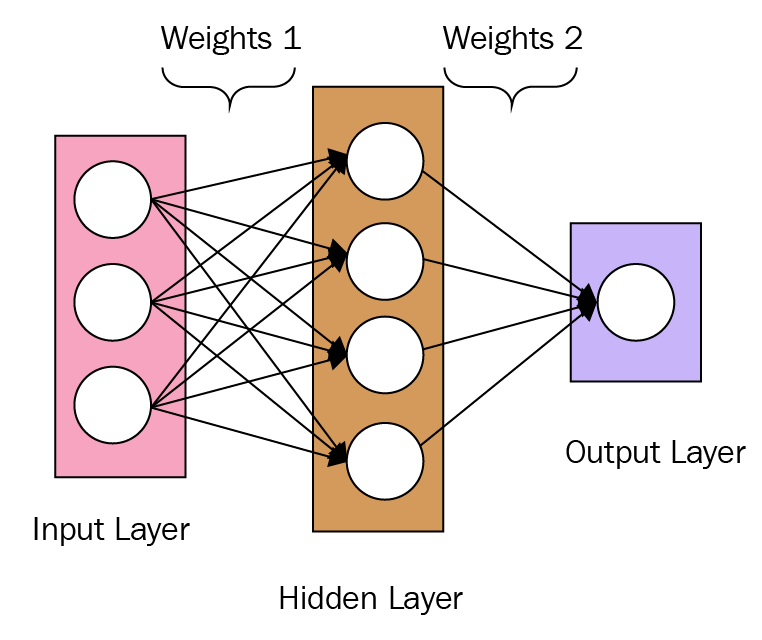
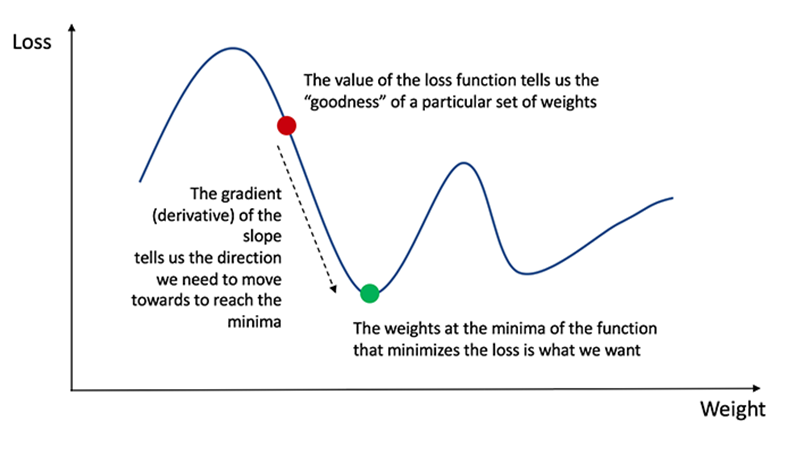
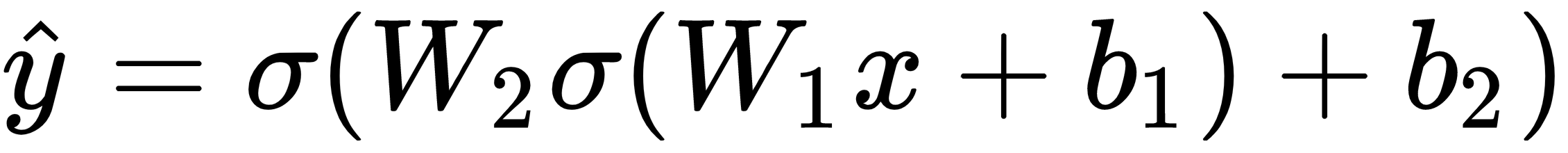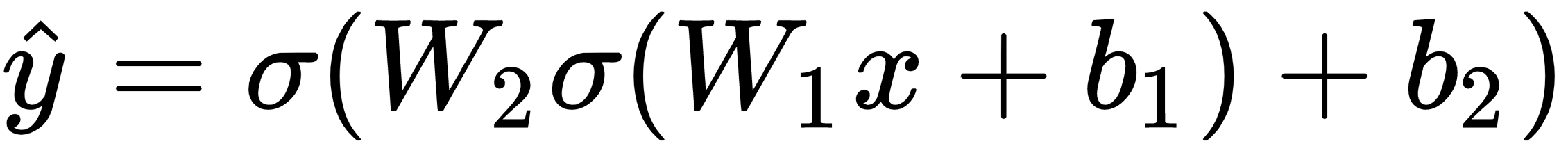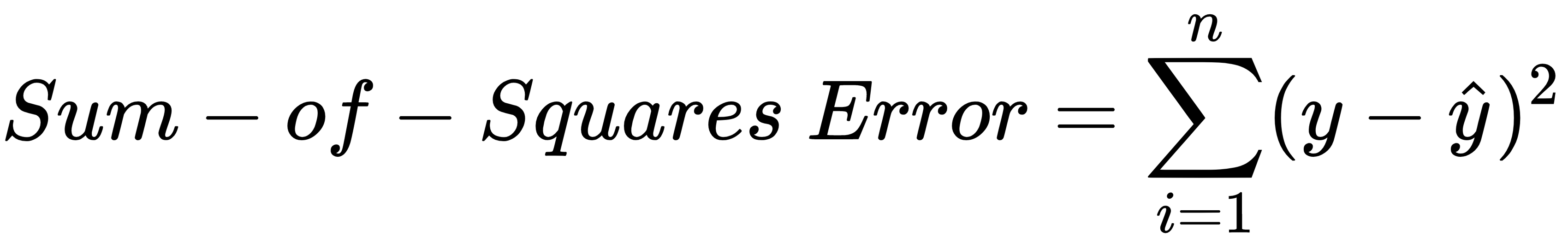Now that we've measured the error of our prediction (loss), we need to find a way to propagate the error back, and to update our weights and biases.
In order to know the appropriate amount to adjust the weights and biases by, we need to know the derivative of the loss function with respect to the weights and biases.
Recall from calculus that the derivative of a function is simply the slope of the function:
If we have the derivative, we can simply update the weights and biases by increasing/reducing with it (refer to the preceding diagram). This is known as gradient descent.
However, we can't directly calculate the derivative of the loss function with respect to the weights and biases because the equation of the loss function does not contain the weights and biases. We need the chain rule to help us calculate it. At this point, we are not going to delve into the chain rule because the math behind it can be rather complicated. Furthermore, machine learning libraries such as Keras takes care of gradient descent for us without requiring us to work out the chain rule from scratch. The key idea that we need to know is that once we have the derivative (slope) of the loss function with respect to the weights, we can adjust the weights accordingly.
Now let's add the backprop function into our Python code:
import numpy as np
def sigmoid(x):
return 1.0/(1 + np.exp(-x))
def sigmoid_derivative(x):
return x * (1.0 - x)
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
def backprop(self):
# application of the chain rule to find the derivation of the
# loss function with respect to weights2 and weights1
d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) *
sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output)
* sigmoid_derivative(self.output), self.weights2.T) *
sigmoid_derivative(self.layer1)))
self.weights1 += d_weights1
self.weights2 += d_weights2
if __name__ == "__main__":
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y = np.array([[0],[1],[1],[0]])
nn = NeuralNetwork(X,y)
for i in range(1500):
nn.feedforward()
nn.backprop()
print(nn.output)
Notice that in the preceding code, we used a sigmoid function in the feedforward function. The sigmoid function is an activation function to squash the values between 0 and 1. This is important because we need our predictions to be between 0 and 1 for this binary prediction problem. We will go through the sigmoid activation function in greater detail in the next chapter, Chapter 2, Predicting Diabetes with Multilayer Perceptrons.























































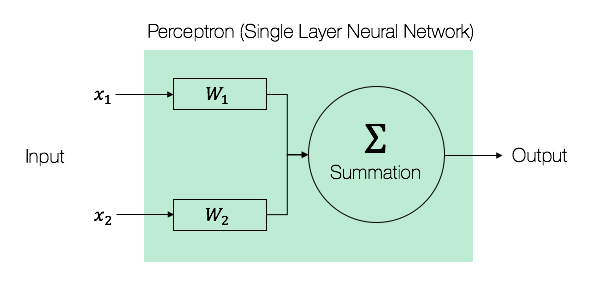
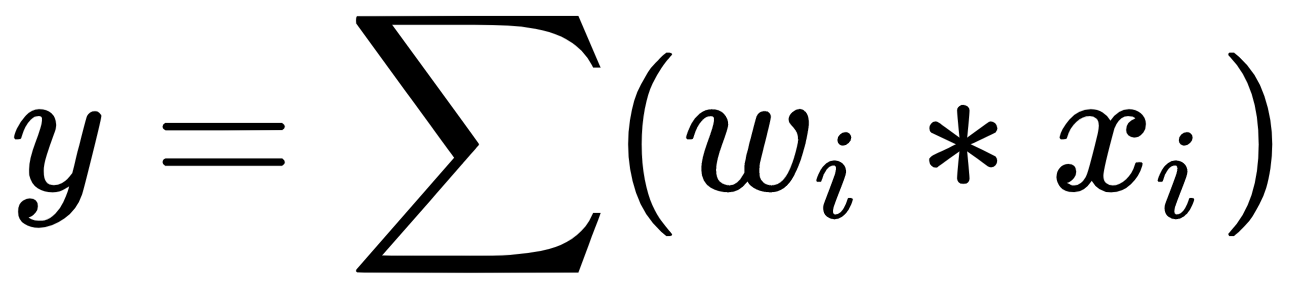
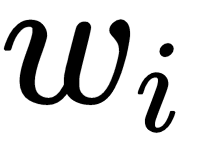 refers to the weights of the Perceptron. We will explain what the weights in a neural network refers to in the next few sections. For now, we just need to keep in mind that neural networks are simply mathematical functions that map a given input to a desired output.
refers to the weights of the Perceptron. We will explain what the weights in a neural network refers to in the next few sections. For now, we just need to keep in mind that neural networks are simply mathematical functions that map a given input to a desired output.