






















































Understanding the current state of AI and ML
The past is the only place where we can gather data to make predictions about the future. This is one of the core value propositions of AI and ML, and this is true for the field itself. I'll spare you from too much of the history lesson, but know that the techniques and approaches used today aren't new. In fact, neural networks have been around for over 60 years! Knowing this, keep in mind on your data science journey that a white paper or approach that you deem as old or out of date might just not have reached the right point for technology or data to catch up to it.
These systems allow for much greater scalability, distribution, and speed than if we had humans perform those same tasks. We will dive more into specific problem types later in the chapter.
Currently, one of the most well-known approaches to creating AI is neural networks, in which data scientists drew inspiration from how the human brain works. Neural networks were only a genuinely viable path when two things happened:
- We made the connection in 2012 that, just like our brain, we could get vastly better results if we created multiple layers.
- GPUs became fast enough to be able to train models in a reasonable timeframe.
This huge leap in AI techniques would not have been possible if we had not come back to the ideas of the past with fresh eyes and newer hardware.
Before more advanced GPUs were used, it simply took too long to train a model, and so this wasn't practical. Think about an assembly line making a car. If that moved along at one meter a day, that would be an effective end result, but it would take an extremely long time to produce a car (Henry Ford's 1914 assembly line moved at two meters a minute). Similar to 4k (and 8k) TVs being particularly useless until streaming or Blu-ray formats allowed us to have content that could even be shown in 4k, sometimes, other supporting technology needs to improve before the applications can be fully realized.
The massive increase in computational power in the last decade has unlocked the ability for the tensor computations to really shine and has taken us a long way from the Cornell report on The Perceptron (https://bit.ly/perceptron-cornell), the first paper to mention the ideas that would become the neural networks we use today. GPU power has increased at a rate such that the massive number of training runs can be done in hours, not years.
Tensors themselves are a common occurrence in physics and other forms of engineering and are an example of how data science has a heavy influence from other fields and has an especially strong relationship with mathematics. Now they are a staple tool in training deep learning models using neural networks.
Tensors
A tensor is simply a data structure that is commonly used in neural networks, but is a mathematical term. It can refer to matrices, vectors, and any n-dimensional arrays, but is mostly used to describe the latter when it comes to neural networks. It is where TensorFlow, the popular Google library, gets its name.
Deep learning is a technique in the field of AI and, more specifically, ML, but aren't they the same thing? The answer is no. Understanding the difference will help you focus on particular subsets and ensure that you have a clear picture of what is out there. Let's take a more in-depth look next.
Knowing the difference between AI and ML
Machine Learning (ML) is simply a machine being able to infer things based on input data without having to be specifically told what things are. It learns and deduces patterns and tries its best to fit new data into that pattern. ML is, in fact, a subset of the larger AI field, and since both terms are so widely used, it's valuable to get some brief examples of different types of AI and how the subsets fit into the broader term.
Let's look at a simple Venn diagram that shows the relationship between AI, ML, and deep learning. You'll see that AI is the broader concept, with ML and deep learning being specific subsets:
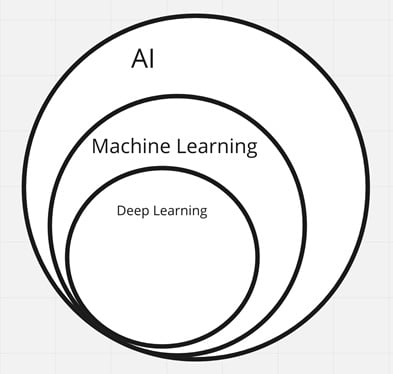
Figure 1.1 – Hierarchy of AI, ML, and deep learning
An example of AI that isn't ML is an expert system. This is a rule-based system that is designed for a very specific case, and in some ways can come down to if-else statements. It is following a hand-coded system behind the scenes, but that can be very powerful. A traffic light that switches to green if there is more than x number of cars in the North/South lane, but fewer than y cars in the East/West lane, would be an example.
These expert systems have been around for a long time, and the chess game was an example of that. The famous Deep Thought from Carnegie Mellon searched about 500 million possible outcomes per move to hunt down the best one. It was enough to put even the best chess players on the ropes. It later gave way to Deep Blue, which started to look like something closer to ML as it used a Bayesian structure to achieve its world conquest.
That's not AI! You might say. In an odd twist… IBM agrees with you, at least in the late 90s, as they actually claimed that it wasn't AI. This was likely due to the term having negative connotations associated with it. However, this mentality has changed in modern times. Many of the early promises of AI have come to fruition, solving many issues we knew we wanted to solve, and creating whole new sectors such as chatbots.
AI can be complex image detection, such as for self-driving, and voice recognition systems, such as Amazon's Alexa, but it can also be a system made up of relatively simple instructions. Think about how many simple tasks you carry out based on incredibly simple patterns. I'm hungry, I should eat. Those clothes are red, those are white, so they belong in different bins. Pretty simple right? The fact is that AI is a massive term that can include much more than what it's given credit for.
Much of what AI has become in the last 10 years is due to the high amount of data that it has access to. In the next section, we'll take a look in a little more detail at what that looks like.


