






















































Approaching low-latency application development in C++
In this section, we will discuss the higher-level ideas to keep in mind when trying to build low-latency applications in C++. Overall, the ideas are to understand the architecture that your application runs on, your application use cases that are latency-sensitive, the programming language of your choice (C++ in this case), how to work with the development tools (the compiler, linker, etc.) and how to measure application performance in practice to understand which parts of the application to optimize first.
Coding for correctness first, optimizing second
For low-latency applications, correct behavior of the application under different use cases and scenarios and robust handling of edge conditions is still the primary focus. A fast application that does not do what we need is useless, so the best approach when it comes to developing a low-latency application is to first code for correctness, not speed. Once the application works correctly, only then the focus should be shifted to optimizing the critical parts of the application while maintaining correctness. This ensures that developers spend time focusing on the correct parts to optimize because it is common to find that our intuition on which pieces are critical to performance does not match what happens in practice. Optimizing the code can also take significantly longer than coding for correctness, so it is important to optimize the most important things first.
Designing optimal data structures and algorithms
Designing custom data structures that are optimal for the application’s use cases is an important part of building low-latency applications. A good amount of thought needs to be put into each data structure used in the critical parts of the application in terms of scalability, robustness, and performance under the use cases and data encountered in practice. It is important to understand why we mention the term in practice here because different data structure choices will perform better under different use cases and input data even if the different data structures themselves have the same output or behavior. Before we discuss an example of different possible data structures and algorithms to solve the same problem, let us quickly review Big-O notation. Big-O notation is used to describe the asymptotic worst-case time complexity of performing a certain task. The term asymptotic here is used to describe the fact that we discuss cases where we measure the performance over a theoretically infinite (in practice an exceptionally large) number of data points. The asymptotic performance eliminates all the constant terms and describes the performance only as a function of the number of input data elements.
A simple example of using different data structures to solve the same problem would be searching for an entry in a container by a key value. We can solve this either by using a hash map implementation that has an expected amortized complexity of O(1) or using an array that has a complexity of O(n), where n is the number of elements in the container. While on paper it might appear that the hash map is clearly the way to go, other factors such as the number of elements, the complexity of applying the hash function to the keys, and so on might change which data structure is the way to go. In this case, for a handful of elements, the array solution is faster due to better cache performance, while for many elements, the hash map solution is better. Here, we chose a suboptimal algorithm because the underlying data structure for the suboptimal algorithm performed better in practice due to cache performance.
Another slightly different example would be using lookup tables over recomputing values for some mathematical functions, say, trigonometric functions. While it makes complete sense that looking up the result in a precomputed lookup table should always be faster compared to performing some calculations, this might not always be true. For instance, if the lookup table is very large, then the cost of evaluating a floating-point expression might be less than the cost of getting a cache miss and reading the lookup table value from the main memory. The overall application performance might also be better if accessing the lookup table from the main memory leads to a lot of cache pollution, leading to performance degradation in other parts of the application code.
Being mindful of the processor
Modern processors have a lot of architectural and functional details that a low-latency application developer should understand, especially a C++ developer since it allows very low-level control. Modern processors have multiple cores, larger and specialized register banks, pipelined instruction processing where instructions needed next are prefetched while executing the current one, instruction level parallelism, branch predictions, extended instruction sets to facilitate faster and specialized processing, and so on. The better the application developer understands these aspects of the processor on which their applications will run, the better they can avoid sub-optimal code and/or compilation choices and make sure that the compiled machine code is optimal for their target architecture. At the very least, the developer should instruct the compiler to output code for their specific target architecture using compiler optimization flags, but we will discuss that topic later in this chapter.
Understanding the cache and memory access costs
Typically, a lot of effort is put into the design and development of data structures and algorithms when it comes to low-latency application development from the perspective of reducing the amount of work done or the number of instructions executed. While this is the correct approach, in this section, we would like to point out that thinking about cache and memory accesses is equally important.
We saw in the previous sub-section, Designing optimal data structures and algorithms, that it is common for data structures and algorithms that are sub-optimal on paper to outperform ones that are optimal on paper. A large reason behind that can be the higher cache and memory access costs for the optimal solution outweighing the time saved because of the reduced number of instructions the processor needs to execute. Another way to think about this is that even though the amount of work from the perspective of the number of algorithmic steps is less, in practice, it takes longer to finish with the modern processor, cache, and memory access architectures today.
Let us quickly review the memory hierarchy in a modern computer architecture. Note that details of what we will recap here can be found in our other book, Developing High-Frequency Trading Systems. The key points here are that the memory hierarchy works in such a way that if the CPU cannot find the data or instruction it needs next in the register, it goes to the L0 cache, and if it cannot find it there, goes to the L1 cache, L2, other caches, and so on, then goes to the main memory in that order. Note that the storage is accessed from fastest to slowest, which also happens to be least amount of space to most amount of space. The art of effective low-latency and cache-friendly application development relies on writing code that is cognizant of code and data access patterns to maximize the likelihood of finding data in the fastest form of storage possible. This relies on maximizing the concepts of temporal locality and spatial locality. These terms mean that data accessed recently is likely to be in the cache and data next to what we just accessed is likely to be in the cache, respectively. The following diagram visually lays out the register, cache, and memory banks and provides some data on access times from the CPU. Note that there is a good amount of variability in the access times depending on the hardware and the constant improvements being made to technologies. The key takeaway here should be that there is a significant increase in access times as we go from CPU registers to cache banks to the main memory.
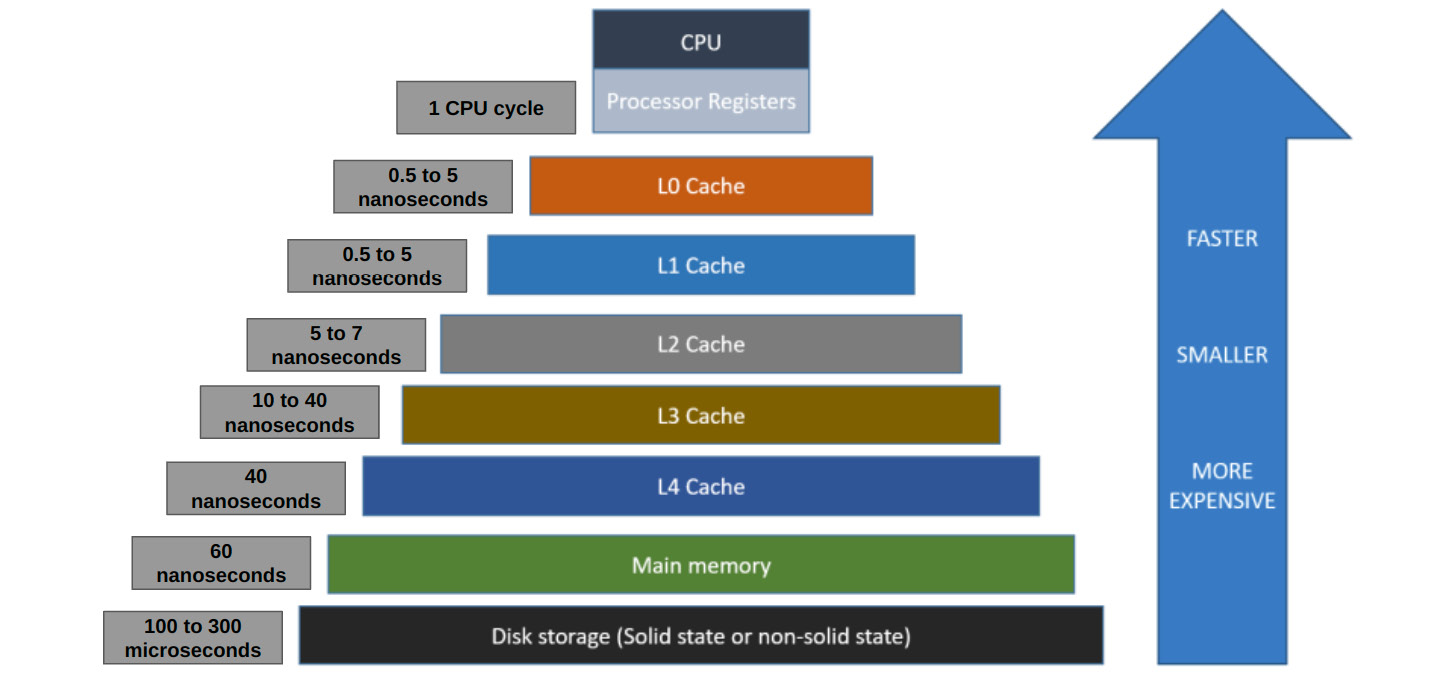
Figure 3.1 – The hierarchy of memory in modern computer architectures.
I would advise you to think carefully about the cache and memory access patterns for the algorithm locally, as well as the entire application globally, to make sure that your source code optimizes cache and memory access patterns, which will boost overall application performance. If you have a function that executes very quickly when it is called but causes a lot of cache pollution, that will degrade the complete application’s performance because other components will incur additional cache miss penalties. In such a case, we have failed in our objective of having an application that performs optimally even though we might have managed to make this function perform optimally locally.
Understanding how C++ features work under the hood
When developing low-latency applications, it is very important that the developers have an extremely good understanding of how the high-level language abstractions work at a lower level or “under the hood.” For applications that are not latency-sensitive, this is perhaps not as important since if the application behaves the way the developer intends it to, the extremely low-level details of how their source code achieves that is not relevant.
For low-latency applications in C++, the more knowledge the developer has of how their program gets compiled into machine code, the better they can use the programming language to achieve low-latency performance. A lot of high-level abstractions available in C++ improve the ease and speed of development, robustness and safety, maintainability, software design elegance, and so on, but not all of them might be optimal when it comes to low-latency applications.
Many C++ features, such as dynamic polymorphism, dynamic memory allocation, and exception handling, are great additions to the language for most applications. However, these are best avoided or used sparingly or used in a specific manner when it comes to low-latency applications since they have larger overheads.
Conversely, traditional programming practices suggest the developer break everything down into numerous very small functions for reusability; use recursive functions when applicable; use Object-Oriented Programming (OOP) principles, such as inheritance and virtual functions; always use smart pointers instead of raw pointers; and so on. These principles are sensible for most applications, but for low-latency applications, these need to be evaluated and used carefully because they might add non-trivial amounts of overhead and latency.
The key takeaway here is that it is important for low-latency application developers to understand each one of these C++ features very well to understand how they are implemented in machine code and what impact they have on the hardware resources and how they perform in practice.
Leveraging the C++ compiler
The modern C++ compiler is truly a fascinating piece of software. There is an immense amount of effort invested into building these compilers to be robust and correct. A lot of effort is also made to make them very intelligent in terms of the transformations and optimizations they apply to the developer’s high-level source code. Understanding how the compiler translates the developer’s code into machine instructions, how it tries to optimize the code, and when it fails is important for low-latency application developers looking to squeeze as much performance out of their applications as possible. We will discuss the workings of the compiler and optimization opportunities extensively in this chapter so that we can learn to work with the compiler instead of against it when it comes to optimizing our final application’s representation (machine code executable).
Measuring and improving performance
We mentioned that the ideal application development journey involves first building the application for correctness and then worrying about optimizing it after that. We also mentioned that it is not uncommon for a developer’s intuition to be incorrect when it comes to identifying performance bottlenecks.
Finally, we also mentioned that the task of optimizing an application can take significantly longer than the task of developing it to perform correctly. For that reason, it is advisable that before embarking on an optimization journey, the developer try to run the application under practical constraints and inputs to check performance. It is important to add instrumentation to the application in different forms to measure the performance and find bottlenecks to understand and prioritize the optimization opportunities. This is also an important step since as the application evolves, measuring and improving performance continues to be part of the workflow, that is, measuring and improving performance is a part of the application’s evolution. In the last section of this book, Analyzing and improving performance, we will discuss this idea with a real case study to understand this better.



