






















































In this section, we'll walk through some of the AI techniques commonly used in different types of games. We'll learn how to implement each of these features in Unity in the upcoming chapters. Since this book is not focused on AI techniques themselves, but the implementation of these techniques inside Unity, we won't go into too much detail about these techniques here. So, let's just take it as a crash course, before actually going into implementation. If you want to learn more about AI for games, there are some really great books out there, such as Programming Game AI by Example by Mat Buckland and Artificial Intelligence for Games by Ian Millington and John Funge. The AI Game Programming Wisdom and Game AI Pro series also contain a lot of useful resources and articles on the latest AI techniques.
AI techniques
Finite State Machines (FSMs)
Finite State Machines (FSMs) are one of the simplest AI model forms and are commonly used in the majority of games. A state machine consists of a finite number of states that are connected in a graph by the transitions between them. A game entity starts with an initial state and then looks out for the events and rules that will trigger a transition to another state. A game entity can only be in exactly one state at any given time.
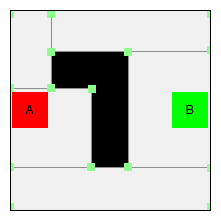
For example, let's take a look at an AI guard character in a typical shooting game. Its states could be as simple as patrolling, chasing, and shooting:

There are four components in a simple FSM:
- States: This component defines a set of states that a game entity or an NPC can choose from (Patrol, Chase, and Shoot)
- Transitions: This component defines relations between different states
- Rules: This component is used to trigger a state transition (player on sight, close enough to attack, and lost/killed player)
- Events: This is the component that will trigger to check the rules (guard's visible area, distance with the player, and so on)
So, a monster in Quake 2 might have the following states: standing, walking, running, dodging, attacking, idle, and searching.
FSMs are widely used in game AI because they are simple to implement and more than enough for both simple and somewhat complex games. Using simple if/else statements or switch statements, we can quickly implement an FSM. On the other hand, they can get messy when we start to have a lot of states and transitions. We'll look at how to manage a simple FSM in the next chapter.
Random and probability in AI
Imagine an enemy bot in a First Person Shooter (FPS) game that can always kill the player with a headshot, an opponent in a racing game that always chooses the best route and overtakes without collision with any obstacle. Such a level of intelligence will make the game so hard that it becomes almost impossible to win and thus frustrating. On the opposite side of the spectrum, imagine an AI enemy that always chooses the same route when it tries to escape from or attack the player. AI controlled entities behaving the same way every time the player encounters them, make the game predictable, easy to win, and therefore boring.
Both of the previous situations affect the fun aspect of the game and make the player feel like the game is not challenging or fair enough anymore. One way to fix this sort of perfect AI and stupid AI is to introduce some intentional mistakes in their behavior. In games, randomness and probabilities are applied in the decision-making process of AI calculations. The following are the main situations when we would want to let our AI take a random decision:
- Non-intentional: In some situations, an NPC might need to make a decision randomly, just because it doesn't have enough information to make a perfect decision, and/or it doesn't really matter what decision it makes. Just making a decision randomly and hoping for the best result is a perfect solution in many real-world situations.
- Intentional: As we discussed in the previous examples, we will need to add some randomness purposely to make them more realistic, and also to match a difficulty level that suits the player. We can use randomness for things such as hit probabilities, add or subtract a certain random damage on top of base damage, or make an NPC hesitate before start shooting. Using randomness and probability, we can add a sense of realistic uncertainty to our game and make our AI system more fair and/or unpredictable.
The sensor system
Our AI characters need to know about their surroundings and the world they are interacting with in order to make a particular decision. Such information may be the following:
- The position of the player: This is used to decide whether to attack or chase, or keep patrolling
- Buildings and objects nearby: This is used to hide or take cover
- Player's health and its own health: This is used to decide whether to retreat or advance
- Location of resources on the map in a Real-Time Strategy game (RTS): This is used to occupy and collect resources required for updating and/or producing other units
As you can see, choosing the right method to collect game information can vary a lot depending on the type of game we are trying to build. In the following sections, we look at two basic strategies: polling and message (event) systems.
Polling
One method to collect such information is polling. Polling consists of directly checking for the preceding information in the FixedUpdate method of our AI character. An AI character can just poll the information they are interested in from the game world, do the checks, and take action accordingly. Polling works great if there aren't too many things to check. To make this method more efficient, we may program some characters to poll the world states with different polling rates so that we do not stop polling at every frame for every character. However, as soon as the game gets bigger, polling is not enough anymore. Therefore, in more massive games with more complex AI systems, we need to deploy an event-driven method using a global messaging system.
The messaging system
AI does decision making in response to the events in the world. The events are communicated between the AI entity and the player, the world, or the other AI entities through a messaging system. For example, when the player attacks an enemy unit from a group of patrol guards, the other AI units need to know about this incident as well, so that they can start searching for and attacking the player. If we were using the polling method, our AI entities would need to check the state of all of the other AI entities to know about this incident. However, with an event-driven messaging system, we can implement this in a more manageable and scalable way. We can register the AI characters interested in a particular event as listeners, and if that event happens, our messaging system will broadcast to all listeners. The AI entities can then proceed to take appropriate actions or perform further checks.
The event-driven system does not necessarily provide a faster mechanism than polling. Still, it provides a convenient, central checking system that senses the world and informs the interested AI agents, rather than each agent having to check the same event in every frame. In reality, both polling and messaging systems are used together most of the time. For example, AI might poll for more detailed information when it receives an event from the messaging system.
Flocking, swarming, and herding
Many living beings such as birds, fish, insects, and land animals perform specific operations such as moving, hunting, and foraging in groups. They stay and hunt in groups because it makes them stronger and safer from predators than pursuing goals individually. So, let's say you want a group of birds flocking, swarming around in the sky; it'll cost too much time and effort for animators to design the movement and animations of each bird. However, if we apply some simple rules for each bird to follow, we can achieve the emergent intelligence of the whole group with complex, global behavior.
One pioneer of this concept is Craig Reynolds, who presented such a flocking algorithm in his 1987 SIGGRAPH paper, Flocks, Herds, and Schools – A Distributed Behavioral Model. He coined the term boid that sounds like bird, but refer to a bird-like object. He proposed three simple rules to apply to each unit:
- Separation: Each boid needs to maintain a minimum distance with neighboring boids to avoid hitting them (short-range repulsion)
- Alignment: Each boid needs to align itself with the average direction of its neighbors, and then move in the same velocity with them as a flock
- Cohesion: Each boid is attracted to the group's center of mass (long-range attraction)
These three simple rules are all that we need to implement a realistic and a reasonably complex flocking behavior for birds. We can also apply them to group behaviors of any other entity type with little or no modifications. We'll examine how to implement such a flocking system in Unity in Chapter 5, Flocking.
Path following and steering
Sometimes we want our AI characters to roam around in the game world, following a roughly guided or thoroughly defined path. For example, in a racing game, the AI opponents need to navigate on the road, and the simple reactive algorithms, such as our flocking boid algorithm discussed already, are not powerful enough to solve this problem. Still, in the end, it all comes down to dealing with actual movements and steering behaviors. Steering behaviors for AI characters have been in research topics for a couple of decades now. One notable paper in this field is Steering Behaviors for Autonomous Characters, again by Craig Reynolds, presented in 1999 at the Game Developers Conference (GDC). He categorized steering behaviors into the following three layers:
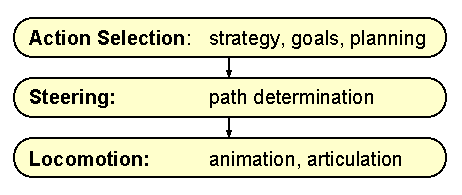
Let me quote the original example from his paper to understand these three layers:
Consider, for example, some cowboys tending a herd of cattle out on the range. A cow wanders away from the herd. The trail boss tells a cowboy to fetch the stray. The cowboy says giddy-up to his horse, and guides it to the cow, possibly avoiding obstacles along the way. In this example, the trail boss represents action selection, noticing that the state of the world has changed (a cow left the herd), and setting a goal (retrieve the stray). The steering level is represented by the cowboy who decomposes the goal into a series of simple sub goals (approach the cow, avoid obstacles, and retrieve the cow). A sub-goal corresponds to a steering behavior for the cowboy-and-horse team. Using various control signals (vocal commands, spurs, and reins), the cowboy steers his horse towards the target. In general terms, these signals express concepts such as go faster, go slower, turn right, turn left, and so on. The horse implements the locomotion level. Taking the cowboy's control signals as input, the horse moves in the indicated direction. This motion is the result of a complex interaction of the horse's visual perception, its sense of balance, and its muscles applying torque to the joints of its skeleton.
Then he presented how to design and implement some common and straightforward steering behaviors for individual AI characters and pairs. Such behaviors include seek and flee, pursue, and evade, wander, arrival, obstacle avoidance, wall following, and path following. We'll implement some of those behaviors in Unity in Chapter 6, Path Following and Steering Behaviors.
A* pathfinding
There are many games where you can find monsters or enemies that follow the player or go to a particular point while avoiding obstacles. For example, let's take a look at a typical RTS game. You can select a group of units and click a location where you want them to move or click on the enemy units to attack them. Your units then need to find a way to reach the goal without colliding with the obstacles. The enemy units also need to be able to do the same. Obstacles could be different for different units. For example, an air force unit might be able to pass over a mountain, while the ground or artillery units need to find a way around it.
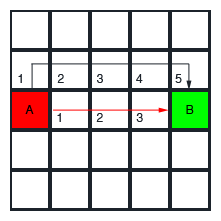
A * (pronounced A star) is a pathfinding algorithm widely used in games because of its performance, accuracy, and ease of implementation. Let's take a look at an example to see how it works. Let's say we want our unit to move from point A to point B, but there's a wall in the way, and it can't go straight towards the target. So, it needs to find a way to point B while avoiding the wall:

We are looking at a simple 2D example, but we can apply the same idea to 3D environments. In order to find the path from point A to point B, we need to know more about the map, such as the position of obstacles. For that, we can split our whole map into small tiles representing the whole map in a grid format, as shown in the following diagram:

The tiles can also be of other shapes such as hexagons and triangles, but we'll use square tiles here because they are the most natural solution. By representing the whole map as a grid, we simplify the search area: an important step in pathfinding.
We can now reference our map in a small 2D array.
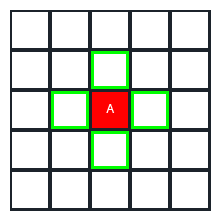
We represent our map with a 5 x 5 grid of square tiles for a total of 25 tiles. Now, we can start searching for the best path to reach the target. How do we do this? By calculating the movement score of each tile adjacent to the starting tile that is not occupied by an obstacle, and then choosing the tile with the lowest cost.
If we don't consider the diagonal movements, there are four possible adjacent tiles to the player. Now, we need to know two numbers to calculate the movement score for each of those tiles. Let's call them G and H, where G is the cost to move from starting tile to current tile, and H is the estimated cost to reach the target tile from the current tile.
Let's call F the sum of G and H, (F = G + H); that is the final score of that tile:
In our example, to estimate H, we'll be using a simple method called Manhattan length (also known as taxicab geometry). According to this method, the distance (cost) between tiles A and B is just the minimum number of tiles between A and B:
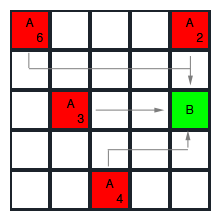
The G value, instead, represents the cost so far during the search. The preceding diagram shows the calculations of G with two different paths. To compute the current G, we just add one (which is the cost to move one tile) to the previous tile's G score. However, we can give different costs to different tiles. For example, we might want to give a higher movement cost for diagonal movements (if we are considering them), or to specific tiles occupied by, let's say a pond or a muddy road.
Now we know how to get G. Let's look at the calculation of H. The following diagram shows different H values from different starting tiles to the target tile. As we said before, we are just computing the Manhattan length between the current tile and the goal:
So, now we know how to get G and H. Let's go back to our original example to figure out the shortest path from A to B. We first choose the starting tile, and then determine the valid adjacent tiles, as shown in the following diagram. Then we calculate the G and H scores of each tile, shown in the lower left and right corners of the tile respectively. Therefore the final score F, which is G + H is shown at the top-left corner. Obviously, the tile to the immediate right of the start tile has got the lowest F score.
So, we choose this tile as our next movement and store the previous tile as its parent. Keeping records of parents will be useful later when we trace back our final path:
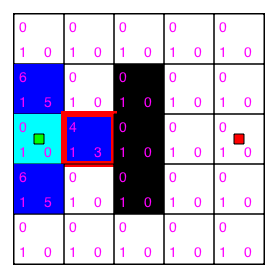
From the current tile, we do the similar process again, determining valid adjacent tiles. This time there are only two valid adjacent tiles at the top and bottom. The left tile is the starting tile—which we've already examined—and the obstacle occupies the right tile. We calculate the G, the H, and then the F score of those new adjacent tiles. This time we have four tiles on our map with all having the same score: six. So, which one do we choose? We can choose any of them. It doesn't really matter in this example, because we'll eventually find the shortest path with whichever tile we choose as long they have the same score. Usually, we simply choose the tile added most recently to our adjacent list. Later we'll be using a data structure, such as a list, to store the next move candidate tiles. So, accessing the tile most recently added to that list could be faster than searching through the list to reach a particular tile that was added previously.
In this demo, we'll randomly choose the tile for our next test, to prove that it can still find the shortest path:

So, we choose the tile highlighted with a red border. Again, we examine the adjacent tiles. In this step, there's only one new adjacent tile with a calculated F score of 8. So, the lowest score right now is still 6. We can choose any tile with the score 6:
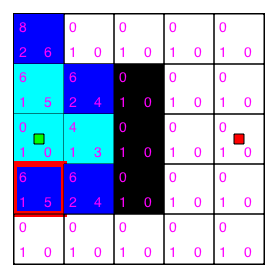
So, we choose a tile randomly from all the tiles with the score 6. If we repeat this process until we reach our target tile, we'll end up with a board complete with all the scores for each valid tile:

Now, all we have to do is to trace back starting from the target tile using its parent tile. In the end, we obtain a path that looks something like the following diagram:

What we explained here is the essence of A* pathfinding without displaying any code. A* is a central concept in pathfinding. Fortunately, since Unity 3.5, there are a couple of new features such as automatic navigation mesh generation and the Nav Mesh Agent, which make implementing pathfinding in your games very much more accessible. In fact, you may not even need to know about A* to implement pathfinding for your AI characters. Nonetheless, knowing how the system is working behind the scenes is essential to becoming a solid AI programmer.
We'll talk about Nav Mesh roughly in the next section and then in more detail in Chapter 8, Navigation Mesh.
A navigation mesh
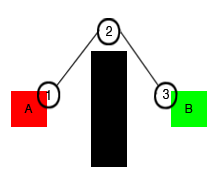
Now we have some idea of A* pathfinding techniques. One thing that you might notice is that using a simple grid in A* requires quite a few computations steps to get a path which is the shortest to the target and at the same time avoids the obstacles. It may not seem notable, but for huge maps with thousands of tiles, searching for a path tile-by-tile in a mostly empty map is a severe waste of computational power. So, to make it cheaper and faster for AI characters to find a path, people came up with the idea of using waypoints as a guide to move AI characters from the start point to the target point. Let's say we want to move our AI character from point A to point B, and we've set up three waypoints, as shown in the following diagram:
All we have to do now is to pick up the nearest waypoint, and then follow its connected node leading to the target waypoint. Most of the games use waypoints for pathfinding because they are simple and quite effective in using fewer computation resources. However, they do have some issues. What if we want to update the obstacles in our map? We'll also have to place waypoints for the updated map again, as shown in the following diagram:
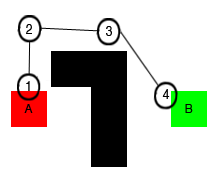
Following each node to the target can mean the AI character moves in zigzag directions. Look at the preceding diagrams; it's quite likely that the AI character will collide with the wall where the path is close to the wall. If that happens, our AI will keep trying to go through the wall to reach the next target, but it won't be able to, and it will get stuck there. Even though we can smooth out the zigzag path by transforming it to a spline and make some adjustments to avoid such obstacles, the problem is the waypoints don't give any information about the environment, other than the spline connects between two nodes. What if our smoothed and adjusted path passes the edge of a cliff or a bridge? The new path might not be a safe path anymore. So, for our AI entities to be able to traverse the whole level effectively, we're going to need a tremendous number of waypoints, which is very hard to implement and manage.
Let's look at a better solution, navigation mesh. A navigation mesh is another graph structure that can be used to represent our world, similar to the way we did with our square tile-based grid or waypoints graph:
A navigation mesh uses convex polygons to represent the areas in the map that an AI entity can travel. The most important benefit of using a navigation mesh is that it gives a lot more information about the environment than a waypoint system. Now we can adjust our path safely because we know the safe region in which our AI entities can travel. Another advantage of using a navigation mesh is that we can use the same mesh for different types of AI entities. Different AI entities can have different properties such as size, speed, and movement abilities. For instance, a set of waypoints may be tailored for human, and they may not work nicely for flying creatures or AI controlled vehicles. Those might need different sets of waypoints. Using a navigation mesh can save a lot of time in such cases.
However, programmatically generating a navigation mesh based on a scene is a somewhat complicated process. Fortunately, Unity includes a built-in navigation mesh generator. Since this is not a book on core AI techniques, we won't go too much into how to generate and use such navigation meshes. Instead, we'll learn how to use Unity's navigation mesh for generating features to implement our AI pathfinding efficiently.
The behavior trees
Behavior trees are the other techniques used to represent and control the logic behind AI characters. They have become popular for the applications in AAA games such as Halo and Spore. Previously, we have briefly covered FSMs. FSMs provide a straightforward way to define the logic of an AI character, based on the different states and transitions between them. However, FSMs are considered challenging to scale and reuse. To support all the scenarios which we want our AI character to consider, we need to add many states and hardwire many transitions. So, we need a more scalable approach when dealing with more extensive problems. Behavior trees are a better way to implement AI game characters that could potentially become more and more complex.
The basic elements of behavior trees are tasks, where states are the main elements for FSMs. Tasks are linked together by control flow nodes in a tree-like structure. There are many commonly used nodes such as Sequence, Selector, and Parallel Decorator while tasks are the leaves of the tree. For example, let's try to translate our example from the FSM section using a behavior tree. We can break all the transitions and states into basic tasks:
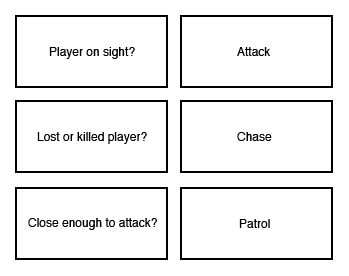
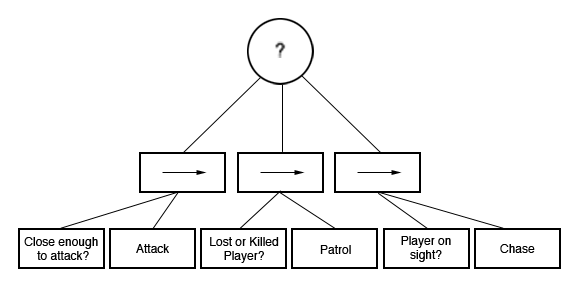
Let's look at a Selector node for this behavior tree. Selector nodes usually are represented with a circle and a question mark inside. A Selector node tries to execute all the child tasks/sub-trees in order until one of them succeeds. First, it'll choose to attack the player. If the Attack task returns success, the Selector node is completed, and it goes back to the parent node—if there is one. If the Attack task fails, it'll try the Chase task. Finally, if the Chase task fails, it'll try the Patrol task:

What about the tests? They are also one of the tasks in the behavior trees. The following diagram shows the use of Sequence nodes, denoted by a rectangle with an arrow inside it. The root Selector starts with the first Sequence action. This Sequence action's first task is to check whether the player character is close enough to attack. If this task succeeds, it'll proceed with the next task, which is to attack the player. If the Attack task also returns success, the whole Sequence returns success, and the Selector is done with this behavior, and it does not continue with other Sequence nodes. If the Close enough to attack? task fails, then the Sequence action does not proceed to the Attack task and returns a failed status to the parent Selector node. Then the Selector chooses the next task in the Sequence, Lost or Killed Player:
The other two common nodes are Parallel and Decorator. A Parallel node executes all of its child tasks at the same time, while the Sequence and Selector nodes only execute their child tasks one by one. A Decorator is another type of node that has only one child. It can change the behavior of its own child's tasks, which includes whether to run its child's task or not, how many times it should run, and so on.
We'll look into more details and study how to implement a basic behavior tree system in Unity in Chapter 9, Behavior Trees.
Locomotion
Animals (including humans) have a very complex musculoskeletal system (the locomotor system) that gives them the ability to move around the body using the muscular and skeletal systems. We know where to put our steps when climbing a ladder, stairs, or on uneven terrain, and we know how to balance our body to stabilize all the fancy poses we want to make. We can do all this using our bones, muscles, joints, and other tissues, collectively described as our locomotor system.
Now, put that into our game development perspective. Let's say we have a human character who needs to walk on both even and uneven surfaces, or on small slopes, and we have only one animation for a walk cycle. With the lack of a locomotor system in our virtual character, this is how it would look:

First, we play the walk animation and advance the player forward. Now the character knows it's penetrating the surface. So, the collision detection system pulls the character up above the surface to prevent this penetration. This is how we usually set up the movement on an uneven surface. Even though it doesn't give a realistic look and feel, it does the job and is cheap to implement.
Let's take a look at how we walk upstairs in reality. We put our step firmly on the staircase and using this force, we pull up the rest of our body for the next step. This is how we do it in real life with our advanced locomotor system. However, it's not so simple to implement this level of realism inside games. We'll need a lot of animations for different scenarios, which include climbing ladders, walking/running upstairs, and so on. So, only the large studios with a lot of animators could pull this off in the past, until we came up with an automated system:
Fortunately, Unity 3D has an extension that can do just that:

This system can automatically blend our animated walk/run cycles, and adjust the movements of the bones in the legs to ensure that the feet step correctly on the ground. It can also adjust the original animations made for a specific speed and direction on any surface, arbitrary steps, and slopes. We'll see how to use this locomotion system to apply realistic movement to our AI characters in a later chapter.






