






















































Soft actor-critic
Now, we will look into another interesting actor-critic algorithm, called SAC. This is an off-policy algorithm and it borrows several features from the TD3 algorithm. But unlike TD3, it uses a stochastic policy 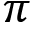 . SAC is based on the concept of entropy. So first, let's understand what is meant by entropy. Entropy is a measure of the randomness of a variable. It basically tells us the uncertainty or unpredictability of the random variable and is denoted by
. SAC is based on the concept of entropy. So first, let's understand what is meant by entropy. Entropy is a measure of the randomness of a variable. It basically tells us the uncertainty or unpredictability of the random variable and is denoted by 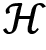 .
.
If the random variable always gives the same value every time, then we can say that its entropy is low because there is no randomness. But if the random variable gives different values, then we can say that its entropy is high.
For an example, consider a dice throw experiment. Every time a dice is thrown, if we get a different number, then we can say that the entropy is high because we are getting a different number every time and there is high uncertainty since we don't know which number will...




