






















































Active Directory Domain Services components
In this section, we will look closer at the individual components of AD DS.
Objects
Objects refer to any element in the AD DS directory; examples of objects include printers, computers, users, groups, subnets, and so on. Objects have attributes that describe them; each will have required attributes and optional attributes. A name and an object identifier (OID) are two examples of required attributes.
In this section, we will look at the different classes of AD DS objects.
Container objects
These are built-in objects for logically grouping and holding other objects; think of these as hierarchical folder structures containing objects belonging to the same category or class.
When AD DS is installed, a set of default object containers are created; these will be visually represented as hierarchal folders. The following screenshot shows the default containers; some are hidden by default:
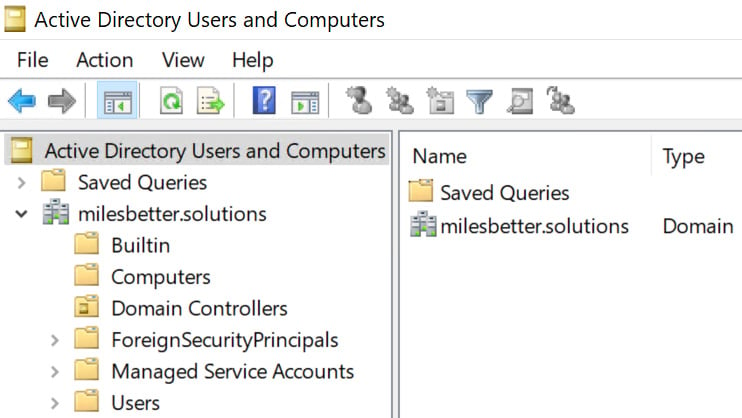
Figure 1.3 – Containers for objects
These default containers inherit a default set of permissions that are assigned to allow proper service administration and operations. These containers cannot be deleted, and you should not change the assigned permissions or delegate control of these; instead, you should create containers to meet your needs.
The essential containers to be aware of are as follows:
- The Domain container acts as the root container for the container hierarchy.
- The Builtin container provides a container that holds several default groups and default service admin accounts that are created when AD DS is installed.
- The Computers container provides a container that holds all computer account objects; it is the default location for all created computer accounts.
- The Users container provides a container that holds all user and group objects; it is also the default location for all created users and groups, some of which are automatically placed in this container location when AD DS is installed.
- The Domain Controllers OU container provides a container that holds the computer accounts for all DCs; it is the default location for all created DCs.
These default containers are automatically created when you install AD DS. They cannot be deleted, and assigned permissions and access control should not be modified. Still, custom containers can be created to meet your needs.
You can only apply policies to OU containers; to apply policies and delegate control over users or computers, you should create your own OU containers and move objects to those containers so that the policies and permissions can be applied.
The domain controllers container is an organizational unit (OU) container and is the only OU created by default when AD DS is installed. It is recommended that DCs not be moved out of their default location of the Domain Controllers OU container and not delegate control to non-service administrators.
Organizational unit
The OU functions as a container object and is used to collectively organize users, groups, and computers, providing a framework for targeting administrative control and policies on objects in the container.
An example of where OUs could be helpful is where you need to apply common administrative control to a group of resources that are part of the same workload (such as all Azure Virtual Desktop objects), environment (such as dev, test, prod, and so on), business unit, or region.
It is important to note that you can only link group policy objects (GPOs) to OU containers and not regular containers.
OUs can be created via the following methods:
- AD Users and Computers
- AD Admin Center
- PowerShell with the AD module
- Windows Admin Center (WAC), which is rapidly becoming the most widely adopted tool in hybrid environments
An OU structure can be hierarchal and map to organizational structures such as department, business group, or geography. These can be mapped to functions, projects, or resources such as workstations, servers, and so on.
OUs should group all those objects that need the same administration and policy settings and move them into an OU that can be controlled with Group Policy. If there are objects in an OU that you don’t want to have the policy applied to, then you can create a new OU and move the objects out to that OU so that the policy does not apply.
Hierarchal grouping is supported; you can nest OUs within OUs (just like any hierarchal folder structure). However, you should carefully plan the object grouping and hierarchy so that it isn’t too complex. Typically, five levels or less is optimum, and 10 is the recommended maximum to ease the admin burden and reduce complexity. You may also be constrained by a domain object resource that will only work with an OU structure of a supported method/configuration.
User objects
When a user account (an identity) is created in the directory, it’s classed as an object. It is one of the core and foundation object classes in the directory, along with computer objects. Hence, we will look at an AD DS management tool known as Active Directory Users and Computers later in this chapter.
For a user to be able to authenticate to domain resources, they must use a user account that AD DS provides. AD DS stores user accounts in its database with object-specific identity information and attributes such as the login username and password; these are used for the user to sign in to access domain resources.
In addition, other attributes include any organization-specific information that needs to be stored, such as job title, department, office, email, phone number, and more.
Regarding access management, the groups the user is a member of are listed. These group memberships are used to determine the level of access to resources in the domain; this is the concept of who you are and what access you have.
The recommended practice is that access rights are not given to user objects directly but to group objects. Users are members of groups, so they inherit their access permissions from their group memberships; this simplifies administration and makes troubleshooting access issues much easier and quicker.
Every user account object has a critical and primary attribute known as the User Principal Name (UPN). This is in an internet communication standard format typically recognized and expressed as an email address format – name@domain. However, it is essential to understand that it is not an email address. We recognize that a user’s email address could match their UPN and vice versa, but it’s not an explicit rule.
The user’s UPN is derived from a combination of the user’s login name and the domain name. The @ symbol is a form of join or delimiter between these two names; for example, the user Steve Miles in the milesbetter.solutions AD domain may have a UPN of [email protected], where smiles is the user login attribute for the user account of Steve Miles.
Two other terms are the UPN prefix and UPN suffix; the UPN prefix is the part of the name before the @ symbol, while the suffix is the part of the name after the @ symbol. The UPN prefix and suffix components are shown in the following screenshot:
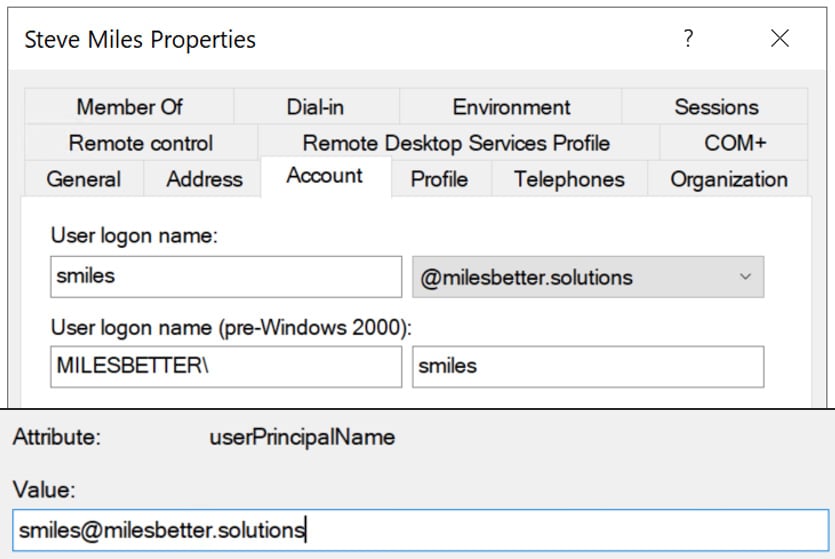
Figure 1.4 – UPN format
As in the previous user account example, the smiles login name attribute is then termed the UPN prefix, whereas the UPN suffix would be milesbetter. solutions, which refers to the domain part of the name.
Service objects
Service accounts are non-user-based account object classes used for applications and services that run in the background and require no user interaction. However, they still need to be authenticated to the directory service.
Managed Service Accounts (MSAs) are AD DS object classes that provide this service account capability; they benefit from lowering admin effort for Service Principal Name (SPN) management and service account password management.
There are two types of MSAs, as follows:
- Standard Managed Service Accounts (sMSAs) are local to a computer, service, or application and cannot be shared across other resources in the network. This limits their efficiency and adds an administrative burden. Needing to implement multiple local sMSAs increases the threat, security, and configuration drift surface area and exposure.
Further information about sMSAs can be found at https://docs.microsoft.com/en-us/azure/active-directory/fundamentals/service-accounts-standalone-managed.
- Group Managed Service Accounts (gMSAs) have domain scopes and capabilities and can be used across multiple computers, services, and applications; NLB clusters and IIS are examples.
gMSAs require you to create a key distribution services (KDS) root key on a DC to create gMSA accounts.
The following are some AD PowerShell cmdlets that can be used to manage gMSAs:
Get-ADServiceAccountInstall-ADServiceAccountNew-ADServiceAccountRemove-ADServiceAccountSet-ADServiceAccountTest-ADServiceAccountUninstall-ADServiceAccount
Further information about gMSAs can be found at https://docs.microsoft.com/en-us/azure/active-directory/fundamentals/service-accounts-group-managed.
Computer objects
Just as users have an account in the directory service so that we can search for and locate these users, we need the same mechanism to search for and locate computers in the domain. A computer object provides an account for a computer; it represents a computer resource on the network and allows it to uniquely identify itself and authenticate. Once a computer has a computer account, it can be managed as a domain resource and configured using Group Policy.
User account objects and computer account objects are the two foundation building block object classes in AD DS.
Group objects
Group object classes in the directory form the basis for access management.
Once you have been authenticated through your user account, your group object membership defines what you are authorized to access in the domain. The permissions assigned to the group define what actions you can carry out on that network resource.
Permissions shouldn’t be set at the user account level; this is an admin burden, inefficient, prone to configuration drift, and becomes a governance and security posture issue.
All permissions should be assigned to a group, and users should be made members of the appropriate groups to give them the required permissions. This makes it easier to govern and control policies such as joiners, leaver policies, or where people change roles and now require different access levels. Rather than change individual resource permissions directly for what they can now do/not do based on their new role definition, we can add or remove them to the appropriate groups based on their new role’s permissions requirements. This is much more efficient, less error-prone, and provides much better control and governance.
Adding user accounts to groups is an RBAC approach. The principle of least privilege should be adopted, meaning you only need just enough access to perform the tasks/activities required without the need for elevated permissions. This should be the cornerstone of protecting against lateral attacks following an account compromise.
In summary, by adopting the practice of creating groups, assigning permissions to groups, and then making user accounts members of those groups, we can efficiently manage access to resources for multiple users that all need the same access type.
Group types
There are two types of groups: security groups and distribution groups. Let’s look at these in more detail:
- Security groups are used as security-enabled logical containers to collectively group users to assign access permission to resources. This is a much more efficient way to assign a set of permissions to resources than assigning them individually to each user. For example, to control access to a network resource, we would create any number of groups, each with different levels of access permissions. Then, users can be added to the appropriate group(s), depending on what level of access they should have. We should ensure we follow the least privilege approach when assigning users to groups – that is, if they only need read access, then don’t make them members of a group with full-control permissions.
Two default security groups are created automatically when AD DS is installed; these groups are located in the Builtin and Users containers.
- Distribution groups are used as non-security enabled logical containers, that is, no permissions can be assigned to these groups, and are used for grouping users for providing some other form of non-security related administration, and to target a subset of users, often a business unit, team, or project focus. Most commonly used for email applications, for sending emails to target all group members.
Group scopes
Groups also have a scope. This defines where they can exist/be effective, the types of members that can be added, and the capabilities and permissions that the group supports.
Four types of group scopes are supported in Windows Server: local groups, domain-local groups, global groups, and universal groups. Let’s look at these in more detail:
- Local groups are effective only on the local machines they are created on and cannot be created on DCs; for clarity, these are not domain objects and exist only on local machines. The following are characteristics of local groups:
- Abilities and permissions: Can be assigned to local (non-domain) resources only
- Members: Any user account of the forest
- Domain-local groups only apply locally to the domain created within and exist on the AD DS DCs for that domain. They are the primary means of managing access rights and responsibilities to resources within the local domain. The following are characteristics of domain-local groups:
- Abilities and permissions: Can only be assigned to domain-local resources
- Members: Any user account of the forest
- Global groups are used to collectively group user accounts that share similar functions; this could be based on geographic location or business unit. The following are characteristics of global groups:
- Abilities and permissions: Can be assigned to any forest resource
- Members: Local domain only
- Universal groups are used in multi-domain environments and combine the functions of the domain-local and global groups. The following are characteristics of universal groups:
- Abilities and permissions: Can be assigned to any forest resource
- Members: Any user account of the AD DS forest
You set the group type and scope at the time of creation and choose based on your needs and requirements for each group; this must be given adequate planning.
This section looked at AD DS objects. The next section will look at the AD DS domain and domain tree topology.
Domains
As inferred by the name Domain Services, a domain is the core foundation component and the building block of AD DS. A domain is a logical container of objects in the directory for management purposes. AD DS directory objects could be user accounts, computer accounts, groups, printers, and so on; all objects within that domain are bound by and share the same admin and security policies.
The domain is an administrative and replication boundary for AD objects; security boundaries are only implemented at the forest level. We will explore this in the Forests section.
A domain has one or more DCs. This is a Windows Server role responsible for authenticating requests to access resources in the domain, such as authenticating and authorizing a login request to a computer or accessing a storage file share. The DCs hold a copy of the AD DS database that is writeable; we will look at the concept of RODC and its use cases later.
Domains have a hierarchal topology, referred to as a domain tree. It consists of domains in a parent/child relationship that share a parent root domain; they also share a contiguous namespace in DNS.
The AD DS domain and domain tree are shown in the following diagram:
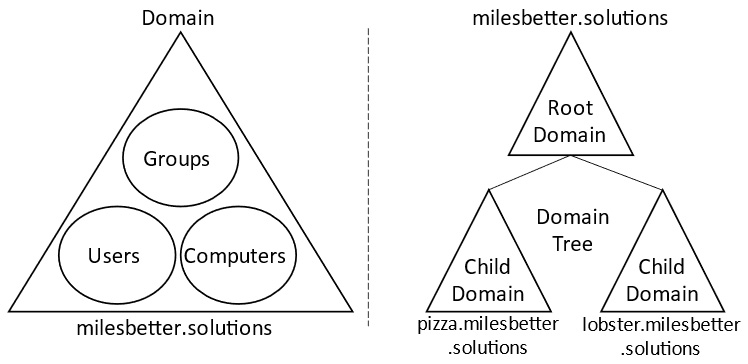
Figure 1.5 – Domain topology
AD DS uses a multi-master replication model, meaning that any DC can make changes to objects in the directory stored in the AD database. When changes to the domain are made on a DC, such as adding, removing, or changing an object, these changes are replicated to all other DCs in the domain. In a multi-domain case, only a subset of changes is replicated to all domains.
When the AD DS role is installed on Windows Server, a deployment option is provided for creating a new domain in an existing forest or a new domain in a new forest. The first domain in a new forest becomes what is known as the forest root domain; this is analogous to saying whether you would like to create a city in an existing state or whether you would like to create a new state and make this the first and parent/founding/capital city in that state – that is, the first domain in the new forest becomes the capital city, also known as the forest root domain.
This section looked at the AD DS domain and domain tree topology. The next section will look at the AD DS forest topology.
Forests
A forest is a top-level logical container definition. It is a collection of one or more domains that share a common parent root domain, schema, and global catalog that has a contiguous namespace; it is considered a security and administrative boundary.
To implement a security boundary for objects, they must be placed in different forests; all objects in a forest share the same security controls. It is a common misunderstanding that placing objects in different domains will isolate them between domains. It is essential to note this is not the case; only placing them in different forests can provide this isolation. The following diagram shows a visual representation of a forest:
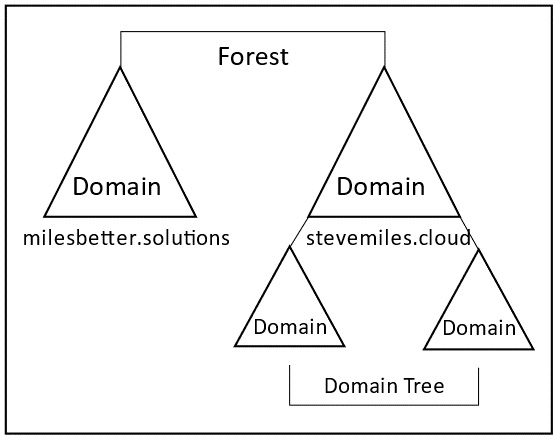
Figure 1.6 – Forest topology
The forest topology (structure or layout) means that a forest can contain one domain or multiple domains across multiple domain trees, much like a country can contain many states, which are collections of independent and autonomous cities. Each state would contain a state capital city; we refer to this as the forest root domain.
In this section, we looked closely at various AD DS components. In the next section, we will look at the function of AD DS trusts.
Trusts
Trusts are implemented to access resources when multiple domains and forests exist within an environment. Depending on the type of trust, these trusts can be one way or two way.
A trusted domain object is stored in the system container in AD DS and provides information on the trust types that have been created.
The most common trust types that can be implemented are as follows:
- Parent and child trust: This is created when a new domain is added to an existing tree. It is a transitive, two-way trust.
- Tree-root trust: This is created when a new tree is added to an existing forest. It is a transitive, two-way trust.
- Forest trust: This is a trust between forests and allows two forests to share resources. It is a transitive one-way or two-way trust.
- Shortcut trust: This is a trust created manually when authentication time between domains in different parts of the forest needs to be reduced. It is a nontransitive one-way or two-way trust.
- External trust: This is a trust that allows access to resources from a domain in another forest or an NT 4.0 domain. It is a nontransitive one-way or two-way trust.
- Realm trust: This is a trust between AD DS and a directory service other than AD DS that implements a Kerberos version 5 protocol realm. It is a transitive or nontransitive one-way or two-way trust.
These trust relationships are shown in the following diagram:
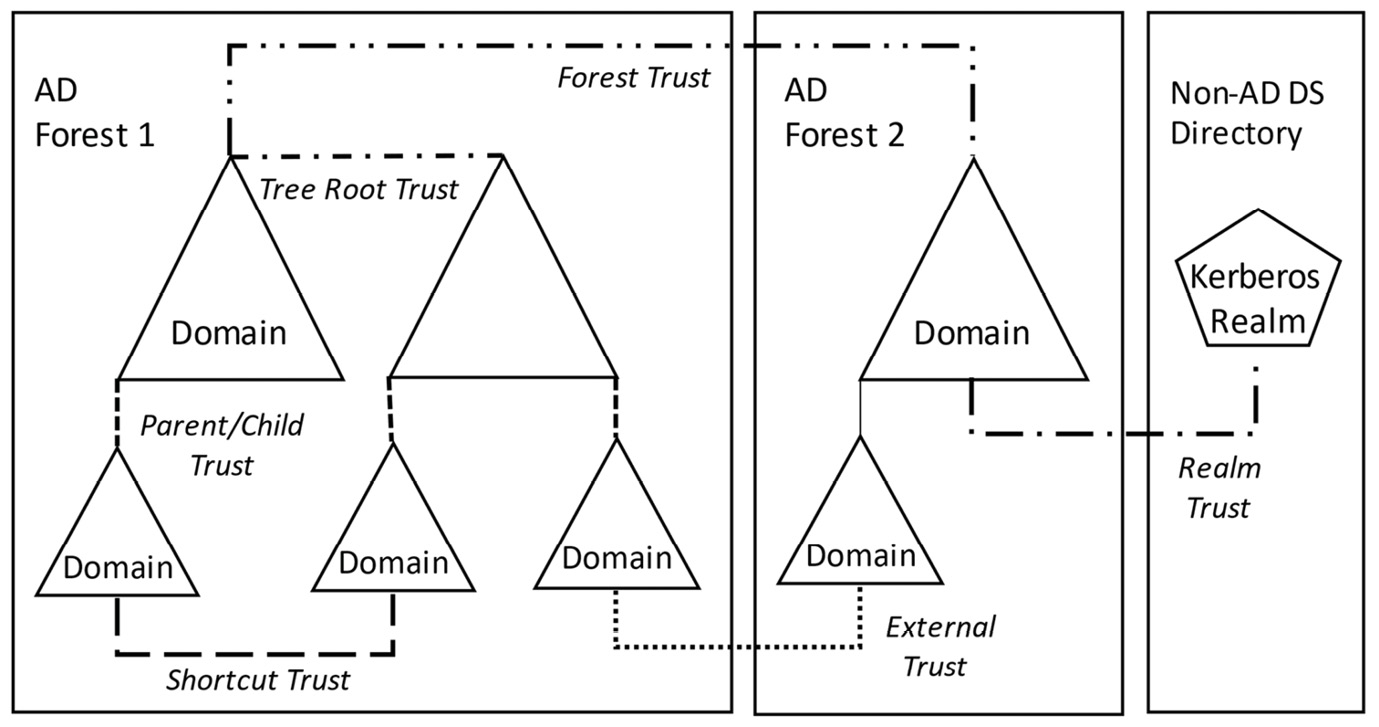
Figure 1.7 – Trusts
All automatically created two-way trusts in the forest are transitive. If domain B is trusted by domain A, and domain D is trusted by domain C, then domain A trusts domain C and D. This is a complex way of saying all the domains trust all the other domains in the forest.
However, in contrast, trusts between forests are not transitive, which means that if there are trusts between forests A and B and forests B and C, then C is not implicitly trusted by forest A.
Note that when a trust is set up between forests or domains, a function known as SID filtering is enabled by default. The purpose is to remove all foreign security identifiers (SIDs) from a user’s access token when using a trust in the trusting domain to access resources. Although it should be disabled to allow access to resources via the trust, you can disable this on the outgoing trust of the trusting domain.
When it comes to SID filtering and resource access across trusts, it is important to understand the trust direction and its relationship to the direction of access and which way the trust relationship is set up – that is, outgoing or incoming. This can be unclear; the core concept is that the direction of trust will be the opposite of the direction of access. This is shown in the following diagram:
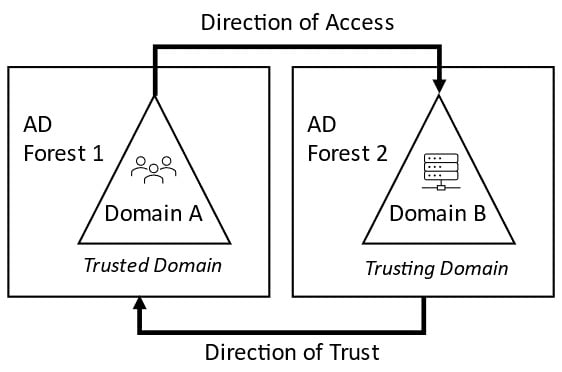
Figure 1.8 – Trust direction
This means that if you want to access resources in another forest, there must be an outgoing trust; conversely, an incoming trust allows outgoing access.
One final concept to note is that of the trust authentication types. External and forest trusts provide two modes of authentication: forest-wide authentication and selective authentication.
Further information about trusts can be found at https://docs.microsoft.com/en-us/azure/active-directory-domain-services/concepts-forest-trust.
In this section, we looked at AD DS trusts. Now, let’s look at the AD DS data store.
Data store
A directory information store holds the AD database, which uses the Extensible Storage Engine (ESE) based on the Jet database engine.
The database is made up of two files – the database file itself (named NTDS.DIT and located in C:\Windows\NTDS directory by default) and the transaction log file (named EDB.LOG and also located in C\:Windows\NTDS directory by default). These files are stored on each DC. The group policy files for the group policy objects are stored in the SYSVOL folder.
The AD DS database file (NTDS.DIT) contains four partitions (or naming contexts) that contain all the domain-related information. Different data is stored in each partition, and each partition is replicated between DCs with a dependent replication scope and schedule.
These partitions are shown in the following diagram:
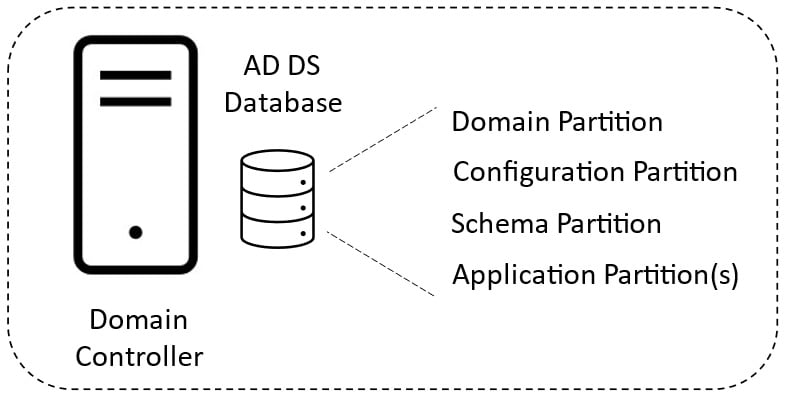
Figure 1.9 – AD DS database partitions
Let’s look at these four directory partitions in more detail:
- The schema partition is where the AD DS schema is stored; this defines what can be stored in the AD database
- The configuration partition is where the configuration information for the forest and domain trees is stored, such as site and replication information
- The domain partition is where object information for the domain is stored – that is, information about the user and computer objects
- The application partition is where applications can store data in AD; multiple application partitions may exist
In this section, we looked at the AD DS data store, which contains the AD DS database. We also looked at the partitions for the AD database. In the next section, we will look at the AD DS schema.
Schema
The schema is a partition of the AD database; it provides the definitions for the object classes (categories) that can be stored in the directory and the object-describing attributes. The object classes and object attributes are schema objects; in other technology areas, they would be referred to as metadata – that is, data describing the data.
The schema can be edited and allows you to create, modify, and disable object categories and attributes of objects. The schema is forest-wide, so any change is replicated to every domain in the forest. Understand the impact before committing any changes to the schema. In addition, be aware that deletions are not supported in the schema.
The default built-in group schema administrators control access to the schema; you must be a member of this group to make changes to the schema.
In this section, we looked at the AD schema. In the next section, we will look at AD DS DCs.
Domain controllers
A DC is a server with the AD DS role installed; it holds a writeable copy of the AD database and functions through the multi-master replication model for this information store. It also provides a store for GPOs. It ensures that the configuration settings are applied to domain-managed objects.
The DC is also a Kerberos Key Distribution Center (KDC). Kerberos is the mechanism for all authentication and authorization within AD; a Kerberos key identifies an object (authentication – that is, who you are) and outlines what resources an object can access (authorization – that is, what you can do and access).
DCS must be highly available to process logon requests; they are required to authenticate requests for access to domain resources and apply policies for managing and configuring objects in the directory stored in the AD database.
All computers and users that wish to access objects in an AD DS domain must be authenticated by a DC, so their placement, operation, and availability are crucial.
Read-only domain controller
In Windows Server 2008, the read-only domain controller (RODC) concept was introduced as a deployment option. An RODC server holds a copy of the AD database and supports one-way, incoming replication. No direct changes can be made to the directory (such as LDAP writes); the only changes that can occur are those that are made via replication. A change should be made on a DC, allowing replication to push those changes to the RODC.
The RODC role was intended as a branch office for other locations that may not have adequate security to protect against Kerberos system components being compromised, such as the KDC, which is a database of keys, and the Ticket Granting Service (TGS), which is used to obtain Kerberos session keys. Unlike DCs, which share a Kerberos key, RODCs each have a unique key, minimizing the risk of exposing remote sites that may be isolated from secured and controlled corporate networks.
RODCs have two other use cases. The first is where locations, such as branch offices, don’t have a lot of bandwidth for replication traffic. The other scenario is to support the principle of least privilege so that the local server admin account does not need to have domain admin access to function.
This section looked at DCs and their role in AD DS. Now, let’s look at the global catalog and its purpose.
Global catalog
The global catalog (GC) runs as a service on DCs and provides an index that allows you to look up information for every object listed in the AD forest (such as group memberships).
The GC holds a list of every object in the directory, but not every attribute for those objects; the schema defines what attributes of the objects are stored in the GC. The schema can be modified to allow those object attributes you want to appear in the GC so that they can be looked up in the GC.
When a user logs in, a GC must be contactable to look up a user’s universal group membership; however, when universal group caching is enabled, contacting a DC with a copy of the GC is less critical.
As part of the DC deployment, the first DC created in a forest holds a copy of the GC by default; this is for hybrid environments. GC placement should be designed for availability in each site, and perform local site searches to optimize network traffic. A DC that does not have a copy of the GC will have to send traffic over a WAN link to a site with a copy of the GC. GC placement is an important design decision; we will cover sites later in this chapter.
In this section, we looked at the purpose of the AD DS Global Catalog service. In the next section, we will look at the function of the operations master roles.
Operations master roles
Although AD DS runs on a multi-master model, some single master operation roles are known as Flexible Single Master Operations ((FSMO), pronounced fizmo) roles and run on DCs.
As the name implies, these are single instance roles. They are not replicated, so this does, to some extent, introduce a single point of failure. If a DC holding that role goes offline, then any operations that rely on being able to contact that role will not be available. This should be considered while managing expectations in any design.
The five FSMO roles are categorized as forest and domain operations scopes. These are as follows:
- Schema master (forest operations scope)
- Domain naming master (forest operations scope)
- RID master (domain operations scope)
- Infrastructure master (domain operations scope)
- PDC emulator master (domain operations scope)
Not all FSMO roles are created equal – some should be available for daily operations, while others are not required all the time. They each have different functions they perform, and some roles being available are more critical than others – that is, the schema master role could be offline. Only when you want to make schema changes would this impact you.
In this section, we looked at the function of AD DS operations master roles. Now, let’s look at AD DS sites and subnets.
Sites and subnets
A site is an AD object representing a collection of IP subnets connected over low latency connections and supporting local Remote Procedure Calls (RPCs). You can think of a site as a physical location that maps to your network WAN topology.
A subnet object represents each subnet where a DC is located; a subnet object will be part of a site object and can only be created as a one-to-one mapping – that is, a subnet can only be part of a single site.
The site topology is shown in the following diagram:
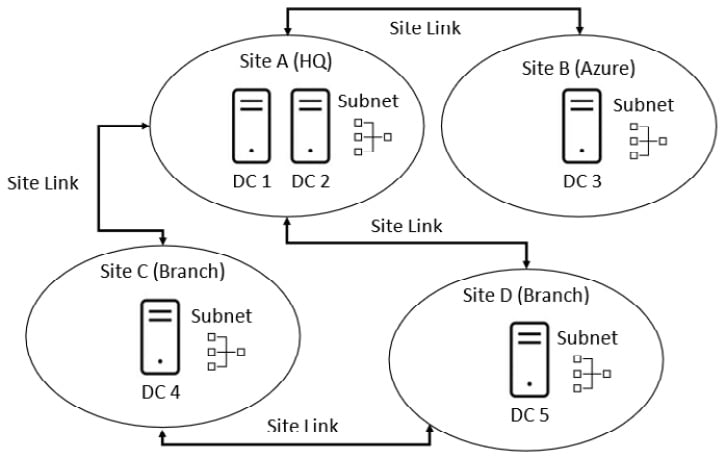
Figure 1.10 – Site topology
By default, there will be a single first site called Default-First-Site-Name (which can be renamed), containing all the subnets where a DC is located. However, in terms of network traffic for replication, user authentication, directory searches, and so on, this is often not an efficient implementation of sites and site design.
A site structure should map to the WAN topology of an organization, and you should create as many sites as needed to replicate this topology. This is to optimize replication so authentication can stay local to the site.
A DC determines its site by looking at the subnet object that matches the subnet that it is part of. After that, it uses the site associated with that subnet to determine the site it belongs to. This means it will control what site a DC belongs to; you must ensure that the DC is located in the subnet associated with that site or that the site contains that subnet.
Site links
Site links are the replication paths between sites; you determine which links the replication traffic goes over. When there is no DC in a client’s local network, site links are used to direct client traffic to a site with a DC; you should consider the reasoning for not having a DC at each location to gain access to domain resources.
It is always recommended to put a DC close to clients who need access to a DC to authenticate resources, perform directory searches, and so on. You shouldn’t have traffic pass over a WAN link but, instead, stay on the local network.
For this purpose, you should always create site design maps for your network topology. In a hybrid environment, this will often require you to go beyond the default and out-of-the-box setup of the single first site design; the default site link used to connect sites is called DEFAULTIPSITELINK.
This section concludes the first of the three skills areas of this chapter – understanding the concepts and components of AD DS. We looked at what AD is and looked at each component. In the next section, we will look at the second of this chapter’s three skills areas: creating AD DS.


