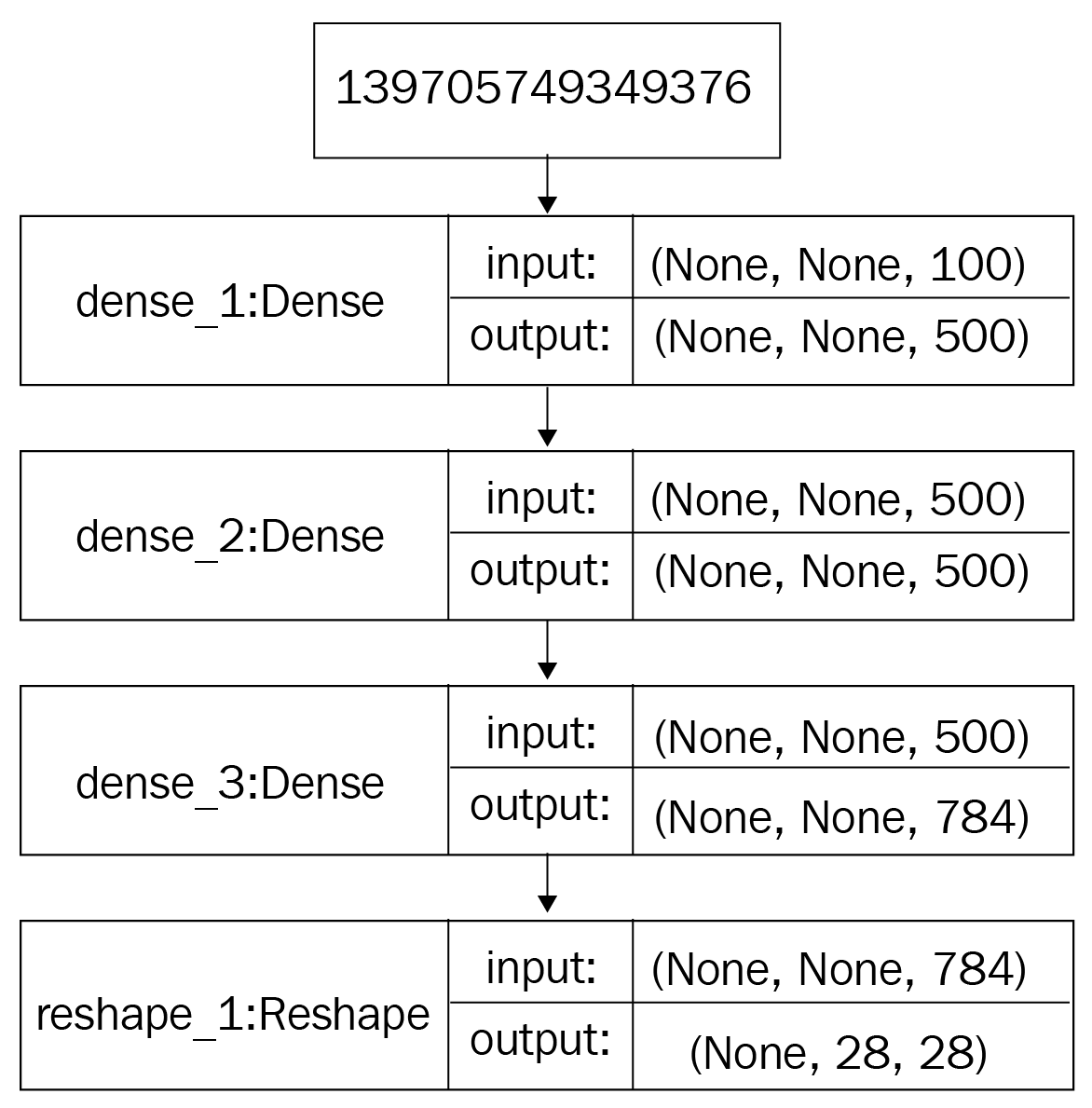
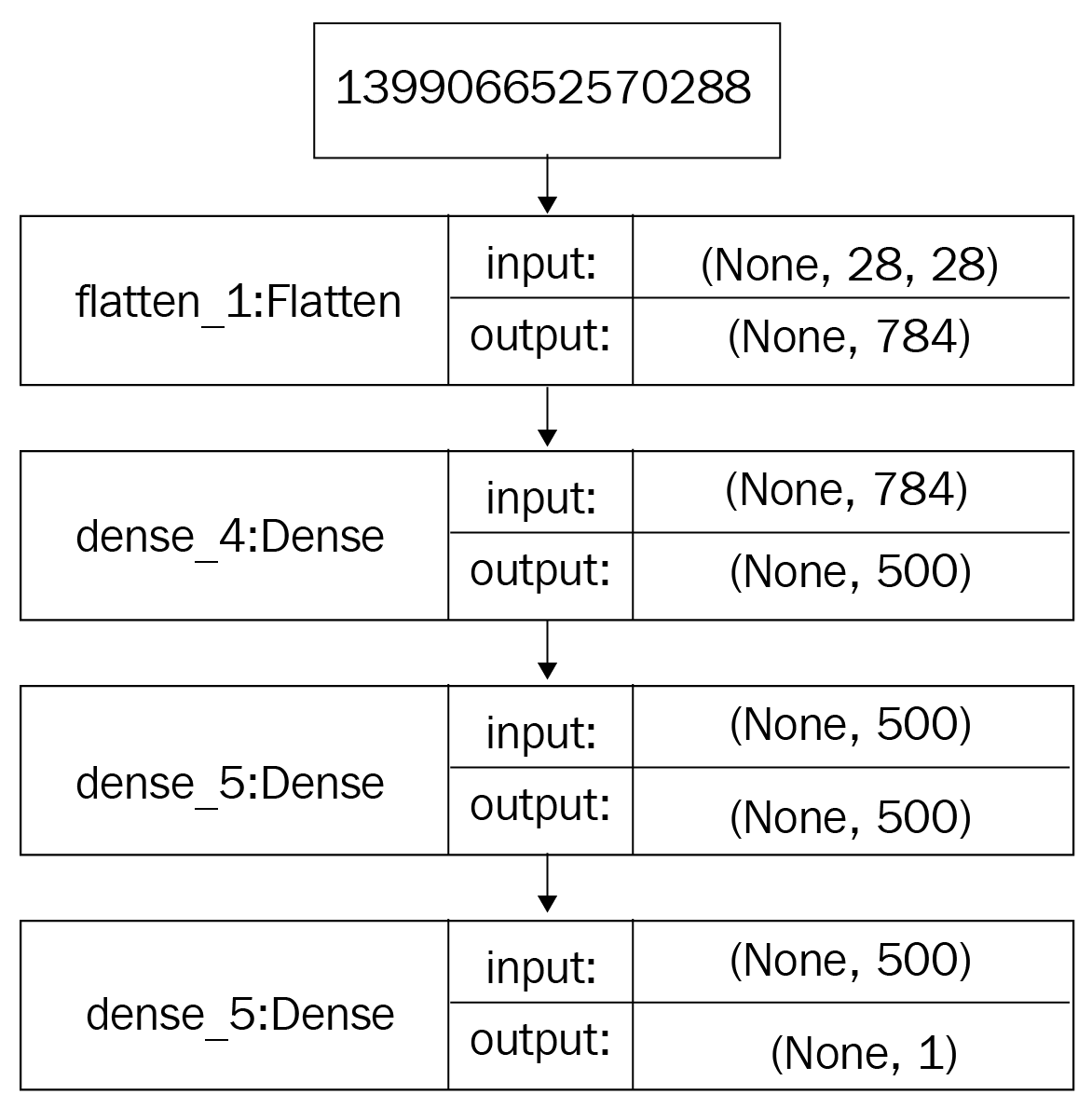
The architecture of a GAN has two basic elements: the generator network and the discriminator network. Each network can be any neural network, such as an Artificial Neural Network (ANN), a Convolutional Neural Network (CNN), a Recurrent Neural Network (RNN), or a Long Short Term Memory (LSTM). The discriminator has to have fully connected layers with a classifier at the end.
Let's take a closer look at the components of the architecture of a GAN. In this example, we will imagine that we are creating a dummy GAN.

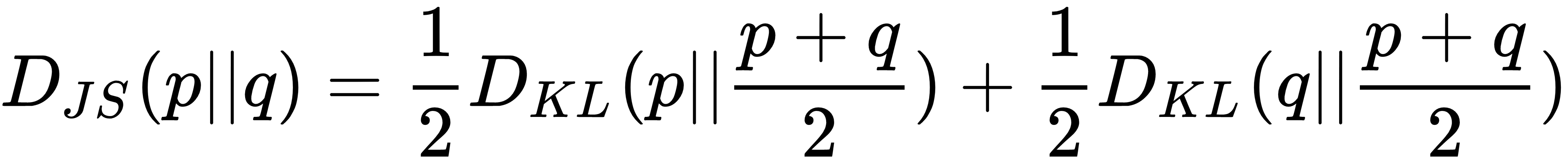
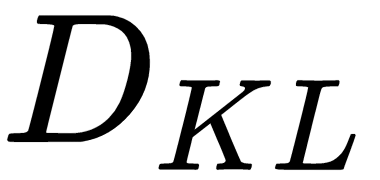 is the Kullback-Leibler divergence.
is the Kullback-Leibler divergence.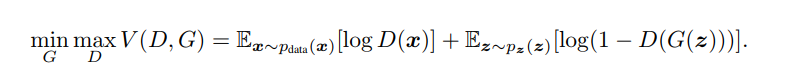
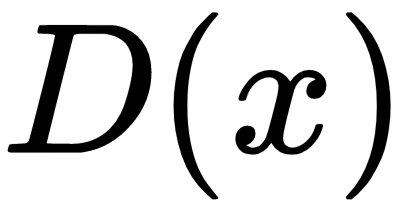 is the discriminator model,
is the discriminator model, 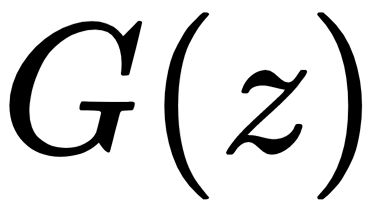 is the generator model,
is the generator model, 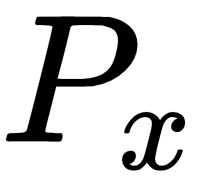 is the real data distribution,
is the real data distribution, 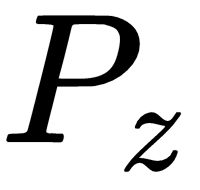 is the distribution of the data generated by the generator, and
is the distribution of the data generated by the generator, and  is the expected output.
is the expected output.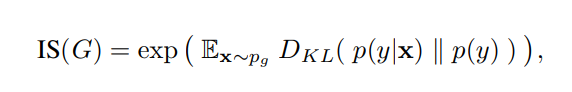
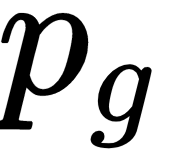 and
and  represent the same concept.
represent the same concept. 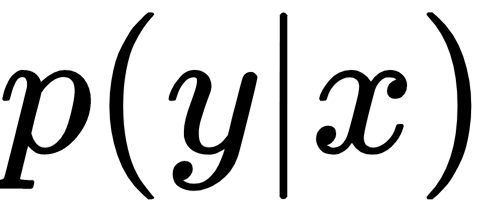 is the conditional class distribution, and
is the conditional class distribution, and 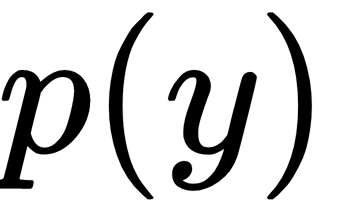 is the marginal class distribution.
is the marginal class distribution.
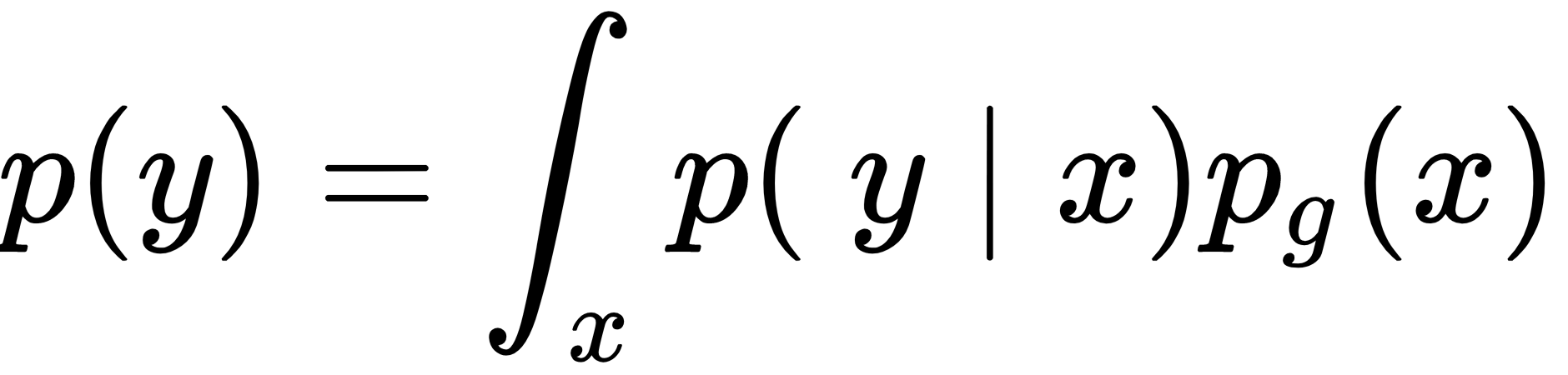
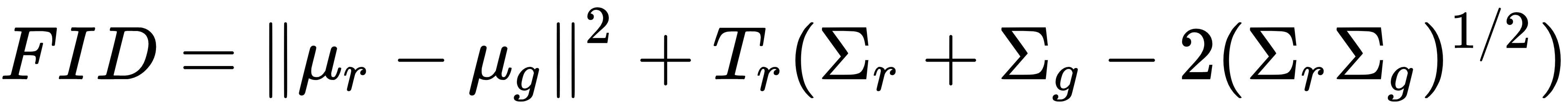
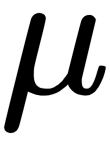 and a covariance of
and a covariance of