






















































Chapter 2. Functions, Closures, and Modules
In the previous chapter, we deliberately did not discuss certain aspects of JavaScript. These are some of the features of the language that give JavaScript its power and elegance. If you are an intermediate- or advanced-level JavaScript programmer, you may be actively using objects and functions. In many cases, however, developers stumble at these fundamental levels and develop a half-baked or sometimes wrong understanding of the core JavaScript constructs. There is generally a very poor understanding of the concept of closures in JavaScript, due to which many programmers cannot use the functional aspects of JavaScript very well. In JavaScript, there is a strong interconnection between objects, functions, and closures. Understanding the strong relationship between these three concepts can vastly improve our JavaScript programming ability, giving us a strong foundation for any type of application development.
Functions are fundamental to JavaScript. Understanding functions in JavaScript is the single most important weapon in your arsenal. The most important fact about functions is that in JavaScript, functions are first-class objects. They are treated like any other JavaScript object. Just like other JavaScript data types, they can be referenced by variables, declared with literals, and even passed as function parameters.
As with any other object in JavaScript, functions have the following capabilities:
- They can be created via literals
- They can be assigned to variables, array entries, and properties of other objects
- They can be passed as arguments to functions
- They can be returned as values from functions
- They can possess properties that can be dynamically created and assigned
We will talk about each of these unique abilities of a JavaScript function in this chapter and the rest of the book.
A function literal
One of the most important concepts in JavaScript is that the functions are the primary unit of execution. Functions are the pieces where you will wrap all your code, hence they will give your programs a structure.
JavaScript functions are declared using a function literal.
Function literals are composed of the following four parts:
- The function keyword.
- An optional name that, if specified, must be a valid JavaScript identifier.
- A list of parameter names enclosed in parentheses. If there are no parameters to the function, you need to provide empty parentheses.
- The body of the function as a series of JavaScript statements enclosed in braces.
A function declaration
The following is a very trivial example to demonstrate all the components of a function declaration:
function add(a,b){
return a+b;
}
c = add(1,2);
console.log(c); //prints 3The declaration begins with a function keyword followed by the function name. The function name is optional. If a function is not given a name, it is said to be anonymous. We will see how anonymous functions are used. The third part is the set of parameters of the function, wrapped in parentheses. Within the parentheses is a set of zero or more parameter names separated by commas. These names will be defined as variables in the function, and instead of being initialized to undefined, they will be initialized to the arguments supplied when the function is invoked. The fourth part is a set of statements wrapped in curly braces. These statements are the body of the function. They are executed when the function is invoked.
This method of function declaration is also known as function statement. When you declare functions like this, the content of the function is compiled and an object with the same name as the function is created.
Another way of function declaration is via function expressions:
var add = function(a,b){
return a+b;
}
c = add(1,2);
console.log(c); //prints 3Here, we are creating an anonymous function and assigning it to an add variable; this variable is used to invoke the function as in the earlier example. One problem with this style of function declaration is that we cannot have recursive calls to this kind of function. Recursion is an elegant style of coding where the function calls itself. You can use named function expressions to solve this limitation. As an example, refer to the following function to compute the factorial of a given number, n:
var facto = function factorial(n) {
if (n <= 1)
return 1;
return n * factorial(n - 1);
};
console.log(facto(3)); //prints 6Here, instead of creating an anonymous function, you are creating a named function. Now, because the function has a name, it can call itself recursively.
Finally, you can create self-invoking function expressions (we will discuss them later):
(function sayHello() {
console.log("hello!");
})();Once defined, a function can be called in other JavaScript functions. After the function body is executed, the caller code (that executed the function) continues to execute. You can also pass a function as a parameter to another function:
function changeCase(val) {
return val.toUpperCase();
}
function demofunc(a, passfunction) {
console.log(passfunction(a));
}
demofunc("smallcase", changeCase);In the preceding example, we are calling the demofunc() function with two parameters. The first parameter is the string that we want to convert to uppercase and the second one is the function reference to the changeCase() function. In demofunc(), we call the changeCase() function via its reference passed to the passfunction argument. Here we are passing a function reference as an argument to another function. This powerful concept will be discussed in detail later in the book when we discuss callbacks.
A function may or may not return a value. In the previous examples, we saw that the add function returned a value to the calling code. Apart from returning a value at the end of the function, calling
return explicitly allows you to conditionally return from a function:
var looper = function(x){
if (x%5===0) {
return;
}
console.log(x)
}
for(var i=1;i<10;i++){
looper(i);
}This code snippet prints 1, 2, 3, 4, 6, 7, 8, and 9, and not 5. When the if (x%5===0) condition is evaluated to true, the code simply returns from the function and the rest of the code is not executed.
Functions as data
In JavaScript, functions can be assigned to variables, and variables are data. You will shortly see that this is a powerful concept. Let's see the following example:
var say = console.log;
say("I can also say things");In the preceding example, we assigned the familiar console.log() function to the say variable. Any function can be assigned to a variable as shown in the preceding example. Adding parentheses to the variable will invoke it. Moreover, you can pass functions in other functions as parameters. Study the following example carefully and type it in JS Bin:
var validateDataForAge = function(data) {
person = data();
console.log(person);
if (person.age <1 || person.age > 99){
return true;
}else{
return false;
}
};
var errorHandlerForAge = function(error) {
console.log("Error while processing age");
};
function parseRequest(data,validateData,errorHandler) {
var error = validateData(data);
if (!error) {
console.log("no errors");
} else {
errorHandler();
}
}
var generateDataForScientist = function() {
return {
name: "Albert Einstein",
age : Math.floor(Math.random() * (100 - 1)) + 1,
};
};
var generateDataForComposer = function() {
return {
name: "J S Bach",
age : Math.floor(Math.random() * (100 - 1)) + 1,
};
};
//parse request
parseRequest(generateDataForScientist, validateDataForAge, errorHandlerForAge);
parseRequest(generateDataForComposer, validateDataForAge, errorHandlerForAge);In this example, we are passing functions as parameters to a parseRequest() function. We are passing different functions for two different calls, generateDataForScientist and generateDataForComposers, while the other two functions remain the same. You can observe that we defined a generic parseRequest(). It takes three functions as arguments, which are responsible for stitching together the specifics: the data, validator, and error handler. The parseRequest() function is fully extensible and customizable, and because it will be invoked by every request, there is a single, clean debugging point. I am sure that you have started to appreciate the incredible power that JavaScript functions provide.
Scoping
For beginners, JavaScript scoping is slightly confusing. These concepts may seem straightforward; however, they are not. Some important subtleties exist that must be understood in order to master the concept. So what is Scope? In JavaScript, scope refers to the current context of code.
A variable's scope is the context in which the variable exists. The scope specifies from where you can access a variable and whether you have access to the variable in that context. Scopes can be globally or locally defined.
Global scope
Any variable that you declare is by default defined in global scope. This is one of the most annoying language design decisions taken in JavaScript. As a global variable is visible in all other scopes, a global variable can be modified by any scope. Global variables make it harder to run loosely coupled subprograms in the same program/module. If the subprograms happen to have global variables that share the same names, then they will interfere with each other and likely fail, usually in difficult-to-diagnose ways. This is sometimes known as namespace clash. We discussed global scope in the previous chapter but let's revisit it briefly to understand how best to avoid this.
You can create a global variable in two ways:
- The first way is to place a var statement outside any function. Essentially, any variable declared outside a function is defined in the global scope.
- The second way is to omit the var statement while declaring a variable (also called implied globals). I think this was designed as a convenience for new programmers but turned out to be a nightmare. Even within a function scope, if you omit the var statement while declaring a variable, it's created by default in the global scope. This is nasty. You should always run your program against ESLint or JSHint to let them flag such violations. The following example shows how global scope behaves:
//Global Scope var a = 1; function scopeTest() { console.log(a); } scopeTest(); //prints 1
Here we are declaring a variable outside the function and in the global scope. This variable is available in the scopeTest() function. If you assign a new value to a global scope variable within a function scope (local), the original value in the global scope is overwritten:
//Global Scope
var a = 1;
function scopeTest() {
a = 2; //Overwrites global variable 2, you omit 'var'
console.log(a);
}
console.log(a); //prints 1
scopeTest(); //prints 2
console.log(a); //prints 2 (global value is overwritten)Local scope
Unlike most programming languages, JavaScript does not have block-level scope (variables scoped to surrounding curly brackets); instead, JavaScript has function-level scope. Variables declared within a function are local variables and are only accessible within that function or by functions inside that function:
var scope_name = "Global";
function showScopeName () {
// local variable; only accessible in this function
var scope_name = "Local";
console.log (scope_name); // Local
}
console.log (scope_name); //prints - Global
showScopeName(); //prints – LocalFunction-level scope versus block-level scope
JavaScript variables are scoped at the function level. You can think of this as a small bubble getting created that prevents the variable to be visible from outside this bubble. A function creates such a bubble for variables declared inside the function. You can visualize the bubbles as follows:
-GLOBAL SCOPE---------------------------------------------|
var g =0; |
function foo(a) { -----------------------| |
var b = 1; | |
//code | |
function bar() { ------| | |
// ... |ScopeBar | ScopeFoo |
} ------| | |
// code | |
var c = 2; | |
}----------------------------------------| |
foo(); //WORKS |
bar(); //FAILS |
----------------------------------------------------------|JavaScript uses scope chains to establish the scope for a given function. There is typically one global scope, and each function defined has its own nested scope. Any function defined within another function has a local scope that is linked to the outer function. It's always the position in the source that defines the scope. When resolving a variable, JavaScript starts at the innermost scope and searches outwards. With this, let's look at various scoping rules in JavaScript.
In the preceding crudely drawn visual, you can see that the foo() function is defined in the global scope. The foo() function has its local scope and access to the g variable because it's in the global scope. The a, b, and c variables are available in the local scope because they are defined within the function scope. The bar() function is also declared within the function scope and is available within the foo() function. However, once the function scope is over, the bar() function is not available. You cannot see or call the bar() function from outside the foo() function—a scope bubble.
Now that the
bar() function also has its own function scope (bubble), what is available in here? The bar() function has access to the foo() function and all the variables created in the parent scope of the foo() function—a, b, and c. The bar() function also has access to the global scoped variable, g.
This is a powerful idea. Take a moment to think about it. We just discussed how rampant and uncontrolled global scope can get in JavaScript. How about we take an arbitrary piece of code and wrap it around with a function? We will be able to hide and create a scope bubble around this piece of code. Creating the correct scope using function wrapping will help us create correct code and prevent difficult-to-detect bugs.
Another advantage of the function scope and hiding variables and functions within this scope is that you can avoid collisions between two identifiers. The following example shows such a bad case:
function foo() {
function bar(a) {
i = 2; // changing the 'i' in the enclosing scope's for-loop
console.log(a+i);
}
for (var i=0; i<10; i++) {
bar(i); // infinite loop
}
}
foo();In the bar() function, we are inadvertently modifying the value of i=2. When we call bar() from within the for loop, the value of the i variable is set to 2 and we never come out of an infinite loop. This is a bad case of namespace collision.
So far, using functions as a scope sounds like a great way to achieve modularity and correctness in JavaScript. Well, though this technique works, it's not really ideal. The first problem is that we must create a named function. If we keep creating such functions just to introduce the function scope, we pollute the global scope or parent scope. Additionally, we have to keep calling such functions. This introduces a lot of boilerplate, which makes the code unreadable over time:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope function foo() { var a = 2; console.log( a ); // 2 } //2. Now call the named function foo() foo(); console.log( a ); // 1
We introduced the function scope by creating a new function
foo() to the global scope and called this function later to execute the code.
In JavaScript, you can solve both these problems by creating functions that immediately get executed. Carefully study and type the following example:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope (function foo() { var a = 2; console.log( a ); // 2 })(); //<---this function executes immediately console.log( a ); // 1
Notice that the wrapping function statement starts with function. This means that instead of treating the function as a standard declaration, the function is treated as a function expression.
The (function foo(){ }) statement as an expression means that the identifier foo is found only in the scope of the foo() function, not in the outer scope. Hiding the name foo in itself means that it does not pollute the enclosing scope unnecessarily. This is so useful and far better. We add () after the function expression to execute it immediately. So the complete pattern looks as follows:
(function foo(){ /* code */ })();
This pattern is so common that it has a name: IIFE, which stands for Immediately Invoked Function Expression. Several programmers omit the function name when they use IIFE. As the primary use of IIFE is to introduce function-level scope, naming the function is not really required. We can write the earlier example as follows:
var a = 1; (function() { var a = 2; console.log( a ); // 2 })(); console.log( a ); // 1
Here we are creating an anonymous function as IIFE. While this is identical to the earlier named IIFE, there are a few drawbacks of using anonymous IIFEs:
- As you can't see the function name in the stack traces, debugging such code is very difficult
- You cannot use recursion on anonymous functions (as we discussed earlier)
- Overusing anonymous IIFEs sometimes results in unreadable code
Douglas Crockford and a few other experts recommend a slight variation of IIFE:
(function(){ /* code */ }());Both these IIFE forms are popular and you will see a lot of code using both these variations.
You can pass parameters to IIFEs. The following example shows you how to pass parameters to IIFEs:
(function foo(b) {
var a = 2;
console.log( a + b );
})(3); //prints 5Inline function expressions
There is another popular usage of inline function expressions where the functions are passed as parameters to other functions:
function setActiveTab(activeTabHandler, tab){
//set active tab
//call handler
activeTabHandler();
}
setActiveTab( function (){
console.log( "Setting active tab" );
}, 1 );
//prints "Setting active tab"Again, you can name this inline function expression to make sure that you get a correct stack trace while you are debugging the code.
Block scopes
As we discussed earlier, JavaScript does not have the concept of block scopes. Programmers familiar with other languages such as Java or C find this very uncomfortable. ECMAScript 6 (ES6) introduces the let keyword to introduce traditional block scope. This is so incredibly convenient that if you are sure your environment is going to support ES6, you should always use the let keyword. See the following code:
var foo = true;
if (foo) {
let bar = 42; //variable bar is local in this block { }
console.log( bar );
}
console.log( bar ); // ReferenceErrorHowever, as things stand today, ES6 is not supported by default in most popular browsers.
This chapter so far should have given you a fair understanding of how scoping works in JavaScript. If you are still unclear, I would suggest that you stop here and revisit the earlier sections of this chapter. Research your doubts on the Internet or put your questions on Stack Overflow. In short, make sure that you have no doubts related to the scoping rules.
It is very natural for us to think of code execution happening from top to bottom, line by line. This is how most of JavaScript code is executed but with some exceptions.
Consider the following code:
console.log( a ); var a = 1;
If you said this is an invalid code and will result in undefined when we call console.log(), you are absolutely correct. However, what about this?
a = 1; var a; console.log( a );
What should be the output of the preceding code? It is natural to expect undefined as the var a statement comes after a = 1, and it would seem natural to assume that the variable is redefined and thus assigned the default undefined. However, the output will be 1.
When you see var a = 1, JavaScript splits it into two statements: var a and a = 1. The first statement, the declaration, is processed during the compilation phase. The second statement, the assignment, is left in place for the execution phase.
So the preceding snippet would actually be executed as follows:
var a; //----Compilation phase a = 1; //------execution phase console.log( a );
The first snippet is actually executed as follows:
var a; //-----Compilation phase console.log( a ); a = 1; //------execution phase
So, as we can see, variable and function declarations are moved up to the top of the code during compilation phase—this is also popularly known as hoisting. It is very important to remember that only the declarations themselves are hoisted, while any assignments or other executable logic are left in place. The following snippet shows you how function declarations are hoisted:
foo();
function foo() {
console.log(a); // undefined
var a = 1;
}The declaration of the foo() function is hoisted such that we are able to execute the function before defining it. One important aspect of hoisting is that it works per scope. Within the foo() function, declaration of the a variable will be hoisted to the top of the foo() function, and not to the top of the program. The actual execution of the foo() function with hoisting will be something as follows:
function foo() {
var a;
console.log(a); // undefined
a = 1;
}We saw that function declarations are hoisted but function expressions are not. The next section explains this case.
Global scope
Any variable that you declare is by default defined in global scope. This is one of the most annoying language design decisions taken in JavaScript. As a global variable is visible in all other scopes, a global variable can be modified by any scope. Global variables make it harder to run loosely coupled subprograms in the same program/module. If the subprograms happen to have global variables that share the same names, then they will interfere with each other and likely fail, usually in difficult-to-diagnose ways. This is sometimes known as namespace clash. We discussed global scope in the previous chapter but let's revisit it briefly to understand how best to avoid this.
You can create a global variable in two ways:
- The first way is to place a var statement outside any function. Essentially, any variable declared outside a function is defined in the global scope.
- The second way is to omit the var statement while declaring a variable (also called implied globals). I think this was designed as a convenience for new programmers but turned out to be a nightmare. Even within a function scope, if you omit the var statement while declaring a variable, it's created by default in the global scope. This is nasty. You should always run your program against ESLint or JSHint to let them flag such violations. The following example shows how global scope behaves:
//Global Scope var a = 1; function scopeTest() { console.log(a); } scopeTest(); //prints 1
Here we are declaring a variable outside the function and in the global scope. This variable is available in the scopeTest() function. If you assign a new value to a global scope variable within a function scope (local), the original value in the global scope is overwritten:
//Global Scope
var a = 1;
function scopeTest() {
a = 2; //Overwrites global variable 2, you omit 'var'
console.log(a);
}
console.log(a); //prints 1
scopeTest(); //prints 2
console.log(a); //prints 2 (global value is overwritten)Local scope
Unlike most programming languages, JavaScript does not have block-level scope (variables scoped to surrounding curly brackets); instead, JavaScript has function-level scope. Variables declared within a function are local variables and are only accessible within that function or by functions inside that function:
var scope_name = "Global";
function showScopeName () {
// local variable; only accessible in this function
var scope_name = "Local";
console.log (scope_name); // Local
}
console.log (scope_name); //prints - Global
showScopeName(); //prints – LocalFunction-level scope versus block-level scope
JavaScript variables are scoped at the function level. You can think of this as a small bubble getting created that prevents the variable to be visible from outside this bubble. A function creates such a bubble for variables declared inside the function. You can visualize the bubbles as follows:
-GLOBAL SCOPE---------------------------------------------|
var g =0; |
function foo(a) { -----------------------| |
var b = 1; | |
//code | |
function bar() { ------| | |
// ... |ScopeBar | ScopeFoo |
} ------| | |
// code | |
var c = 2; | |
}----------------------------------------| |
foo(); //WORKS |
bar(); //FAILS |
----------------------------------------------------------|JavaScript uses scope chains to establish the scope for a given function. There is typically one global scope, and each function defined has its own nested scope. Any function defined within another function has a local scope that is linked to the outer function. It's always the position in the source that defines the scope. When resolving a variable, JavaScript starts at the innermost scope and searches outwards. With this, let's look at various scoping rules in JavaScript.
In the preceding crudely drawn visual, you can see that the foo() function is defined in the global scope. The foo() function has its local scope and access to the g variable because it's in the global scope. The a, b, and c variables are available in the local scope because they are defined within the function scope. The bar() function is also declared within the function scope and is available within the foo() function. However, once the function scope is over, the bar() function is not available. You cannot see or call the bar() function from outside the foo() function—a scope bubble.
Now that the
bar() function also has its own function scope (bubble), what is available in here? The bar() function has access to the foo() function and all the variables created in the parent scope of the foo() function—a, b, and c. The bar() function also has access to the global scoped variable, g.
This is a powerful idea. Take a moment to think about it. We just discussed how rampant and uncontrolled global scope can get in JavaScript. How about we take an arbitrary piece of code and wrap it around with a function? We will be able to hide and create a scope bubble around this piece of code. Creating the correct scope using function wrapping will help us create correct code and prevent difficult-to-detect bugs.
Another advantage of the function scope and hiding variables and functions within this scope is that you can avoid collisions between two identifiers. The following example shows such a bad case:
function foo() {
function bar(a) {
i = 2; // changing the 'i' in the enclosing scope's for-loop
console.log(a+i);
}
for (var i=0; i<10; i++) {
bar(i); // infinite loop
}
}
foo();In the bar() function, we are inadvertently modifying the value of i=2. When we call bar() from within the for loop, the value of the i variable is set to 2 and we never come out of an infinite loop. This is a bad case of namespace collision.
So far, using functions as a scope sounds like a great way to achieve modularity and correctness in JavaScript. Well, though this technique works, it's not really ideal. The first problem is that we must create a named function. If we keep creating such functions just to introduce the function scope, we pollute the global scope or parent scope. Additionally, we have to keep calling such functions. This introduces a lot of boilerplate, which makes the code unreadable over time:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope function foo() { var a = 2; console.log( a ); // 2 } //2. Now call the named function foo() foo(); console.log( a ); // 1
We introduced the function scope by creating a new function
foo() to the global scope and called this function later to execute the code.
In JavaScript, you can solve both these problems by creating functions that immediately get executed. Carefully study and type the following example:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope (function foo() { var a = 2; console.log( a ); // 2 })(); //<---this function executes immediately console.log( a ); // 1
Notice that the wrapping function statement starts with function. This means that instead of treating the function as a standard declaration, the function is treated as a function expression.
The (function foo(){ }) statement as an expression means that the identifier foo is found only in the scope of the foo() function, not in the outer scope. Hiding the name foo in itself means that it does not pollute the enclosing scope unnecessarily. This is so useful and far better. We add () after the function expression to execute it immediately. So the complete pattern looks as follows:
(function foo(){ /* code */ })();
This pattern is so common that it has a name: IIFE, which stands for Immediately Invoked Function Expression. Several programmers omit the function name when they use IIFE. As the primary use of IIFE is to introduce function-level scope, naming the function is not really required. We can write the earlier example as follows:
var a = 1; (function() { var a = 2; console.log( a ); // 2 })(); console.log( a ); // 1
Here we are creating an anonymous function as IIFE. While this is identical to the earlier named IIFE, there are a few drawbacks of using anonymous IIFEs:
- As you can't see the function name in the stack traces, debugging such code is very difficult
- You cannot use recursion on anonymous functions (as we discussed earlier)
- Overusing anonymous IIFEs sometimes results in unreadable code
Douglas Crockford and a few other experts recommend a slight variation of IIFE:
(function(){ /* code */ }());Both these IIFE forms are popular and you will see a lot of code using both these variations.
You can pass parameters to IIFEs. The following example shows you how to pass parameters to IIFEs:
(function foo(b) {
var a = 2;
console.log( a + b );
})(3); //prints 5Inline function expressions
There is another popular usage of inline function expressions where the functions are passed as parameters to other functions:
function setActiveTab(activeTabHandler, tab){
//set active tab
//call handler
activeTabHandler();
}
setActiveTab( function (){
console.log( "Setting active tab" );
}, 1 );
//prints "Setting active tab"Again, you can name this inline function expression to make sure that you get a correct stack trace while you are debugging the code.
Block scopes
As we discussed earlier, JavaScript does not have the concept of block scopes. Programmers familiar with other languages such as Java or C find this very uncomfortable. ECMAScript 6 (ES6) introduces the let keyword to introduce traditional block scope. This is so incredibly convenient that if you are sure your environment is going to support ES6, you should always use the let keyword. See the following code:
var foo = true;
if (foo) {
let bar = 42; //variable bar is local in this block { }
console.log( bar );
}
console.log( bar ); // ReferenceErrorHowever, as things stand today, ES6 is not supported by default in most popular browsers.
This chapter so far should have given you a fair understanding of how scoping works in JavaScript. If you are still unclear, I would suggest that you stop here and revisit the earlier sections of this chapter. Research your doubts on the Internet or put your questions on Stack Overflow. In short, make sure that you have no doubts related to the scoping rules.
It is very natural for us to think of code execution happening from top to bottom, line by line. This is how most of JavaScript code is executed but with some exceptions.
Consider the following code:
console.log( a ); var a = 1;
If you said this is an invalid code and will result in undefined when we call console.log(), you are absolutely correct. However, what about this?
a = 1; var a; console.log( a );
What should be the output of the preceding code? It is natural to expect undefined as the var a statement comes after a = 1, and it would seem natural to assume that the variable is redefined and thus assigned the default undefined. However, the output will be 1.
When you see var a = 1, JavaScript splits it into two statements: var a and a = 1. The first statement, the declaration, is processed during the compilation phase. The second statement, the assignment, is left in place for the execution phase.
So the preceding snippet would actually be executed as follows:
var a; //----Compilation phase a = 1; //------execution phase console.log( a );
The first snippet is actually executed as follows:
var a; //-----Compilation phase console.log( a ); a = 1; //------execution phase
So, as we can see, variable and function declarations are moved up to the top of the code during compilation phase—this is also popularly known as hoisting. It is very important to remember that only the declarations themselves are hoisted, while any assignments or other executable logic are left in place. The following snippet shows you how function declarations are hoisted:
foo();
function foo() {
console.log(a); // undefined
var a = 1;
}The declaration of the foo() function is hoisted such that we are able to execute the function before defining it. One important aspect of hoisting is that it works per scope. Within the foo() function, declaration of the a variable will be hoisted to the top of the foo() function, and not to the top of the program. The actual execution of the foo() function with hoisting will be something as follows:
function foo() {
var a;
console.log(a); // undefined
a = 1;
}We saw that function declarations are hoisted but function expressions are not. The next section explains this case.
Local scope
Unlike most programming languages, JavaScript does not have block-level scope (variables scoped to surrounding curly brackets); instead, JavaScript has function-level scope. Variables declared within a function are local variables and are only accessible within that function or by functions inside that function:
var scope_name = "Global";
function showScopeName () {
// local variable; only accessible in this function
var scope_name = "Local";
console.log (scope_name); // Local
}
console.log (scope_name); //prints - Global
showScopeName(); //prints – LocalFunction-level scope versus block-level scope
JavaScript variables are scoped at the function level. You can think of this as a small bubble getting created that prevents the variable to be visible from outside this bubble. A function creates such a bubble for variables declared inside the function. You can visualize the bubbles as follows:
-GLOBAL SCOPE---------------------------------------------|
var g =0; |
function foo(a) { -----------------------| |
var b = 1; | |
//code | |
function bar() { ------| | |
// ... |ScopeBar | ScopeFoo |
} ------| | |
// code | |
var c = 2; | |
}----------------------------------------| |
foo(); //WORKS |
bar(); //FAILS |
----------------------------------------------------------|JavaScript uses scope chains to establish the scope for a given function. There is typically one global scope, and each function defined has its own nested scope. Any function defined within another function has a local scope that is linked to the outer function. It's always the position in the source that defines the scope. When resolving a variable, JavaScript starts at the innermost scope and searches outwards. With this, let's look at various scoping rules in JavaScript.
In the preceding crudely drawn visual, you can see that the foo() function is defined in the global scope. The foo() function has its local scope and access to the g variable because it's in the global scope. The a, b, and c variables are available in the local scope because they are defined within the function scope. The bar() function is also declared within the function scope and is available within the foo() function. However, once the function scope is over, the bar() function is not available. You cannot see or call the bar() function from outside the foo() function—a scope bubble.
Now that the
bar() function also has its own function scope (bubble), what is available in here? The bar() function has access to the foo() function and all the variables created in the parent scope of the foo() function—a, b, and c. The bar() function also has access to the global scoped variable, g.
This is a powerful idea. Take a moment to think about it. We just discussed how rampant and uncontrolled global scope can get in JavaScript. How about we take an arbitrary piece of code and wrap it around with a function? We will be able to hide and create a scope bubble around this piece of code. Creating the correct scope using function wrapping will help us create correct code and prevent difficult-to-detect bugs.
Another advantage of the function scope and hiding variables and functions within this scope is that you can avoid collisions between two identifiers. The following example shows such a bad case:
function foo() {
function bar(a) {
i = 2; // changing the 'i' in the enclosing scope's for-loop
console.log(a+i);
}
for (var i=0; i<10; i++) {
bar(i); // infinite loop
}
}
foo();In the bar() function, we are inadvertently modifying the value of i=2. When we call bar() from within the for loop, the value of the i variable is set to 2 and we never come out of an infinite loop. This is a bad case of namespace collision.
So far, using functions as a scope sounds like a great way to achieve modularity and correctness in JavaScript. Well, though this technique works, it's not really ideal. The first problem is that we must create a named function. If we keep creating such functions just to introduce the function scope, we pollute the global scope or parent scope. Additionally, we have to keep calling such functions. This introduces a lot of boilerplate, which makes the code unreadable over time:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope function foo() { var a = 2; console.log( a ); // 2 } //2. Now call the named function foo() foo(); console.log( a ); // 1
We introduced the function scope by creating a new function
foo() to the global scope and called this function later to execute the code.
In JavaScript, you can solve both these problems by creating functions that immediately get executed. Carefully study and type the following example:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope (function foo() { var a = 2; console.log( a ); // 2 })(); //<---this function executes immediately console.log( a ); // 1
Notice that the wrapping function statement starts with function. This means that instead of treating the function as a standard declaration, the function is treated as a function expression.
The (function foo(){ }) statement as an expression means that the identifier foo is found only in the scope of the foo() function, not in the outer scope. Hiding the name foo in itself means that it does not pollute the enclosing scope unnecessarily. This is so useful and far better. We add () after the function expression to execute it immediately. So the complete pattern looks as follows:
(function foo(){ /* code */ })();
This pattern is so common that it has a name: IIFE, which stands for Immediately Invoked Function Expression. Several programmers omit the function name when they use IIFE. As the primary use of IIFE is to introduce function-level scope, naming the function is not really required. We can write the earlier example as follows:
var a = 1; (function() { var a = 2; console.log( a ); // 2 })(); console.log( a ); // 1
Here we are creating an anonymous function as IIFE. While this is identical to the earlier named IIFE, there are a few drawbacks of using anonymous IIFEs:
- As you can't see the function name in the stack traces, debugging such code is very difficult
- You cannot use recursion on anonymous functions (as we discussed earlier)
- Overusing anonymous IIFEs sometimes results in unreadable code
Douglas Crockford and a few other experts recommend a slight variation of IIFE:
(function(){ /* code */ }());Both these IIFE forms are popular and you will see a lot of code using both these variations.
You can pass parameters to IIFEs. The following example shows you how to pass parameters to IIFEs:
(function foo(b) {
var a = 2;
console.log( a + b );
})(3); //prints 5Inline function expressions
There is another popular usage of inline function expressions where the functions are passed as parameters to other functions:
function setActiveTab(activeTabHandler, tab){
//set active tab
//call handler
activeTabHandler();
}
setActiveTab( function (){
console.log( "Setting active tab" );
}, 1 );
//prints "Setting active tab"Again, you can name this inline function expression to make sure that you get a correct stack trace while you are debugging the code.
Block scopes
As we discussed earlier, JavaScript does not have the concept of block scopes. Programmers familiar with other languages such as Java or C find this very uncomfortable. ECMAScript 6 (ES6) introduces the let keyword to introduce traditional block scope. This is so incredibly convenient that if you are sure your environment is going to support ES6, you should always use the let keyword. See the following code:
var foo = true;
if (foo) {
let bar = 42; //variable bar is local in this block { }
console.log( bar );
}
console.log( bar ); // ReferenceErrorHowever, as things stand today, ES6 is not supported by default in most popular browsers.
This chapter so far should have given you a fair understanding of how scoping works in JavaScript. If you are still unclear, I would suggest that you stop here and revisit the earlier sections of this chapter. Research your doubts on the Internet or put your questions on Stack Overflow. In short, make sure that you have no doubts related to the scoping rules.
It is very natural for us to think of code execution happening from top to bottom, line by line. This is how most of JavaScript code is executed but with some exceptions.
Consider the following code:
console.log( a ); var a = 1;
If you said this is an invalid code and will result in undefined when we call console.log(), you are absolutely correct. However, what about this?
a = 1; var a; console.log( a );
What should be the output of the preceding code? It is natural to expect undefined as the var a statement comes after a = 1, and it would seem natural to assume that the variable is redefined and thus assigned the default undefined. However, the output will be 1.
When you see var a = 1, JavaScript splits it into two statements: var a and a = 1. The first statement, the declaration, is processed during the compilation phase. The second statement, the assignment, is left in place for the execution phase.
So the preceding snippet would actually be executed as follows:
var a; //----Compilation phase a = 1; //------execution phase console.log( a );
The first snippet is actually executed as follows:
var a; //-----Compilation phase console.log( a ); a = 1; //------execution phase
So, as we can see, variable and function declarations are moved up to the top of the code during compilation phase—this is also popularly known as hoisting. It is very important to remember that only the declarations themselves are hoisted, while any assignments or other executable logic are left in place. The following snippet shows you how function declarations are hoisted:
foo();
function foo() {
console.log(a); // undefined
var a = 1;
}The declaration of the foo() function is hoisted such that we are able to execute the function before defining it. One important aspect of hoisting is that it works per scope. Within the foo() function, declaration of the a variable will be hoisted to the top of the foo() function, and not to the top of the program. The actual execution of the foo() function with hoisting will be something as follows:
function foo() {
var a;
console.log(a); // undefined
a = 1;
}We saw that function declarations are hoisted but function expressions are not. The next section explains this case.
Function-level scope versus block-level scope
JavaScript variables are scoped at the function level. You can think of this as a small bubble getting created that prevents the variable to be visible from outside this bubble. A function creates such a bubble for variables declared inside the function. You can visualize the bubbles as follows:
-GLOBAL SCOPE---------------------------------------------|
var g =0; |
function foo(a) { -----------------------| |
var b = 1; | |
//code | |
function bar() { ------| | |
// ... |ScopeBar | ScopeFoo |
} ------| | |
// code | |
var c = 2; | |
}----------------------------------------| |
foo(); //WORKS |
bar(); //FAILS |
----------------------------------------------------------|JavaScript uses scope chains to establish the scope for a given function. There is typically one global scope, and each function defined has its own nested scope. Any function defined within another function has a local scope that is linked to the outer function. It's always the position in the source that defines the scope. When resolving a variable, JavaScript starts at the innermost scope and searches outwards. With this, let's look at various scoping rules in JavaScript.
In the preceding crudely drawn visual, you can see that the foo() function is defined in the global scope. The foo() function has its local scope and access to the g variable because it's in the global scope. The a, b, and c variables are available in the local scope because they are defined within the function scope. The bar() function is also declared within the function scope and is available within the foo() function. However, once the function scope is over, the bar() function is not available. You cannot see or call the bar() function from outside the foo() function—a scope bubble.
Now that the
bar() function also has its own function scope (bubble), what is available in here? The bar() function has access to the foo() function and all the variables created in the parent scope of the foo() function—a, b, and c. The bar() function also has access to the global scoped variable, g.
This is a powerful idea. Take a moment to think about it. We just discussed how rampant and uncontrolled global scope can get in JavaScript. How about we take an arbitrary piece of code and wrap it around with a function? We will be able to hide and create a scope bubble around this piece of code. Creating the correct scope using function wrapping will help us create correct code and prevent difficult-to-detect bugs.
Another advantage of the function scope and hiding variables and functions within this scope is that you can avoid collisions between two identifiers. The following example shows such a bad case:
function foo() {
function bar(a) {
i = 2; // changing the 'i' in the enclosing scope's for-loop
console.log(a+i);
}
for (var i=0; i<10; i++) {
bar(i); // infinite loop
}
}
foo();In the bar() function, we are inadvertently modifying the value of i=2. When we call bar() from within the for loop, the value of the i variable is set to 2 and we never come out of an infinite loop. This is a bad case of namespace collision.
So far, using functions as a scope sounds like a great way to achieve modularity and correctness in JavaScript. Well, though this technique works, it's not really ideal. The first problem is that we must create a named function. If we keep creating such functions just to introduce the function scope, we pollute the global scope or parent scope. Additionally, we have to keep calling such functions. This introduces a lot of boilerplate, which makes the code unreadable over time:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope function foo() { var a = 2; console.log( a ); // 2 } //2. Now call the named function foo() foo(); console.log( a ); // 1
We introduced the function scope by creating a new function
foo() to the global scope and called this function later to execute the code.
In JavaScript, you can solve both these problems by creating functions that immediately get executed. Carefully study and type the following example:
var a = 1; //Lets introduce a function -scope //1. Add a named function foo() into the global scope (function foo() { var a = 2; console.log( a ); // 2 })(); //<---this function executes immediately console.log( a ); // 1
Notice that the wrapping function statement starts with function. This means that instead of treating the function as a standard declaration, the function is treated as a function expression.
The (function foo(){ }) statement as an expression means that the identifier foo is found only in the scope of the foo() function, not in the outer scope. Hiding the name foo in itself means that it does not pollute the enclosing scope unnecessarily. This is so useful and far better. We add () after the function expression to execute it immediately. So the complete pattern looks as follows:
(function foo(){ /* code */ })();
This pattern is so common that it has a name: IIFE, which stands for Immediately Invoked Function Expression. Several programmers omit the function name when they use IIFE. As the primary use of IIFE is to introduce function-level scope, naming the function is not really required. We can write the earlier example as follows:
var a = 1; (function() { var a = 2; console.log( a ); // 2 })(); console.log( a ); // 1
Here we are creating an anonymous function as IIFE. While this is identical to the earlier named IIFE, there are a few drawbacks of using anonymous IIFEs:
- As you can't see the function name in the stack traces, debugging such code is very difficult
- You cannot use recursion on anonymous functions (as we discussed earlier)
- Overusing anonymous IIFEs sometimes results in unreadable code
Douglas Crockford and a few other experts recommend a slight variation of IIFE:
(function(){ /* code */ }());Both these IIFE forms are popular and you will see a lot of code using both these variations.
You can pass parameters to IIFEs. The following example shows you how to pass parameters to IIFEs:
(function foo(b) {
var a = 2;
console.log( a + b );
})(3); //prints 5Inline function expressions
There is another popular usage of inline function expressions where the functions are passed as parameters to other functions:
function setActiveTab(activeTabHandler, tab){
//set active tab
//call handler
activeTabHandler();
}
setActiveTab( function (){
console.log( "Setting active tab" );
}, 1 );
//prints "Setting active tab"Again, you can name this inline function expression to make sure that you get a correct stack trace while you are debugging the code.
Block scopes
As we discussed earlier, JavaScript does not have the concept of block scopes. Programmers familiar with other languages such as Java or C find this very uncomfortable. ECMAScript 6 (ES6) introduces the let keyword to introduce traditional block scope. This is so incredibly convenient that if you are sure your environment is going to support ES6, you should always use the let keyword. See the following code:
var foo = true;
if (foo) {
let bar = 42; //variable bar is local in this block { }
console.log( bar );
}
console.log( bar ); // ReferenceErrorHowever, as things stand today, ES6 is not supported by default in most popular browsers.
This chapter so far should have given you a fair understanding of how scoping works in JavaScript. If you are still unclear, I would suggest that you stop here and revisit the earlier sections of this chapter. Research your doubts on the Internet or put your questions on Stack Overflow. In short, make sure that you have no doubts related to the scoping rules.
It is very natural for us to think of code execution happening from top to bottom, line by line. This is how most of JavaScript code is executed but with some exceptions.
Consider the following code:
console.log( a ); var a = 1;
If you said this is an invalid code and will result in undefined when we call console.log(), you are absolutely correct. However, what about this?
a = 1; var a; console.log( a );
What should be the output of the preceding code? It is natural to expect undefined as the var a statement comes after a = 1, and it would seem natural to assume that the variable is redefined and thus assigned the default undefined. However, the output will be 1.
When you see var a = 1, JavaScript splits it into two statements: var a and a = 1. The first statement, the declaration, is processed during the compilation phase. The second statement, the assignment, is left in place for the execution phase.
So the preceding snippet would actually be executed as follows:
var a; //----Compilation phase a = 1; //------execution phase console.log( a );
The first snippet is actually executed as follows:
var a; //-----Compilation phase console.log( a ); a = 1; //------execution phase
So, as we can see, variable and function declarations are moved up to the top of the code during compilation phase—this is also popularly known as hoisting. It is very important to remember that only the declarations themselves are hoisted, while any assignments or other executable logic are left in place. The following snippet shows you how function declarations are hoisted:
foo();
function foo() {
console.log(a); // undefined
var a = 1;
}The declaration of the foo() function is hoisted such that we are able to execute the function before defining it. One important aspect of hoisting is that it works per scope. Within the foo() function, declaration of the a variable will be hoisted to the top of the foo() function, and not to the top of the program. The actual execution of the foo() function with hoisting will be something as follows:
function foo() {
var a;
console.log(a); // undefined
a = 1;
}We saw that function declarations are hoisted but function expressions are not. The next section explains this case.
Inline function expressions
There is another popular usage of inline function expressions where the functions are passed as parameters to other functions:
function setActiveTab(activeTabHandler, tab){
//set active tab
//call handler
activeTabHandler();
}
setActiveTab( function (){
console.log( "Setting active tab" );
}, 1 );
//prints "Setting active tab"Again, you can name this inline function expression to make sure that you get a correct stack trace while you are debugging the code.
Block scopes
As we discussed earlier, JavaScript does not have the concept of block scopes. Programmers familiar with other languages such as Java or C find this very uncomfortable. ECMAScript 6 (ES6) introduces the let keyword to introduce traditional block scope. This is so incredibly convenient that if you are sure your environment is going to support ES6, you should always use the let keyword. See the following code:
var foo = true;
if (foo) {
let bar = 42; //variable bar is local in this block { }
console.log( bar );
}
console.log( bar ); // ReferenceErrorHowever, as things stand today, ES6 is not supported by default in most popular browsers.
This chapter so far should have given you a fair understanding of how scoping works in JavaScript. If you are still unclear, I would suggest that you stop here and revisit the earlier sections of this chapter. Research your doubts on the Internet or put your questions on Stack Overflow. In short, make sure that you have no doubts related to the scoping rules.
It is very natural for us to think of code execution happening from top to bottom, line by line. This is how most of JavaScript code is executed but with some exceptions.
Consider the following code:
console.log( a ); var a = 1;
If you said this is an invalid code and will result in undefined when we call console.log(), you are absolutely correct. However, what about this?
a = 1; var a; console.log( a );
What should be the output of the preceding code? It is natural to expect undefined as the var a statement comes after a = 1, and it would seem natural to assume that the variable is redefined and thus assigned the default undefined. However, the output will be 1.
When you see var a = 1, JavaScript splits it into two statements: var a and a = 1. The first statement, the declaration, is processed during the compilation phase. The second statement, the assignment, is left in place for the execution phase.
So the preceding snippet would actually be executed as follows:
var a; //----Compilation phase a = 1; //------execution phase console.log( a );
The first snippet is actually executed as follows:
var a; //-----Compilation phase console.log( a ); a = 1; //------execution phase
So, as we can see, variable and function declarations are moved up to the top of the code during compilation phase—this is also popularly known as hoisting. It is very important to remember that only the declarations themselves are hoisted, while any assignments or other executable logic are left in place. The following snippet shows you how function declarations are hoisted:
foo();
function foo() {
console.log(a); // undefined
var a = 1;
}The declaration of the foo() function is hoisted such that we are able to execute the function before defining it. One important aspect of hoisting is that it works per scope. Within the foo() function, declaration of the a variable will be hoisted to the top of the foo() function, and not to the top of the program. The actual execution of the foo() function with hoisting will be something as follows:
function foo() {
var a;
console.log(a); // undefined
a = 1;
}We saw that function declarations are hoisted but function expressions are not. The next section explains this case.
Block scopes
As we discussed earlier, JavaScript does not have the concept of block scopes. Programmers familiar with other languages such as Java or C find this very uncomfortable. ECMAScript 6 (ES6) introduces the let keyword to introduce traditional block scope. This is so incredibly convenient that if you are sure your environment is going to support ES6, you should always use the let keyword. See the following code:
var foo = true;
if (foo) {
let bar = 42; //variable bar is local in this block { }
console.log( bar );
}
console.log( bar ); // ReferenceErrorHowever, as things stand today, ES6 is not supported by default in most popular browsers.
This chapter so far should have given you a fair understanding of how scoping works in JavaScript. If you are still unclear, I would suggest that you stop here and revisit the earlier sections of this chapter. Research your doubts on the Internet or put your questions on Stack Overflow. In short, make sure that you have no doubts related to the scoping rules.
It is very natural for us to think of code execution happening from top to bottom, line by line. This is how most of JavaScript code is executed but with some exceptions.
Consider the following code:
console.log( a ); var a = 1;
If you said this is an invalid code and will result in undefined when we call console.log(), you are absolutely correct. However, what about this?
a = 1; var a; console.log( a );
What should be the output of the preceding code? It is natural to expect undefined as the var a statement comes after a = 1, and it would seem natural to assume that the variable is redefined and thus assigned the default undefined. However, the output will be 1.
When you see var a = 1, JavaScript splits it into two statements: var a and a = 1. The first statement, the declaration, is processed during the compilation phase. The second statement, the assignment, is left in place for the execution phase.
So the preceding snippet would actually be executed as follows:
var a; //----Compilation phase a = 1; //------execution phase console.log( a );
The first snippet is actually executed as follows:
var a; //-----Compilation phase console.log( a ); a = 1; //------execution phase
So, as we can see, variable and function declarations are moved up to the top of the code during compilation phase—this is also popularly known as hoisting. It is very important to remember that only the declarations themselves are hoisted, while any assignments or other executable logic are left in place. The following snippet shows you how function declarations are hoisted:
foo();
function foo() {
console.log(a); // undefined
var a = 1;
}The declaration of the foo() function is hoisted such that we are able to execute the function before defining it. One important aspect of hoisting is that it works per scope. Within the foo() function, declaration of the a variable will be hoisted to the top of the foo() function, and not to the top of the program. The actual execution of the foo() function with hoisting will be something as follows:
function foo() {
var a;
console.log(a); // undefined
a = 1;
}We saw that function declarations are hoisted but function expressions are not. The next section explains this case.
Function declarations versus function expressions
We saw two ways by which functions are defined. Though they both serve identical purposes, there is a difference between these two types of declarations. Check the following example:
//Function expression
functionOne();
//Error
//"TypeError: functionOne is not a function
var functionOne = function() {
console.log("functionOne");
};
//Function declaration
functionTwo();
//No error
//Prints - functionTwo
function functionTwo() {
console.log("functionTwo");
}A function declaration is processed when execution enters the context in which it appears before any step-by-step code is executed. The function that it creates is given a proper name (functionTwo() in the preceding example) and this name is put in the scope in which the declaration appears. As it's processed before any step-by-step code in the same context, calling functionTwo() before defining it works without an error.
However, functionOne() is an anonymous function expression, evaluated when it's reached in the step-by-step execution of the code (also called runtime execution); we have to declare it before we can invoke it.
So essentially, the function declaration of functionTwo() was hoisted while the function expression of functionOne() was executed when line-by-line execution encountered it.
Note
Both function declarations and variable declarations are hoisted but functions are hoisted first, and then variables.
One thing to remember is that you should never use function declarations conditionally. This behavior is non-standardized and can behave differently across platforms. The following example shows such a snippet where we try to use function declarations conditionally. We are trying to assign different function body to function sayMoo() but such a conditional code is not guaranteed to work across all browsers and can result in unpredictable results:
// Never do this - different browsers will behave differently
if (true) {
function sayMoo() {
return 'trueMoo';
}
}
else {
function sayMoo() {
return 'falseMoo';
}
}
foo();However, it's perfectly safe and, in fact, smart to do the same with function expressions:
var sayMoo;
if (true) {
sayMoo = function() {
return 'trueMoo';
};
}
else {
sayMoo = function() {
return 'falseMoo';
};
}
foo();If you are curious to know why you should not use function declarations in conditional blocks, read on; otherwise, you can skip the following paragraph.
Function declarations are allowed to appear only in the program or function body. They cannot appear in a block ({ ... }). Blocks can only contain statements and not function declarations. Due to this, almost all implementations of JavaScript have behavior different from this. It is always advisable to never use function declarations in a conditional block.
Function expressions, on the other hand, are very popular. A very common pattern among JavaScript programmers is to fork function definitions based on some kind of a condition. As such forks usually happen in the same scope, it is almost always necessary to use function expressions.
The arguments parameter
The arguments parameter is a collection of all the arguments passed to the function. The collection has a property named length that contains the count of arguments, and the individual argument values can be obtained using an array indexing notation. Okay, we lied a bit. The arguments parameter is not a JavaScript array, and if you try to use array methods on arguments, you'll fail miserably. You can think of arguments as an array-like structure. This makes it possible to write functions that take an unspecified number of parameters. The following snippet shows you how you can pass a variable number of arguments to the function and iterate through them using an arguments array:
var sum = function () {
var i, total = 0;
for (i = 0; i < arguments.length; i += 1) {
total += arguments[i];
}
return total;
};
console.log(sum(1,2,3,4,5,6,7,8,9)); // prints 45
console.log(sum(1,2,3,4,5)); // prints 15As we discussed, the arguments parameter is not really an array; it is possible to convert it to an array as follows:
var args = Array.prototype.slice.call(arguments);
Once converted to an array, you can manipulate the list as you wish.
The this parameter
Whenever a function is invoked, in addition to the parameters that represent the explicit arguments that were provided on the function call, an implicit parameter named this is also passed to the function. It refers to an object that's implicitly associated with the function invocation, termed as a function context. If you have coded in Java, the this keyword will be familiar to you; like Java, this points to an instance of the class in which the method is defined.
Equipped with this knowledge, let's talk about various invocation methods.
Invocation as a function
If a function is not invoked as a method, constructor, or via apply() or call(), it's simply invoked as a function:
function add() {}
add();
var substract = function() {
};
substract();When a function is invoked with this pattern, this is bound to the global object. Many experts believe this to be a bad design choice. It is natural to assume that this would be bound to the parent context. When you are in a situation such as this, you can capture the value of this in another variable. We will focus on this pattern later.
Invocation as a method
A method is a function tied to a property on an object. For methods, this is bound to the object on invocation:
var person = {
name: 'Albert Einstein',
age: 66,
greet: function () {
console.log(this.name);
}
};
person.greet();In this example, this is bound to the person object on invoking greet because greet is a method of person. Let's see how this behaves in both these invocation patterns.
Let's prepare this HTML and JavaScript harness:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>This test</title> <script type="text/javascript"> function testF(){ return this; } console.log(testF()); var testFCopy = testF; console.log(testFCopy()); var testObj = { testObjFunc: testF }; console.log(testObj.testObjFunc ()); </script> </head> <body> </body> </html>
In the Firebug console, you can see the following output:
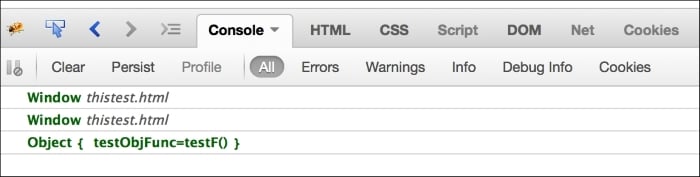
The first two method invocations were invocation as a function; hence, the this parameter pointed to the global context (Window, in this case).
Next, we define an object with a testObj variable with a property named testObjFunc that receives a reference to testF()—don't fret if you are not really aware of object creation yet. By doing this, we created a testObjMethod() method. Now, when we invoke this method, we expect the function context to be displayed when we display the value of this.
Invocation as a constructor
Constructor functions are declared just like any other functions and there's nothing special about a function that's going to be used as a constructor. However, the way in which they are invoked is very different.
To invoke the function as a constructor, we precede the function invocation with the new keyword. When this happens, this is bound to the new object.
Before we discuss more, let's take a quick introduction to object orientation in JavaScript. We will, of course, discuss the topic in great detail in the next chapter. JavaScript is a prototypal inheritance language. This means that objects can inherit properties directly from other objects. The language is class-free. Functions that are designed to be called with the new prefix are called constructors. Usually, they are named using PascalCase as opposed to CamelCase for easier distinction. In the following example, notice that the greet function uses this to access the name property. The this parameter is bound to Person:
var Person = function (name) {
this.name = name;
};
Person.prototype.greet = function () {
return this.name;
};
var albert = new Person('Albert Einstein');
console.log(albert.greet());We will discuss this particular invocation method when we study objects in the next chapter.
Invocation using apply() and call() methods
We said earlier that JavaScript functions are objects. Like other objects, they also have certain methods. To invoke a function using its apply() method, we pass two parameters to apply(): the object to be used as the function context and an array of values to be used as the invocation arguments. The call() method is used in a similar manner, except that the arguments are passed directly in the argument list rather than as an array.
The this parameter
Whenever a function is invoked, in addition to the parameters that represent the explicit arguments that were provided on the function call, an implicit parameter named this is also passed to the function. It refers to an object that's implicitly associated with the function invocation, termed as a function context. If you have coded in Java, the this keyword will be familiar to you; like Java, this points to an instance of the class in which the method is defined.
Equipped with this knowledge, let's talk about various invocation methods.
Invocation as a function
If a function is not invoked as a method, constructor, or via apply() or call(), it's simply invoked as a function:
function add() {}
add();
var substract = function() {
};
substract();When a function is invoked with this pattern, this is bound to the global object. Many experts believe this to be a bad design choice. It is natural to assume that this would be bound to the parent context. When you are in a situation such as this, you can capture the value of this in another variable. We will focus on this pattern later.
Invocation as a method
A method is a function tied to a property on an object. For methods, this is bound to the object on invocation:
var person = {
name: 'Albert Einstein',
age: 66,
greet: function () {
console.log(this.name);
}
};
person.greet();In this example, this is bound to the person object on invoking greet because greet is a method of person. Let's see how this behaves in both these invocation patterns.
Let's prepare this HTML and JavaScript harness:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>This test</title> <script type="text/javascript"> function testF(){ return this; } console.log(testF()); var testFCopy = testF; console.log(testFCopy()); var testObj = { testObjFunc: testF }; console.log(testObj.testObjFunc ()); </script> </head> <body> </body> </html>
In the Firebug console, you can see the following output:
The first two method invocations were invocation as a function; hence, the this parameter pointed to the global context (Window, in this case).
Next, we define an object with a testObj variable with a property named testObjFunc that receives a reference to testF()—don't fret if you are not really aware of object creation yet. By doing this, we created a testObjMethod() method. Now, when we invoke this method, we expect the function context to be displayed when we display the value of this.
Invocation as a constructor
Constructor functions are declared just like any other functions and there's nothing special about a function that's going to be used as a constructor. However, the way in which they are invoked is very different.
To invoke the function as a constructor, we precede the function invocation with the new keyword. When this happens, this is bound to the new object.
Before we discuss more, let's take a quick introduction to object orientation in JavaScript. We will, of course, discuss the topic in great detail in the next chapter. JavaScript is a prototypal inheritance language. This means that objects can inherit properties directly from other objects. The language is class-free. Functions that are designed to be called with the new prefix are called constructors. Usually, they are named using PascalCase as opposed to CamelCase for easier distinction. In the following example, notice that the greet function uses this to access the name property. The this parameter is bound to Person:
var Person = function (name) {
this.name = name;
};
Person.prototype.greet = function () {
return this.name;
};
var albert = new Person('Albert Einstein');
console.log(albert.greet());We will discuss this particular invocation method when we study objects in the next chapter.
Invocation using apply() and call() methods
We said earlier that JavaScript functions are objects. Like other objects, they also have certain methods. To invoke a function using its apply() method, we pass two parameters to apply(): the object to be used as the function context and an array of values to be used as the invocation arguments. The call() method is used in a similar manner, except that the arguments are passed directly in the argument list rather than as an array.
Invocation as a function
If a function is not invoked as a method, constructor, or via apply() or call(), it's simply invoked as a function:
function add() {}
add();
var substract = function() {
};
substract();When a function is invoked with this pattern, this is bound to the global object. Many experts believe this to be a bad design choice. It is natural to assume that this would be bound to the parent context. When you are in a situation such as this, you can capture the value of this in another variable. We will focus on this pattern later.
Invocation as a method
A method is a function tied to a property on an object. For methods, this is bound to the object on invocation:
var person = {
name: 'Albert Einstein',
age: 66,
greet: function () {
console.log(this.name);
}
};
person.greet();In this example, this is bound to the person object on invoking greet because greet is a method of person. Let's see how this behaves in both these invocation patterns.
Let's prepare this HTML and JavaScript harness:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>This test</title> <script type="text/javascript"> function testF(){ return this; } console.log(testF()); var testFCopy = testF; console.log(testFCopy()); var testObj = { testObjFunc: testF }; console.log(testObj.testObjFunc ()); </script> </head> <body> </body> </html>
In the Firebug console, you can see the following output:
The first two method invocations were invocation as a function; hence, the this parameter pointed to the global context (Window, in this case).
Next, we define an object with a testObj variable with a property named testObjFunc that receives a reference to testF()—don't fret if you are not really aware of object creation yet. By doing this, we created a testObjMethod() method. Now, when we invoke this method, we expect the function context to be displayed when we display the value of this.
Invocation as a constructor
Constructor functions are declared just like any other functions and there's nothing special about a function that's going to be used as a constructor. However, the way in which they are invoked is very different.
To invoke the function as a constructor, we precede the function invocation with the new keyword. When this happens, this is bound to the new object.
Before we discuss more, let's take a quick introduction to object orientation in JavaScript. We will, of course, discuss the topic in great detail in the next chapter. JavaScript is a prototypal inheritance language. This means that objects can inherit properties directly from other objects. The language is class-free. Functions that are designed to be called with the new prefix are called constructors. Usually, they are named using PascalCase as opposed to CamelCase for easier distinction. In the following example, notice that the greet function uses this to access the name property. The this parameter is bound to Person:
var Person = function (name) {
this.name = name;
};
Person.prototype.greet = function () {
return this.name;
};
var albert = new Person('Albert Einstein');
console.log(albert.greet());We will discuss this particular invocation method when we study objects in the next chapter.
Invocation using apply() and call() methods
We said earlier that JavaScript functions are objects. Like other objects, they also have certain methods. To invoke a function using its apply() method, we pass two parameters to apply(): the object to be used as the function context and an array of values to be used as the invocation arguments. The call() method is used in a similar manner, except that the arguments are passed directly in the argument list rather than as an array.
Invocation as a method
A method is a function tied to a property on an object. For methods, this is bound to the object on invocation:
var person = {
name: 'Albert Einstein',
age: 66,
greet: function () {
console.log(this.name);
}
};
person.greet();In this example, this is bound to the person object on invoking greet because greet is a method of person. Let's see how this behaves in both these invocation patterns.
Let's prepare this HTML and JavaScript harness:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>This test</title> <script type="text/javascript"> function testF(){ return this; } console.log(testF()); var testFCopy = testF; console.log(testFCopy()); var testObj = { testObjFunc: testF }; console.log(testObj.testObjFunc ()); </script> </head> <body> </body> </html>
In the Firebug console, you can see the following output:
The first two method invocations were invocation as a function; hence, the this parameter pointed to the global context (Window, in this case).
Next, we define an object with a testObj variable with a property named testObjFunc that receives a reference to testF()—don't fret if you are not really aware of object creation yet. By doing this, we created a testObjMethod() method. Now, when we invoke this method, we expect the function context to be displayed when we display the value of this.
Invocation as a constructor
Constructor functions are declared just like any other functions and there's nothing special about a function that's going to be used as a constructor. However, the way in which they are invoked is very different.
To invoke the function as a constructor, we precede the function invocation with the new keyword. When this happens, this is bound to the new object.
Before we discuss more, let's take a quick introduction to object orientation in JavaScript. We will, of course, discuss the topic in great detail in the next chapter. JavaScript is a prototypal inheritance language. This means that objects can inherit properties directly from other objects. The language is class-free. Functions that are designed to be called with the new prefix are called constructors. Usually, they are named using PascalCase as opposed to CamelCase for easier distinction. In the following example, notice that the greet function uses this to access the name property. The this parameter is bound to Person:
var Person = function (name) {
this.name = name;
};
Person.prototype.greet = function () {
return this.name;
};
var albert = new Person('Albert Einstein');
console.log(albert.greet());We will discuss this particular invocation method when we study objects in the next chapter.
Invocation using apply() and call() methods
We said earlier that JavaScript functions are objects. Like other objects, they also have certain methods. To invoke a function using its apply() method, we pass two parameters to apply(): the object to be used as the function context and an array of values to be used as the invocation arguments. The call() method is used in a similar manner, except that the arguments are passed directly in the argument list rather than as an array.
Invocation as a constructor
Constructor functions are declared just like any other functions and there's nothing special about a function that's going to be used as a constructor. However, the way in which they are invoked is very different.
To invoke the function as a constructor, we precede the function invocation with the new keyword. When this happens, this is bound to the new object.
Before we discuss more, let's take a quick introduction to object orientation in JavaScript. We will, of course, discuss the topic in great detail in the next chapter. JavaScript is a prototypal inheritance language. This means that objects can inherit properties directly from other objects. The language is class-free. Functions that are designed to be called with the new prefix are called constructors. Usually, they are named using PascalCase as opposed to CamelCase for easier distinction. In the following example, notice that the greet function uses this to access the name property. The this parameter is bound to Person:
var Person = function (name) {
this.name = name;
};
Person.prototype.greet = function () {
return this.name;
};
var albert = new Person('Albert Einstein');
console.log(albert.greet());We will discuss this particular invocation method when we study objects in the next chapter.
Invocation using apply() and call() methods
We said earlier that JavaScript functions are objects. Like other objects, they also have certain methods. To invoke a function using its apply() method, we pass two parameters to apply(): the object to be used as the function context and an array of values to be used as the invocation arguments. The call() method is used in a similar manner, except that the arguments are passed directly in the argument list rather than as an array.
Invocation using apply() and call() methods
We said earlier that JavaScript functions are objects. Like other objects, they also have certain methods. To invoke a function using its apply() method, we pass two parameters to apply(): the object to be used as the function context and an array of values to be used as the invocation arguments. The call() method is used in a similar manner, except that the arguments are passed directly in the argument list rather than as an array.
Anonymous functions
We introduced you to anonymous functions a bit earlier in this chapter, and as they're a crucial concept, we will take a detailed look at them. For a language inspired by Scheme, anonymous functions are an important logical and structural construct.
Anonymous functions are typically used in cases where the function doesn't need to have a name for later reference. Let's look at some of the most popular usages of anonymous functions.
Anonymous functions while creating an object
An anonymous function can be assigned to an object property. When we do that, we can call that function with a dot (.) operator. If you are coming from a Java or other OO language background, you will find this very familiar. In such languages, a function, which is part of a class is generally called with a notation—Class.function(). Let's consider the following example:
var santa = {
say :function(){
console.log("ho ho ho");
}
}
santa.say();In this example, we are creating an object with a say property, which is an anonymous function. In this particular case, this property is known as a method and not a function. We don't need to name this function because we are going to invoke it as the object property. This is a popular pattern and should come in handy.
Anonymous functions while creating a list
Here, we are creating two anonymous functions and adding them to an array. (We will take a detailed look at arrays later.) Then, you loop through this array and execute the functions in a loop:
<script type="text/javascript">
var things = [
function() { alert("ThingOne") },
function() { alert("ThingTwo") },
];
for(var x=0; x<things.length; x++) {
things[x]();
}
</script>Anonymous functions as a parameter to another function
This is one of the most popular patterns and you will find such code in most professional libraries:
// function statement
function eventHandler(event){
event();
}
eventHandler(function(){
//do a lot of event related things
console.log("Event fired");
});You are passing the anonymous function to another function. In the receiving function, you are executing the function passed as a parameter. This can be very convenient if you are creating single-use functions such as object methods or event handlers. The anonymous function syntax is more concise than declaring a function and then doing something with it as two separate steps.
Anonymous functions in conditional logic
You can use anonymous function expressions to conditionally change behavior. The following example shows this pattern:
var shape;
if(shape_name === "SQUARE") {
shape = function() {
return "drawing square";
}
}
else {
shape = function() {
return "drawing square";
}
}
alert(shape());Here, based on a condition, we are assigning a different implementation to the shape variable. This pattern can be very useful if used with care. Overusing this can result in unreadable and difficult-to-debug code.
Later in this book, we will look at several functional tricks such as memoization and caching function calls. If you have reached here by quickly reading through the entire chapter, I would suggest that you stop for a while and contemplate on what we have discussed so far. The last few pages contain a ton of information and it will take some time for all this information to sink in. I would suggest that you reread this chapter before proceeding further. The next section will focus on closures and the module pattern.
Anonymous functions while creating an object
An anonymous function can be assigned to an object property. When we do that, we can call that function with a dot (.) operator. If you are coming from a Java or other OO language background, you will find this very familiar. In such languages, a function, which is part of a class is generally called with a notation—Class.function(). Let's consider the following example:
var santa = {
say :function(){
console.log("ho ho ho");
}
}
santa.say();In this example, we are creating an object with a say property, which is an anonymous function. In this particular case, this property is known as a method and not a function. We don't need to name this function because we are going to invoke it as the object property. This is a popular pattern and should come in handy.
Anonymous functions while creating a list
Here, we are creating two anonymous functions and adding them to an array. (We will take a detailed look at arrays later.) Then, you loop through this array and execute the functions in a loop:
<script type="text/javascript">
var things = [
function() { alert("ThingOne") },
function() { alert("ThingTwo") },
];
for(var x=0; x<things.length; x++) {
things[x]();
}
</script>Anonymous functions as a parameter to another function
This is one of the most popular patterns and you will find such code in most professional libraries:
// function statement
function eventHandler(event){
event();
}
eventHandler(function(){
//do a lot of event related things
console.log("Event fired");
});You are passing the anonymous function to another function. In the receiving function, you are executing the function passed as a parameter. This can be very convenient if you are creating single-use functions such as object methods or event handlers. The anonymous function syntax is more concise than declaring a function and then doing something with it as two separate steps.
Anonymous functions in conditional logic
You can use anonymous function expressions to conditionally change behavior. The following example shows this pattern:
var shape;
if(shape_name === "SQUARE") {
shape = function() {
return "drawing square";
}
}
else {
shape = function() {
return "drawing square";
}
}
alert(shape());Here, based on a condition, we are assigning a different implementation to the shape variable. This pattern can be very useful if used with care. Overusing this can result in unreadable and difficult-to-debug code.
Later in this book, we will look at several functional tricks such as memoization and caching function calls. If you have reached here by quickly reading through the entire chapter, I would suggest that you stop for a while and contemplate on what we have discussed so far. The last few pages contain a ton of information and it will take some time for all this information to sink in. I would suggest that you reread this chapter before proceeding further. The next section will focus on closures and the module pattern.
Anonymous functions while creating a list
Here, we are creating two anonymous functions and adding them to an array. (We will take a detailed look at arrays later.) Then, you loop through this array and execute the functions in a loop:
<script type="text/javascript">
var things = [
function() { alert("ThingOne") },
function() { alert("ThingTwo") },
];
for(var x=0; x<things.length; x++) {
things[x]();
}
</script>Anonymous functions as a parameter to another function
This is one of the most popular patterns and you will find such code in most professional libraries:
// function statement
function eventHandler(event){
event();
}
eventHandler(function(){
//do a lot of event related things
console.log("Event fired");
});You are passing the anonymous function to another function. In the receiving function, you are executing the function passed as a parameter. This can be very convenient if you are creating single-use functions such as object methods or event handlers. The anonymous function syntax is more concise than declaring a function and then doing something with it as two separate steps.
Anonymous functions in conditional logic
You can use anonymous function expressions to conditionally change behavior. The following example shows this pattern:
var shape;
if(shape_name === "SQUARE") {
shape = function() {
return "drawing square";
}
}
else {
shape = function() {
return "drawing square";
}
}
alert(shape());Here, based on a condition, we are assigning a different implementation to the shape variable. This pattern can be very useful if used with care. Overusing this can result in unreadable and difficult-to-debug code.
Later in this book, we will look at several functional tricks such as memoization and caching function calls. If you have reached here by quickly reading through the entire chapter, I would suggest that you stop for a while and contemplate on what we have discussed so far. The last few pages contain a ton of information and it will take some time for all this information to sink in. I would suggest that you reread this chapter before proceeding further. The next section will focus on closures and the module pattern.
Anonymous functions as a parameter to another function
This is one of the most popular patterns and you will find such code in most professional libraries:
// function statement
function eventHandler(event){
event();
}
eventHandler(function(){
//do a lot of event related things
console.log("Event fired");
});You are passing the anonymous function to another function. In the receiving function, you are executing the function passed as a parameter. This can be very convenient if you are creating single-use functions such as object methods or event handlers. The anonymous function syntax is more concise than declaring a function and then doing something with it as two separate steps.
Anonymous functions in conditional logic
You can use anonymous function expressions to conditionally change behavior. The following example shows this pattern:
var shape;
if(shape_name === "SQUARE") {
shape = function() {
return "drawing square";
}
}
else {
shape = function() {
return "drawing square";
}
}
alert(shape());Here, based on a condition, we are assigning a different implementation to the shape variable. This pattern can be very useful if used with care. Overusing this can result in unreadable and difficult-to-debug code.
Later in this book, we will look at several functional tricks such as memoization and caching function calls. If you have reached here by quickly reading through the entire chapter, I would suggest that you stop for a while and contemplate on what we have discussed so far. The last few pages contain a ton of information and it will take some time for all this information to sink in. I would suggest that you reread this chapter before proceeding further. The next section will focus on closures and the module pattern.
Anonymous functions in conditional logic
You can use anonymous function expressions to conditionally change behavior. The following example shows this pattern:
var shape;
if(shape_name === "SQUARE") {
shape = function() {
return "drawing square";
}
}
else {
shape = function() {
return "drawing square";
}
}
alert(shape());Here, based on a condition, we are assigning a different implementation to the shape variable. This pattern can be very useful if used with care. Overusing this can result in unreadable and difficult-to-debug code.
Later in this book, we will look at several functional tricks such as memoization and caching function calls. If you have reached here by quickly reading through the entire chapter, I would suggest that you stop for a while and contemplate on what we have discussed so far. The last few pages contain a ton of information and it will take some time for all this information to sink in. I would suggest that you reread this chapter before proceeding further. The next section will focus on closures and the module pattern.
Closures
Traditionally, closures have been a feature of purely functional programming languages. JavaScript shows its affinity with such functional programming languages by considering closures integral to the core language constructs. Closures are gaining popularity in mainstream JavaScript libraries and advanced production code because they let you simplify complex operations. You will hear experienced JavaScript programmers talking almost reverently about closures—as if they are some magical construct far beyond the reach of the intellect that common men possess. However, this is not so. When you study this concept, you will find closures to be very obvious, almost matter-of-fact. Till you reach closure enlightenment, I suggest you read and reread this chapter, research on the Internet, write code, and read JavaScript libraries to understand how closures behave—but do not give up.
The first realization that you must have is that closure is everywhere in JavaScript. It is not a hidden special part of the language.
Before we jump into the nitty-gritty, let's quickly refresh the lexical scope in JavaScript. We discussed in great detail how lexical scope is determined at the function level in JavaScript. Lexical scope essentially determines where and how all identifiers are declared and predicts how they will be looked up during execution.
In a nutshell, closure is the scope created when a function is declared that allows the function to access and manipulate variables that are external to this function. In other words, closures allow a function to access all the variables, as well as other functions, that are in scope when the function itself is declared.
Let's look at some example code to understand this definition:
var outer = 'I am outer'; //Define a value in global scope
function outerFn() { //Declare a a function in global scope
console.log(outer);
}
outerFn(); //prints - I am outerWere you expecting something shiny? No, this is really the most ordinary case of a closure. We are declaring a variable in the global scope and declaring a function in the global scope. In the function, we are able to access the variable declared in the global scope—outer. So essentially, the outer scope for the outerFn() function is a closure and always available to outerFn(). This is a good start but perhaps then you are not sure why this is such a great thing.
Let's make things a bit more complex:
var outer = 'Outer'; //Variable declared in global scope
var copy;
function outerFn(){ //Function declared in global scope
var inner = 'Inner'; //Variable has function scope only, can not be
//accessed from outside
function innerFn(){ //Inner function within Outer function,
//both global context and outer
//context are available hence can access
//'outer' and 'inner'
console.log(outer);
console.log(inner);
}
copy=innerFn; //Store reference to inner function,
//because 'copy' itself is declared
//in global context, it will be available
//outside also
}
outerFn();
copy(); //Cant invoke innerFn() directly but can invoke via a
//variable declared in global scopeLet's analyze the preceding example. In innerFn(), the outer variable is available as it's part of the global context. We're executing the inner function after the outer function has been executed via copying a reference to the function to a global reference variable, copy. When innerFn() executes, the scope in outerFn() is gone and not visible at the point at which we're invoking the function through the copy variable. So shouldn't the following line fail?
console.log(inner);
Should the inner variable be undefined? However, the output of the preceding code snippet is as follows:
"Outer" "Inner"
What phenomenon allows the inner variable to still be available when we execute the inner function, long after the scope in which it was created has gone away? When we declared innerFn() in outerFn(), not only was the function declaration defined, but a closure was also created that encompasses not only the function declaration, but also all the variables that are in scope at the point of the declaration. When innerFn() executes, even if it's executed after the scope in which it was declared goes away, it has access to the original scope in which it was declared through its closure.
Let's continue to expand this example to understand how far you can go with closures:
var outer='outer';
var copy;
function outerFn() {
var inner='inner';
function innerFn(param){
console.log(outer);
console.log(inner);
console.log(param);
console.log(magic);
}
copy=innerFn;
}
console.log(magic); //ERROR: magic not defined
var magic="Magic";
outerFn();
copy("copy");In the preceding example, we have added a few more things. First, we added a parameter to innerFn()—just to illustrate that parameters are also part of the closure. There are two important points that we want to highlight.
All variables in an outer scope are included even if they are declared after the function is declared. This makes it possible for the line, console.log(magic), in innerFn(), to work.
However, the same line, console.log(magic), in the global scope will fail because even within the same scope, variables not yet defined cannot be referenced.
All these examples were intended to convey a few concepts that govern how closures work. Closures are a prominent feature in the JavaScript language and you can see them in most libraries.
Let's look at some popular patterns around closures.
Timers and callbacks
In implementing timers or callbacks, you need to call the handler asynchronously, mostly at a later point in time. Due to the asynchronous calls, we need to access variables from outside the scope in such functions. Consider the following example:
function delay(message) {
setTimeout( function timerFn(){
console.log( message );
}, 1000 );
}
delay( "Hello World" );We pass the inner timerFn() function to the built-in library function, setTimeout(). However, timerFn() has a scope closure over the scope of delay(), and hence it can reference the variable message.
Private variables
Closures are frequently used to encapsulate some information as private variables. JavaScript does not allow such encapsulation found in programming languages such as Java or C++, but by using closures, we can achieve similar encapsulation:
function privateTest(){
var points=0;
this.getPoints=function(){
return points;
};
this.score=function(){
points++;
};
}
var private = new privateTest();
private.score();
console.log(private.points); // undefined
console.log(private.getPoints());In the preceding example, we are creating a function that we intend to call as a constructor. In this privateTest() function, we are creating a var points=0 variable as a function-scoped variable. This variable is available only in privateTest(). Additionally, we create an accessor function (also called a getter)—getPoints()—this method allows us to read the value of only the points variable from outside privateTest(), making this variable private to the function. However, another method, score(), allows us to modify the value of the private point variable without directly accessing it from outside. This makes it possible for us to write code where a private variable is updated in a controlled fashion. This pattern can be very useful when you are writing libraries where you want to control how variables are accessed based on a contract and pre-established interface.
Loops and closures
Consider the following example of using functions inside loops:
for (var i=1; i<=5; i++) {
setTimeout( function delay(){
console.log( i );
}, i*100);
}This snippet should print 1, 2, 3, 4, and 5 on the console at an interval of 100 ms, right? Instead, it prints 6, 6, 6, 6, and 6 at an interval of 100 ms. Why is this happening? Here, we encounter a common issue with closures and looping. The i variable is being updated after the function is bound. This means that every bound function handler will always print the last value stored in i. In fact, the timeout function callbacks are running after the completion of the loop. This is such a common problem that JSLint will warn you if you try to use functions this way inside a loop.
How can we fix this behavior? We can introduce a function scope and local copy of the i variable in that scope. The following snippet shows you how we can do this:
for (var i=1; i<=5; i++) {
(function(j){
setTimeout( function delay(){
console.log( j );
}, j*100);
})( i );
}We pass the i variable and copy it to the j variable local to the IIFE. The introduction of an IIFE inside each iteration creates a new scope for each iteration and hence updates the local copy with the correct value.
Modules
Modules are used to mimic classes and focus on public and private access to variables and functions. Modules help in reducing the global scope pollution. Effective use of modules can reduce name collisions across a large code base. A typical format that this pattern takes is as follows:
Var moduleName=function() {
//private state
//private functions
return {
//public state
//public variables
}
}There are two requirements to implement this pattern in the preceding format:
- There must be an outer enclosing function that needs to be executed at least once.
- This enclosing function must return at least one inner function. This is necessary to create a closure over the private state—without this, you can't access the private state at all.
Check the following example of a module:
var superModule = (function (){
var secret = 'supersecretkey';
var passcode = 'nuke';
function getSecret() {
console.log( secret );
}
function getPassCode() {
console.log( passcode );
}
return {
getSecret: getSecret,
getPassCode: getPassCode
};
})();
superModule.getSecret();
superModule.getPassCode();This example satisfies both the conditions. Firstly, we create an IIFE or a named function to act as an outer enclosure. The variables defined will remain private because they are scoped in the function. We return the public functions to make sure that we have a closure over the private scope. Using IIFE in the module pattern will actually result in a singleton instance of this function. If you want to create multiple instances, you can create named function expressions as part of the module as well.
We will keep exploring various facets of functional aspects of JavaScript and closures in particular. There can be a lot of imaginative uses of such elegant constructs. An effective way to understand various patterns is to study the code of popular libraries and practice writing these patterns in your code.
Stylistic considerations
As in the previous chapter, we will conclude this discussion with certain stylistic considerations. Again, these are generally accepted guidelines and not rules—feel free to deviate from them if you have reason to believe otherwise:
- Use function declarations instead of function expressions:
// bad const foo = function () { }; // good function foo() { } - Never declare a function in a non-function block (if, while, and so on). Assign the function to a variable instead. Browsers allow you to do it, but they all interpret it differently.
- Never name a parameter
arguments. This will take precedence over theargumentsobject that is given to every function scope.
Stylistic considerations
As in the previous chapter, we will conclude this discussion with certain stylistic considerations. Again, these are generally accepted guidelines and not rules—feel free to deviate from them if you have reason to believe otherwise:
- Use function declarations instead of function expressions:
// bad const foo = function () { }; // good function foo() { } - Never declare a function in a non-function block (if, while, and so on). Assign the function to a variable instead. Browsers allow you to do it, but they all interpret it differently.
- Never name a parameter
arguments. This will take precedence over theargumentsobject that is given to every function scope.
Summary
In this chapter, we studied JavaScript functions. In JavaScript, functions play a critical role. We discussed how functions are created and used. We also discussed important ideas of closures and the scope of variables in terms of functions. We discussed functions as a way to create visibility classes and encapsulation.
In the next chapter, we will look at various data structures and data manipulation techniques in JavaScript.



