






















































What is PyTorch?
As mentioned earlier, PyTorch is a tensor computation library that can be powered by GPUs. PyTorch is built with certain goals, which makes it different from all the other deep learning frameworks. During this book, you'll be revisiting these goals through different applications and by the end of the book, you should be able to get started with PyTorch for any sort of use case you have in mind, regardless of whether you are planning to prototype an idea or build a super-scalable model to production.
Being a Python-first framework, PyTorch took a big leap over other frameworks that implemented a Python wrapper on a monolithic C++ or C engine. In PyTorch, you can inherit PyTorch classes and customize as you desire. The imperative style of coding, which was built into the core of PyTorch, was possible only because of the Python-first approach. Even though some symbolic graph frameworks, like TensorFlow, MXNet, and CNTK, came up with an imperative approach, PyTorch has managed to stay on top because of community support and its flexibility.
The tape-based autograd system enables PyTorch to have dynamic graph capability. This is one of the major differences between PyTorch and other popular symbolic graph frameworks. Tape-based autograd powered the backpropagation algorithm of Chainer, autograd, and torch-autograd as well. With dynamic graph capability, your graph gets created as the Python interpreter reaches the corresponding line. This is called define by run, unlike TensorFlow's define and run approach.
Tape-based autograd uses reverse-mode automatic differentiation, where the graph saves each operation to the tape while you forward pass and then move backward through the tape for backpropagation. Dynamic graphs and a Python-first approach allow easy debugging, where you can use the usual Python debuggers like Pdb or editor-based debuggers.
The PyTorch core community did not just make a Python wrapper over Torch's C binary: it optimized the core and made improvements to the core. PyTorch intelligently chooses which algorithm to run for each operation you define, based on the input data.
Installing PyTorch
If you have CUDA and CuDNN installed, PyTorch installation is dead simple (for GPU support, but in case you are trying out PyTorch and don't have GPUs with you, that's fine too). PyTorch's home page [2] shows an interactive screen to select the OS and package manager of your choice. Choose the options and execute the command to install it.
Though initially the support was just for Linux and Mac operating systems, from PyTorch 0.4 Windows is also in the supported operating system list. PyTorch has been packaged and shipped to PyPI and Conda. PyPI is the official Python repository for packages and the package manager, pip, can find PyTorch under the name Torch.
However, if you want to be adventurous and get the latest code, you can install PyTorch from the source by following the instructions on the GitHub README page. PyTorch has a nightly build that is being pushed to PyPI and Conda as well. A nightly build is useful if you want to get the latest code without going through the pain of installing from the source.
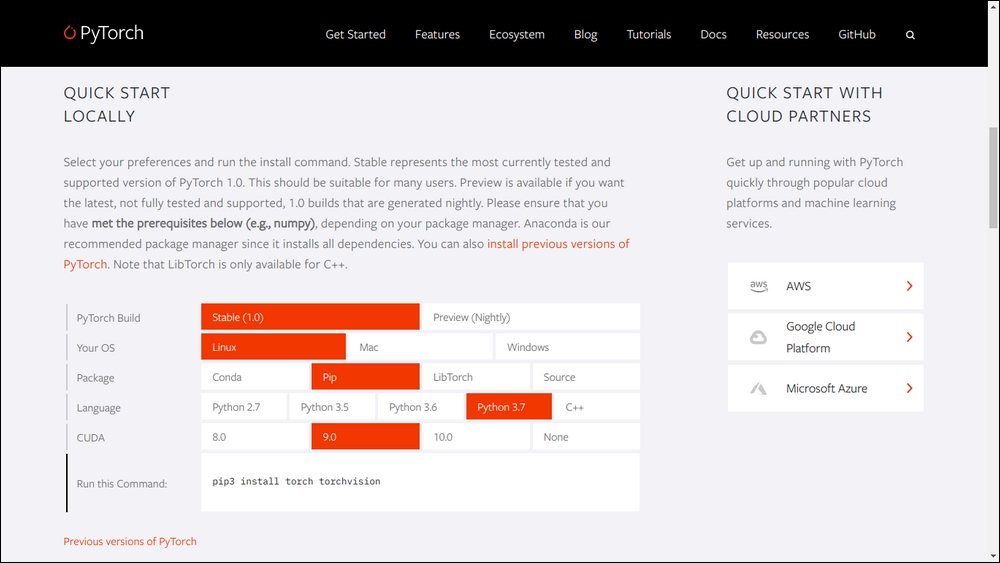
Figure 1.1: The installation process in the interactive UI from the PyTorch website
What makes PyTorch popular?
Among the multitude of reliable deep learning frameworks, static graphs or the symbolic graph-based approach were being used by almost everyone because of the speed and efficiency. The inherent problems with the dynamic network, such as performance issues, prevented developers from spending a lot of time implementing one. However, the restrictions of static graphs prevented researchers from thinking of a multitude of different ways to attack a problem because the thought process had to be confined inside the box of static computational graphs.
As mentioned earlier, Harvard's Autograd package started as a solution for this problem, and then the Torch community adopted this idea from Python and implemented torch-autograd. Chainer and CMU's DyNet are probably the next two dynamic-graph-based frameworks that got huge community support. Although all these frameworks could solve the problems that static graphs had created with the help of the imperative approach, they didn't have the momentum that other popular static graph frameworks had. PyTorch was the absolute answer for this. The PyTorch team took the backend of the well-tested, renowned Torch framework and merged that with the front of Chainer to get the best mix. The team optimized the core, added more Pythonic APIs, and set up the abstraction correctly, such that PyTorch doesn't need an abstract library like Keras for beginners to get started.
PyTorch achieved wide acceptance in the research community because a majority of people were using Torch already and probably were frustrated by the way frameworks like TensorFlow evolved without giving much flexibility. The dynamic nature of PyTorch was a bonus for lots of people and helped them to accept PyTorch in its early stages.
PyTorch lets users define whatever operations Python allows them to in the forward pass. The backward pass automatically finds the way through the graph until the root node, and calculates the gradient while traversing back. Although it was a revolutionary idea, the product development community had not accepted PyTorch, just like they couldn't accept other frameworks that followed similar implementation. However, as the days passed, more and more people started migrating to PyTorch. Kaggle witnessed competitions where all the top rankers used PyTorch, and as mentioned earlier, universities started doing courses in PyTorch. This helped students to avoid learning a new graph language like they had to when using a symbolic graph-based framework.
After the announcement of Caffe2, even product developers started experimenting with PyTorch, since the community announced the migration strategy of PyTorch models to Caffe2. Caffe2 is a static graph framework that can run your model even in mobile phones, so using PyTorch for prototyping is a win-win approach. You get the flexibility of PyTorch while building the network, and you get to transfer it to Caffe2 and use it in any production environment. However, with the 1.0 release note, the PyTorch team made a huge jump from letting people learn two frameworks (one for production and one for research), to learning a single framework that has dynamic graph capability in the prototyping phase and can suddenly convert to a static-like optimized graph when it requires speed and efficiency. The PyTorch team merged the backend of Caffe2 with PyTorch's Aten backend, which let the user decide whether they wanted to run a less-optimized but highly flexible graph, or an optimized but less-flexible graph without rewriting the code base.
ONNX and DLPack were the next two "big things" that the AI community saw. Microsoft and Facebook together announced the Open Neural Network Exchange (ONNX) protocol, which aims to help developers to migrate any model from any framework to any other. ONNX is compatible with PyTorch, Caffe2, TensorFlow, MXNet, and CNTK and the community is building/improving the support for almost all the popular frameworks.
ONNX is built into the core of PyTorch and hence migrating a model to ONNX form doesn't require users to install any other package or tool. Meanwhile, DLPack is taking interoperability to the next level by defining a standard data structure that different frameworks should follow, so that the migration of a tensor from one framework to another, in the same program, doesn't require the user to serialize data or follow any other workarounds. For instance, if you have a program that can use a well-trained TensorFlow model for computer vision and a highly efficient PyTorch model for recurrent data, you could use a single program that could handle each of the three-dimensional frames from a video with the TensorFlow model and pass the output of the TensorFlow model directly to the PyTorch model to predict actions from the video. If you take a step back and look at the deep learning community, you can see that the whole world converges toward a single point where everything is interoperable with everything else and trying to approach problems with similar methods. That's a world we all want to live in.




