The wonderful idea behind the previously mentioned pipeline is that the find producer and the xargs consumer don't know each other. That is, you could compose any filters using pipes. This is the celebrated pipes and filters design pattern in action. The shell command line gives you a framework that enables you to compose any filters together into a pipeline.
What does it give us? You can reuse the same filter in unexpected and creative ways to get your work done. Each filter just needs to follow a simple protocol of accepting input on file descriptor 0, writing output to file descriptor 1, and writing errors to descriptor 2.
You can refer to a UNIX shell programming guide for more information on descriptors and related ideas. My personal favorite is UNIX Power Tools, 3rd Ed. by Jerry Peek et al.
Flow control means we are trying to regulate the flow of something. When you tell someone to talk slowly so that you can follow their meaning, you are trying to control the flow of words.
Flow control is essential in ensuring that the producer (such as a fast speaker) does not overwhelm the consumer (such as a listener). In the example we have been working on, the find process could produce filenames faster; the egrep process might need more time to process each file. The find producer works at its own pace, and does not care about a slow consumer.
If the pipe gets full because of the slower consumption by xargs, the output call by find is blocked; that is, the process is waiting, and so it can't run. This pauses find until the consumer has finally found the time to consume some filenames and the pipe has some free space. It works the other way around as well. A fast consumer blocks an empty pipe. Blocking is a process-level mechanism, and find (or any other filter) does not know it is blocking or unblocking.
The moment a process starts running, it will perform its computation for the find filter, ferret out some filenames, and output these to the console. Here is a simplified state diagram , showing a process's life cycle:
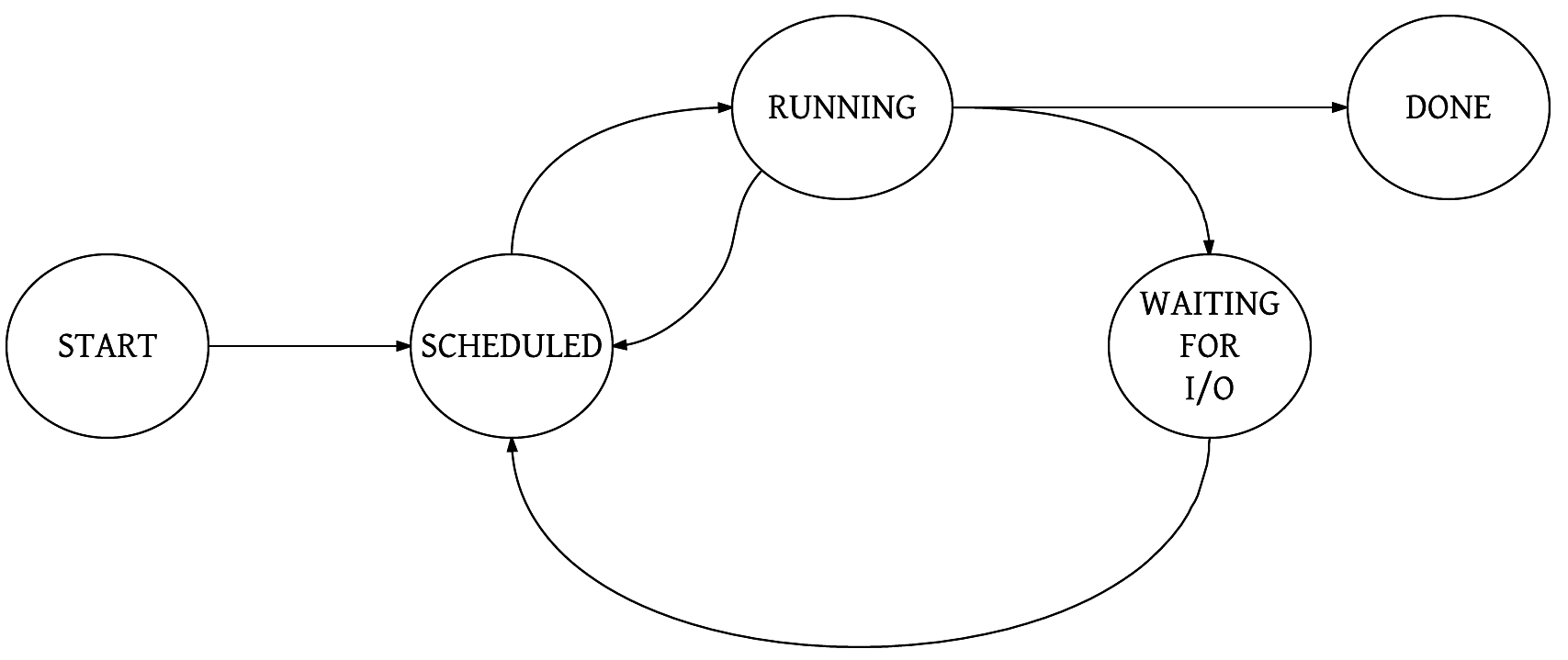
What is this scheduled state? As mentioned, a running process could get blocked waiting for some I/O to happen, and thus it cannot use the CPU. So it is put on the back burner for a while, and other processes, waiting their turn, are given a chance to run. Drawing a parallel with the previously mentioned receptionist scenario, the receptionist can ask us to be seated and wait a while, and then move on to the next guest in the queue.
The other idea is that the process has run its allocated slice of time, so other processes should now get a chance, too. In this case, even though the process can run and utilize the CPU, it is moved back to the scheduled state, and can run again once other processes have used their run slices. This is preemptive multitasking we have here, which makes it a fair world to live in! Processes need to run so that useful work can happen. Preemptive scheduling is an idea to help each process get a slice of CPU time.
However, there is another notion that could throw a spanner into this scheme of things. A process with a higher priority is given preference over lower priority processes.
A real-world example should help make this clear. While driving on roads, when we see an ambulance or a police car with a screaming siren, we are required to make way for them. Similarly, a process executing a piece of business logic may need more priority than the data backup process.

 Germany
Germany
 Slovakia
Slovakia
 Canada
Canada
 Brazil
Brazil
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 United States
United States
 Great Britain
Great Britain
 India
India
 Spain
Spain
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 France
France
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Australia
Australia
 Japan
Japan
 Russia
Russia




















