






















































Variance reduction methods
In the previous section, we learned one of the simplest policy gradient methods, called the REINFORCE method. One major issue we face with the policy gradient method we learned in the previous section is that the gradient, 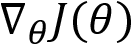 , will have high variance in each update. The high variance is basically due to the major difference in the episodic returns. That is, we learned that policy gradient is the on-policy method, which means that we improve the same policy with which we are generating episodes in every iteration. Since the policy is getting improved on every iteration, our return varies greatly in each episode and it introduces a high variance in the gradient updates. When the gradients have high variance, then it will take a lot of time to attain convergence.
, will have high variance in each update. The high variance is basically due to the major difference in the episodic returns. That is, we learned that policy gradient is the on-policy method, which means that we improve the same policy with which we are generating episodes in every iteration. Since the policy is getting improved on every iteration, our return varies greatly in each episode and it introduces a high variance in the gradient updates. When the gradients have high variance, then it will take a lot of time to attain convergence.
Thus, now we will learn the following two important methods to reduce the variance:
- Policy gradients with reward-to-go (causality)
- Policy gradients with baseline




