






















































Learning regularization from logistic regression examples
L-1 norm regularization, which penalizes the complexity of a model, is also called lasso regularization. The basic idea of regularization in a linear model is that parameters in a model can't be too large such that too many factors contribute to the predicted outcomes. However, lasso does one more thing. It not only penalizes the magnitude but also the parameters' existence. We will see how it works soon.
The name lasso comes from least absolute shrinkage and selection operator. It will shrink the values of parameters in a model. Because it uses the absolute value form, it also helps with selecting explanatory variables. We will see how it works soon.
Lasso regression is just like linear regression but instead of minimizing the sum of squared errors, it minimizes the following function. The index i loops over all data points where j loops over all coefficients:
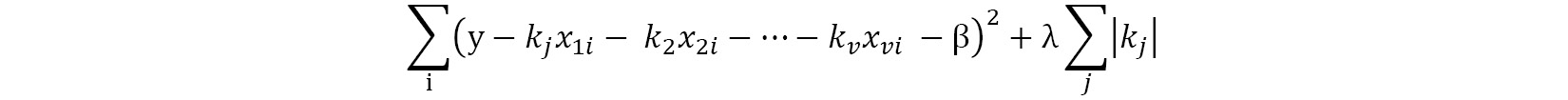
Unlike standard...





