






















































Sparse data refers to data structures such as arrays, series, DataFrames, and panels in which there is a very high proportion of missing data or NaNs.
Let's create a sparse DataFrame:
df = pd.DataFrame(np.random.randn(100, 3))
df.iloc[:95] = np.nan
This DataFrame has NaNs in 95% of the records. The memory usage of this data can be estimated with the following code:
df.memory_usage()
Take a look at the following output:
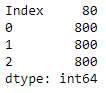
Memory usage of a DataFrame with 95% NaNs
As we can see, each element consumes 8 bytes of data, irrespective of whether it is actual data or a NaN. Pandas offers a memory-efficient solution for handling sparse data, as depicted in the following code:
sparse_df = df.to_sparse()
sparse_df.memory_usage()
Take a look at the following output:
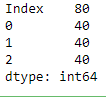
Memory usage of sparse data
Now, the memory usage has come down, with memory not being allotted to...






