






















































Goroutines
First, some basics.
A process is an instance of a program with certain dedicated resources, such as memory space, processor time, file handles (for example, most processes in Linux have stdin, stdout, and stderr), and at least one thread. We call it an instance because the same program can be used to create many processes. In most general-purpose operating systems, every process is isolated from the others, so any two processes that wish to communicate have to do it through well-defined inter-process communication utilities. When a process terminates, all the memory allocated for the process is freed, all open files are closed, and all threads are terminated.
A thread is an execution context that contains all the resources required to run a sequence of instructions. Usually, this contains a stack and the values of processor registers. The stack is necessary to keep the sequence of nested function calls within that thread, as well as to store values declared in the functions executing in that thread. A given function may execute in many different threads, so the local variables used when that function runs in a thread are stored in the stack of that thread. A scheduler allocates processor time to threads. Some schedulers are preemptive and can stop a thread at any time to switch to another thread. Some schedulers are collaborative and have to wait for the thread to yield to switch to another one. A thread is usually managed by the operating system.
A goroutine is an execution context that is managed by the Go runtime (as opposed to a thread that is managed by the operating system). A goroutine usually has a much smaller startup overhead than an operating system thread. A goroutine starts with a small stack that grows as needed. Creating new goroutines is faster and cheaper than creating operation system threads. The Go scheduler assigns operating system threads to run goroutines.
In a Go program, goroutines are created using the go keyword followed by a function call:
go f()
go g(i,j)
go func() {
...
}()
go func(i,j int) {
...
}(1,2)
The go keyword starts the given function in a new goroutine. The existing goroutine continues running concurrently with the newly created goroutine. The function running as a goroutine can take parameters, but it cannot return a value. The parameters of the goroutine function are evaluated before the goroutine starts and passed to the function once the goroutine starts running.
You may ask why there was a need to develop a completely new threading system. Just to get lightweight threads? Goroutines are more than just lightweight threads. They are the key to increasing throughput by efficiently sharing processing power among goroutines that are ready to run. Here’s the gist of the idea.
The number of operating system threads used by the Go runtime is equal to the number of processors/cores on the platform (unless you change this by setting the GOMAXPROCS environment variable or by calling the runtime.GOMAXPROCS function). This is the number of things the platform can do in parallel. Anything more than that and the operating system will have to resort to time sharing. With GOMAXPROCS threads running in parallel, there is no context-switching overhead at the operating system level. The Go scheduler assigns goroutines to operating system threads to get more work on each thread as opposed to doing less work on many threads. The smaller context switching is not the only reason why the Go scheduler performs better than the operating system scheduler. The Go scheduler performs better because it knows which goroutines to wake up to get more out of them. The operating system does not know about channel operations or mutexes, which are all managed in the user space by the Go runtime.
There are some more subtle differences between threads and goroutines. Threads usually have priorities. When a low-priority thread competes with a high-priority thread for a shared resource, the high-priority thread has a better chance of getting it. Goroutines do not have pre-assigned priorities. That said, the language specification allows for a scheduler that favors certain goroutines. For example, later versions of the Go runtime include scheduling algorithms that will select starving goroutines. In general, though, a correct concurrent Go program should not rely on scheduling behavior. Many languages have facilities such as thread pools with configurable scheduling algorithms. These facilities are developed based on the assumption that thread creation is an expensive operation, which is not the case for Go. Another difference is how goroutines stacks are managed. A goroutine starts with a small stack (Go runtimes after 1.19 use a historical average, earlier versions use 2K), and every function call checks whether the remaining stack space is sufficient. If not, the stack is resized. An operation system thread usually starts with a much larger stack (in the order of megabytes) that usually does not grow.
The Go runtime starts several goroutines when a program starts. Exactly how many depends on the implementation and may change between versions. However, there is at least one for the garbage collector and another for the main goroutine. The main goroutine simply calls the main function and terminates the program when it returns. When main returns and the program exits, all running goroutines terminate abruptly, mid-function, without a chance to perform any cleanup.
Let’s look at what happens when we create a goroutine:
func f() {
fmt.Println("Hello from goroutine")
}
func main() {
go f()
fmt.Println("Hello from main")
time.Sleep(100)
}
This program starts with the main goroutine. When the go f() statement is run, a new goroutine is created. Remember, a goroutine is an execution context, which means the go keyword causes the runtime to allocate a new stack and set it up to run the f() function. Then this goroutine is marked as ready to run. The main goroutine continues running without waiting for f() to be called, and prints Hello from main to console. Then it waits for 100 milliseconds. During this time, the new goroutine may start running, call f(), and print Hello from goroutine. fmt.Println has mutual exclusion built in to ensure that the two goroutines do not corrupt each other’s outputs.
This program can output one of the following options:
Hello from main, thenHello from goroutine: This is the case when the main goroutine first prints the output, then the goroutine prints it.Hello from goroutine, thenHello from main: This is the case when the goroutine created inmain()runs first, and then the main goroutine prints the output.Hello from main: This is the case when the main goroutine continues running, but the new goroutine never finds a chance to run in the given 100 milliseconds, causingmainto return. Oncemainreturns, the program terminates without the goroutine ever finding a chance to run. It is unlikely that this case is observable, but it is possible.
Functions that take arguments can run as goroutines:
func f(s string) {
fmt.Printf("Goroutine %s\n", s)
}
func main() {
for _, s := range []string{"a", "b", "c"} {
go f(s)
}
time.Sleep(100)
}
Every run of this program is likely to print out a, b, and c in random order. This is because the for loop creates three goroutines, each called with the current value of s, and they can run in any order the scheduler picks them. Of course, if all goroutines do not finish within the given 100 milliseconds, some strings may be missing from the output.
Naturally, this can be done with an anonymous function as well. But now, things get interesting:
func main() {
for _, s := range []string{"a", "b", "c"} {
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
}
time.Sleep(100)
}
Here’s the output:
Goroutine c Goroutine c Goroutine c
So, what is going on here?
First, this is a data race, because there is a shared variable that is written by one goroutine and read by three others without any synchronization. This becomes more evident if we unroll the for loop, as follows:
func main() {
var s string
s = "a"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
s = "b"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
s = "c"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
time.Sleep(100)
}
In this example, each anonymous function is a closure. We are running three goroutines, each with a closure that captures the s variable from the enclosing scope. Because of that, we have three goroutines that read the shared s variable, and one goroutine (the main goroutine) writing to it concurrently. This is a data race. In the preceding run, all three goroutines ran after the last assignment to s. There are other possible runs. In fact, this program may even run correctly and print the expected output.
That is the danger of data races. A program such as this rarely runs correctly, so it is easy to diagnose and fix before code is deployed in a production environment. The data races that rarely give the wrong output usually make it to production and cause a lot of trouble.
Let’s look at how closures work in more detail. They are the cause of many misunderstandings in Go development because simply refactoring a declared function as an anonymous function may have unexpected consequences.
A closure is a function with a context that includes some variables included in its enclosing scope. In the preceding example, there are three closures, and each closure captures the s variable from their scope. The scope defines all symbol names accessible at a given point in a program. In Go, the scope is determined syntactically, so where we declare the anonymous function, the scope includes all the exported functions, variables, type names, the main function, and the s variable. The Go compiler analyzes the source code to determine whether a variable defined in a function may be referenced after that function returns. This is the case when, for instance, you pass a pointer to a variable defined in one function to another function. Or when you assign a global pointer variable to a variable defined in a function. Once the function declaring that variable returns, the global variable will be pointing to a stale memory location. Stack locations come and go as functions enter and return. When such a situation is detected (or even a potential for such a situation is detected, such as creating a goroutine or calling another function), the variable escapes to the heap. That is, instead of allocating that variable on the stack, the compiler allocates the variable dynamically on the heap, so even if the variable leaves scope, its contents remain accessible. This is exactly what is happening in our example. The s variable escapes to the heap because there are goroutines that can continue running and accessing that variable even after main returns. This situation is depicted in Figure 2.1:
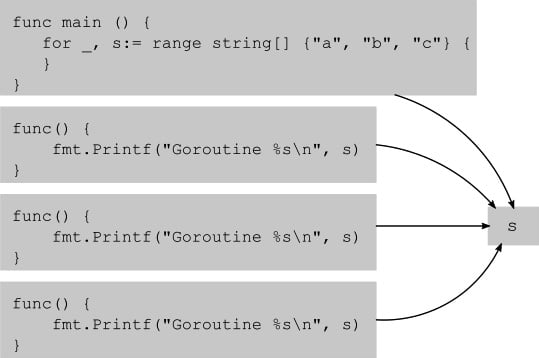
Figure 2.1 – Closures
Closures as goroutines can be a very powerful tool, but they must be used carefully. Most closures running as goroutines share memory, so they are prone to races.
We can fix our program by creating a copy of the s variable at each iteration. The first iteration sets s to "a". We create a copy of it and capture that copy in the closure. Then the next iteration sets s to "b". This is fine because the closure created during the first iteration is still using "a". We create a new copy of s, this time with a value of "b", and this goes on. This is shown in the following code:
for _, s := range []string{"a", "b", "c"} {
s:=s // Redeclare s, create a copy
// Here, the redeclared s shadows the loop variable s
go func() {…}
}
Another way is to pass it as a parameter:
for _, s := range []string{"a", "b", "c"} {
go func(s string) {
fmt.Printf("Goroutine %s\n", s)
}(s) // This will pass a copy of s to the function
}
In either solution, the s loop variable no longer escapes to the heap, because a copy of it is captured. In the first solution using a redeclared variable, the copy escapes to the heap, but the s loop variable doesn’t.
One of the frequently asked questions regarding goroutines is: how do we stop a running goroutine? There is no magic function that will terminate or pause a goroutine. If you want to stop a goroutine, you have to send some message or set a flag shared with the goroutine, and the goroutine either has to respond to the message or read the shared variable and return. If you want to pause it, you have to use one of the synchronization mechanisms to block it. This fact causes some anxiety among developers who cannot find an effective way to terminate their goroutines. However, this is one of the realities of concurrent programming. The ability to create concurrent execution blocks is only one part of the problem. Once created, you have to be mindful of how to terminate them responsibly.
A panic can terminate a goroutine. If a panic happens in a goroutine, it is propagated up the call stack until a recover is found, or until the goroutine returns. This is called stack unwinding. If a panic is not handled, a panic message will be printed and the program will crash.
Before closing this topic, it might be helpful to talk about how Go runtime manages goroutines. Go uses an M:N scheduler that runs M goroutines on N OS threads. Internally, the Go runtime keeps track of the OS threads and the goroutines. When an OS thread is ready to execute a goroutine, the scheduler selects one that is ready to run and assigns it to the thread. The OS thread runs that goroutine until it blocks, yields, or is preempted. There are several ways a goroutine can be blocked. Blocking by channel operations or mutexes is managed by the Go runtime. If the goroutine is blocked because of a synchronous I/O operation, then the thread running that goroutine will also be blocked (this is managed by the operating system). In this case, the Go runtime starts a new thread or uses one already available and continues operation. When the OS thread unblocks (that is, the I/O operation ends), the thread is put back into use or returned to the thread pool. The Go runtime limits the number of active OS threads running user goroutines with the GOMAXPROCS variable. However, there is no limit on the number of OS threads waiting for I/O operations. So, the actual OS thread count a Go program uses can be much higher than GOMAXPROCS. However, only GOMAXPROCS of those threads would be executing user goroutines.
Figure 2.2 illustrates this. Suppose GOMAXPROCS=2. Thread 1 and Thread 2 are operating system threads that are executing goroutines. Goroutine G1, which is running on Thread 1, performs a synchronous I/O operation, blocking Thread 1. Since Thread 1 is no longer operational, the Go runtime allocates Thread 3 and continues running goroutines. Note that even though there are three operating system threads, there are two active threads and one blocked thread. When the system call running on Thread 1 completes, the goroutine G1 becomes runnable again, but there is one extra thread now. The Go runtime continues running with Thread 3 and stops using Thread 1.
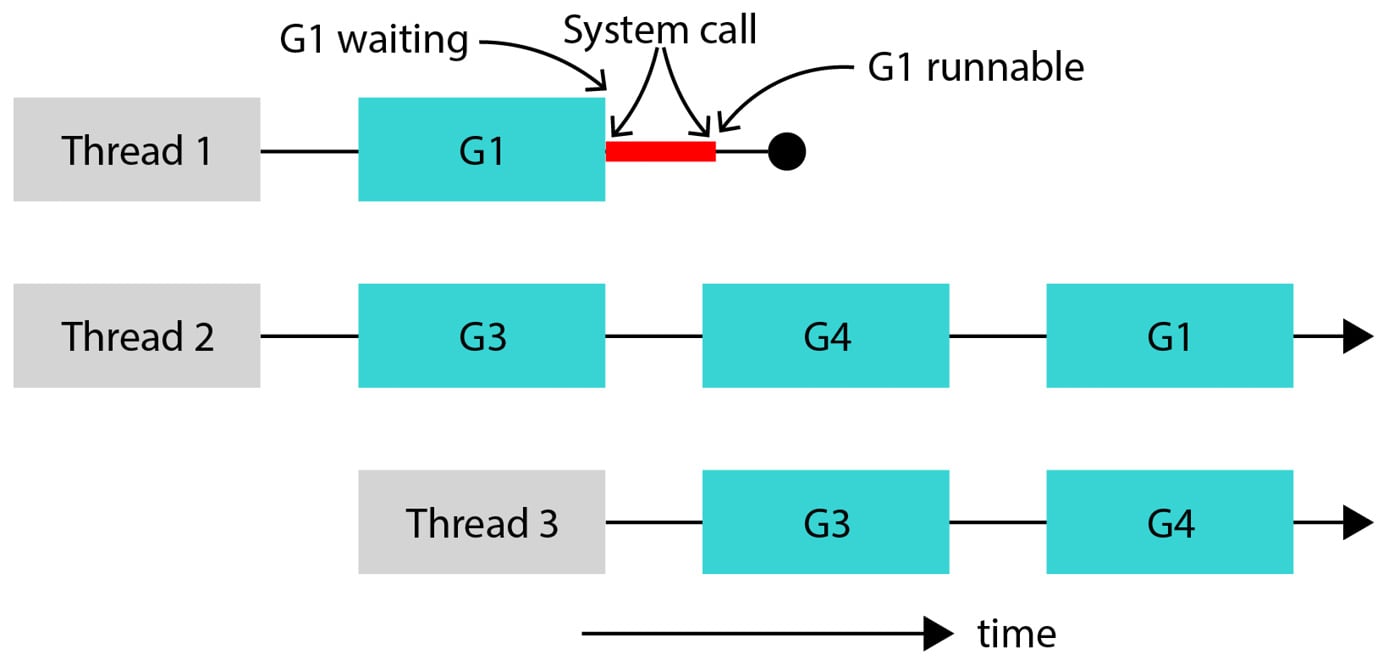
Figure 2.2 – System calls block OS threads
A similar process happens for asynchronous I/O operations, such as network operations and some file operations on certain platforms. However, instead of blocking a thread for a system call, the goroutine is blocked, and a netpoller thread is used to wait for asynchronous events. When the netpoller receives events, it wakes up the relevant goroutines.



