all of the different columns, apart from the class column, which will either be 2 or 4. The mean is a little closer to 2, so we have a few more benign cases than we do malignant cases. Because the min and the max values are between 1 and 10 for all columns, it means that we've successfully ignored the missing data, so we're not factoring that in. Each column has a relatively low mean, but most of them have a max of 10, which means that we have a case where we hit 10 in all but one of the classes.

 Germany
Germany
 Slovakia
Slovakia
 Canada
Canada
 Brazil
Brazil
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 United States
United States
 Great Britain
Great Britain
 India
India
 Spain
Spain
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 France
France
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Australia
Australia
 Japan
Japan
 Russia
Russia





















