






















































The Bellman equation, named after the great computer scientist and applied mathematician Richard E. Bellman, is an optimality condition associated with dynamic programming. It is widely used in RL to update the policy of an agent.
Let's define the following two quantities:
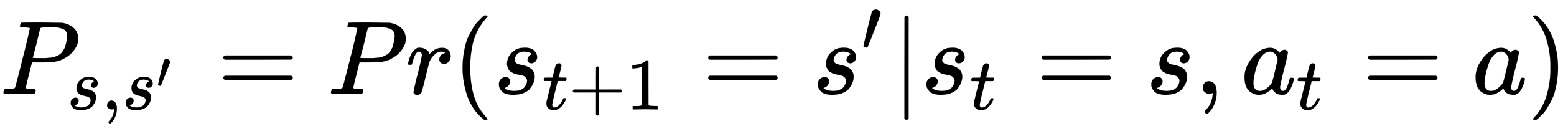
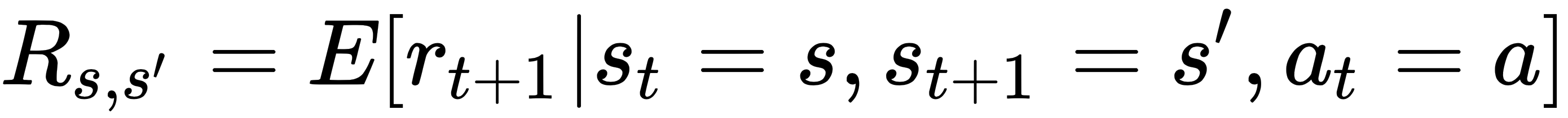
The first quantity, Ps,s', is the transition probability from state s to the new state s'. The second quantity, Rs,s', is the expected reward the agent receives from state s, taking action a, and moving to the new state s'. Note that we have assumed the MDP property, that is, the transition to state at time t+1 only depends on the state and action at time t. Stated in these terms, the Bellman equation is a recursive relationship, and is given by the following equations respectively for the value function and action-value function:
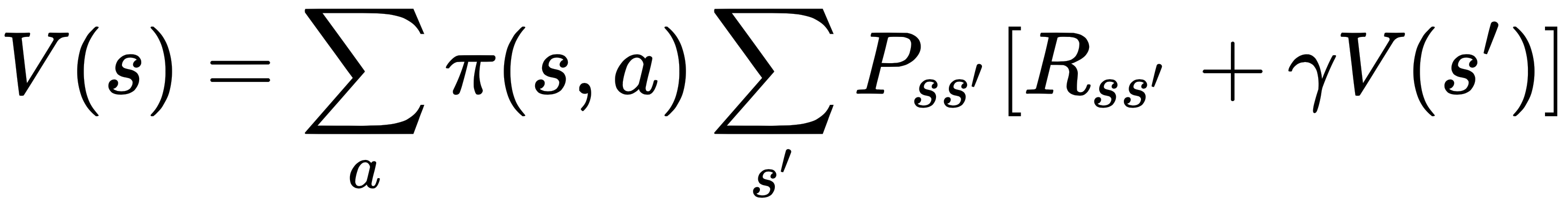
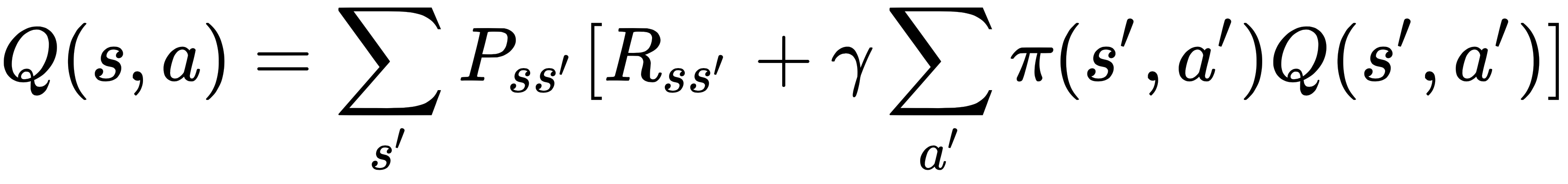
Note that the Bellman equations represent the value function V at a state, and as functions of the value function at other states; similarly for the action-value function Q.




