






















































The popularity of data science has skyrocketed since it was called The Sexiest Job of the 21st Century by the Harvard Review in 2012. It was ranked as the number one job by Glassdoor in both 2016 and 2017. Fueling this skyrocketing popularity for data science is the demand from industry. Several applications have made big splashes in the news, such as Netflix making better movie recommendations, IBM Watson defeating humans at Jeopardy, Tesla building self-driving cars, Major League Baseball teams finding undervalued prospects, and Google learning to identify cats on the internet.
Nearly every industry is finding ways to use data science to build new technology or provide deeper insights. Due to such noteworthy successes, an ever-present aura of hype seems to encapsulate data science. Most of the scientific progress backing this hype stems from the field of machine learning, which produces the algorithms that make the predictions responsible for artificial intelligence.
The fundamental building block for all machine learning algorithms is, of course, data. As companies have realized this, there is no shortage of it. The business intelligence company, Domo, estimates that 90% of the world's data has been created in just the last two years. Although machine learning gets all the attention, it is completely reliant on the quality of the data that it is fed. Before data ever reaches the input layers of a machine learning algorithm, it must be prepared, and for data to be prepared properly, it needs to be explored thoroughly for basic understanding and to identify inaccuracies. Before data can be explored, it needs to be captured.
To summarize, we can cast the data science pipeline into three stages--data capturing, data exploration, and machine learning. There are a vast array of tools available to complete each stage of the pipeline. Pandas is the dominant tool in the scientific Python ecosystem for data exploration and analysis. It is tremendously capable of inspecting, cleaning, tidying, filtering, transforming, aggregating, and even visualizing (with some help) all types of data. It is not a tool for initially capturing the data, nor is it a tool to build machine learning models.
For many data analysts and scientists who use Python, the vast majority of their work will be done using pandas. This is likely because the initial data exploration and preparation tend to take the most time. Some entire projects consist only of data exploration and have no machine learning component. Data scientists spend so much time on this stage that a timeless lore has arisen--Data scientists spend 80% of their time cleaning the data and the other 20% complaining about cleaning the data.
Although there is an abundance of open source and free programming languages available to do data exploration, the field is currently dominated by just two players, Python and R. The two languages have vastly different syntax but are both very capable of doing data analysis and machine learning. One measure of popularity is the number of questions asked on the popular Q&A site, Stack Overflow (https://insights.stackoverflow.com/trends):
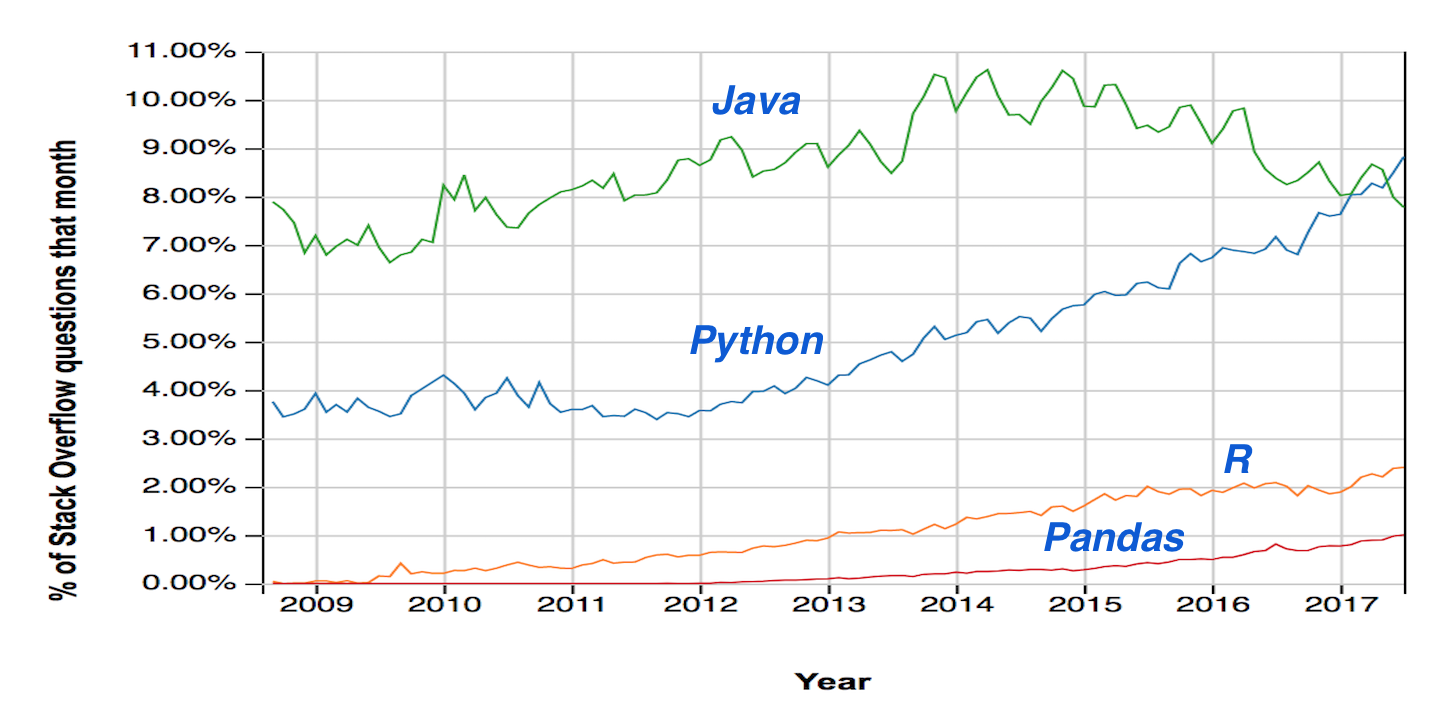
While this is not a true measure of usage, it is clear that both Python and R have become increasingly popular, likely due to their data science capabilities. It is interesting to note that the percentage of Python questions remained constant until the year 2012, when data science took off. What is probably most astonishing about this graph is that pandas questions now make up a whopping one percent of all the newest questions on Stack Overflow.
One of the reasons why Python has become a language of choice for data science is that it is a fairly easy language to learn and develop, and so it has a low barrier to entry. It is also free and open source, able to run on a variety of hardware and software, and a breeze to get up and running. It has a very large and active community with a substantial amount of free resources online. In my opinion, Python is one of the most fun languages to develop programs with. The syntax is so clear, concise, and intuitive but like all languages, takes quite a long time to master.
As Python was not built for data analysis like R, the syntax may not come as naturally as it does for some other Python libraries. This actually might be part of the reason why there are so many Stack Overflow questions on it. Despite its tremendous capabilities, pandas code can often be poorly written. One of the main aims of this book is to show performant and idiomatic pandas code.
For all its greatness, Stack Overflow, unfortunately perpetuates misinformation and is a source for lots of poorly written pandas. This is actually not the fault of Stack Overflow or its community. Pandas is an open source project and has had numerous major changes, even recently, as it approaches its tenth year of existence in 2018. The upside of open source, though, is that new features get added to it all the time.
The recipes in this book were formulated through my experience working as a data scientist, building and hosting several week-long data exploration bootcamps, answering several hundred questions on Stack Overflow, and building tutorials for my local meetup group. The recipes not only offer idiomatic solutions to common data problems, but also take you on journeys through many real-world datasets, where surprising insights are often discovered. These recipes will also help you master the pandas library, which will give you a gigantic boost in productivity. There is a huge difference between those who have only cursory knowledge of pandas and those who have it mastered. There are so many interesting and fun tricks to solve your data problems that only become apparent if you truly know the library inside and out. Personally, I find pandas to be a delightful and fun tool to analyze data with, and I hope you enjoy your journey along with me. If you have questions, please feel free to reach out to me on Twitter: @TedPetrou.



