Each of the diverse architectures we'll cover in this book will use different tools to get different results. Take, for instance, the generator loss function from the initial GAN paper by Goodfellow and his associates:
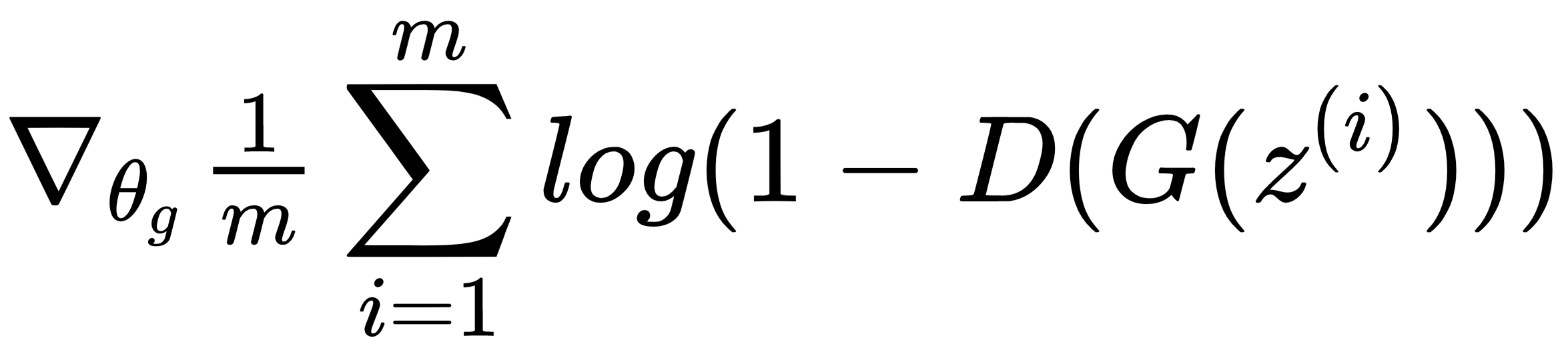
Loss function used with the Generator in adversarial training
This equation simply states that the discriminator is minimizing the log probability that the discriminator is correct. It's part of the adversarial mode of training that occurs. Another thing to consider in this context is that the loss function of the generator does matter. Gradient Saturation, an issue that occurs when the learning gradients are near zero and make learning nearly impossible, can occur for poorly-designed loss functions. The selection of the correct loss function is imperative even for the generator.
Now, let's check out the loss function of the discriminator from the Goodfellow paper:

Standard cross-entropy implementation applied to GANs
This is a standard cross-entropy implementation. Essentially, one of the unique things about this equation is how it is trained through multiple mini-batches. We'll talk about that in a later section in this chapter.
As mentioned before, the discriminator acts as a learned loss function for the overall architecture. When building each of the models though and in paired GAN architectures, it is necessary to have multiple loss functions. In this case, let's define a template class for the loss function in order to store these loss methods:

The class template for loss functions that will be optionally implemented depending on the availability of the lost functions used
During the development of these recipes, we are going to come back to these templates over and over again. A bit of standardization to the code base will go a long way in ensuring that your code remains readable and maintainable.

 Germany
Germany
 Slovakia
Slovakia
 Canada
Canada
 Brazil
Brazil
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 United States
United States
 Great Britain
Great Britain
 India
India
 Spain
Spain
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 France
France
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Australia
Australia
 Japan
Japan
 Russia
Russia






















