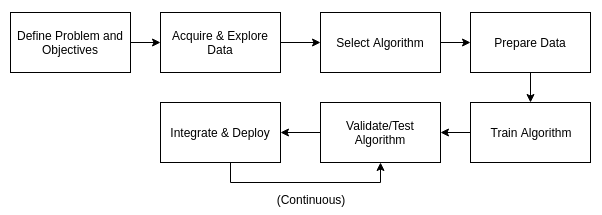
Data preparation refers to the processes performed on the input dataset before training the algorithm. A rigorous preparation process can simultaneously enhance the quality of the data and reduce the amount of time it will take the algorithm to reach the desired accuracy. The two steps to preparing data are data pre-processing and data transformation. We will go into more detail on preparing data in Chapters 2, Setting Up The Development Environment, Chapter 3, Supervised Learning, and Chapter 4, Unsupervised Learning.
Data pre-processing aims to transform the input dataset into a format that is adequate for work with the selected algorithm. A typical example of a pre-processing task is to format a date column in a certain way, or to ingest CSV files into a database, discarding any rows that lead to parsing errors. There may also be missing data values in an input data file that need to either be filled in (say, with a mean), or the entire sample discarded. Sensitive information such as personal information may need to be removed.
Data transformation is the process of sampling, reducing, enhancing, or aggregating the dataset to make it more suitable for the algorithm. If the input dataset is small, it may be necessary to enhance it by artificially creating more examples, such as rotating images in an image recognition dataset. If the input dataset has features that the exploration has deemed irrelevant, it would be wise to remove them. If the dataset is more granular than the problem requires, aggregating it to a coarser granularity may help speed up results, such as aggregating city-level data to counties if the problem only requires a prediction per county.
Finally, if the input dataset is particularly large, as is the case with many image datasets intended for use by deep learning algorithms, it would be a good idea to start with a smaller sample that will produce fast results so that the viability of the algorithm can be verified before investing in more computing resources.
The sampling process will also divide the input dataset into training and validation subsets. We will explain why this is necessary later, and what proportion of the data to use for both.