






















































By definition, the value function of a policy is the expected return (that is, the sum of discounted rewards) of that policy starting from a given state:
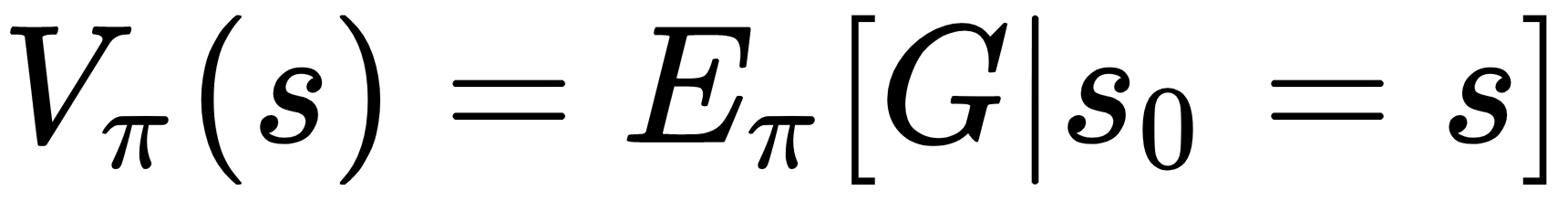
Following the reasoning of Chapter 3, Solving Problems with Dynamic Programming, DP algorithms update state values by computing expectations for all the next states of their values:
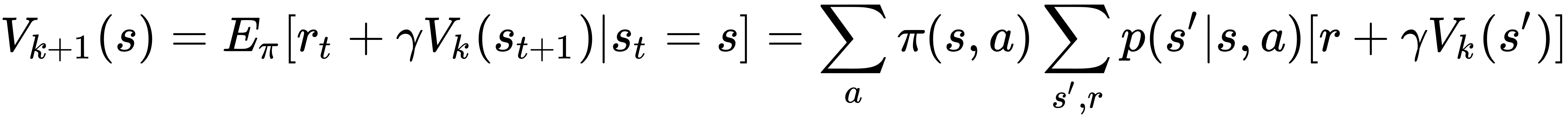
Unfortunately, computing the value function means that you need to know the state transition probabilities. In fact, DP algorithms use the model of the environment to obtain those probabilities. But the major concern is what to do when it's not available. The best answer is to gain all the information by interacting with the environment. If done well, it works because by sampling from the environment a substantial number of times, you should able to approximate the expectation and have a good estimation of the value...




