






















































Recurrent neural networks (RNNs) are useful in processing sequential or temporal data, where the data at a given instance or position is highly correlated with the data in the previous time steps or positions. RNNs have already been very successful at processing text data, since a word at a given instance is highly correlated with the words preceding it. In an RNN, at each time step, the network performs the same function, hence, the term recurrent in its name. The architecture of an RNN is illustrated in the following diagram:
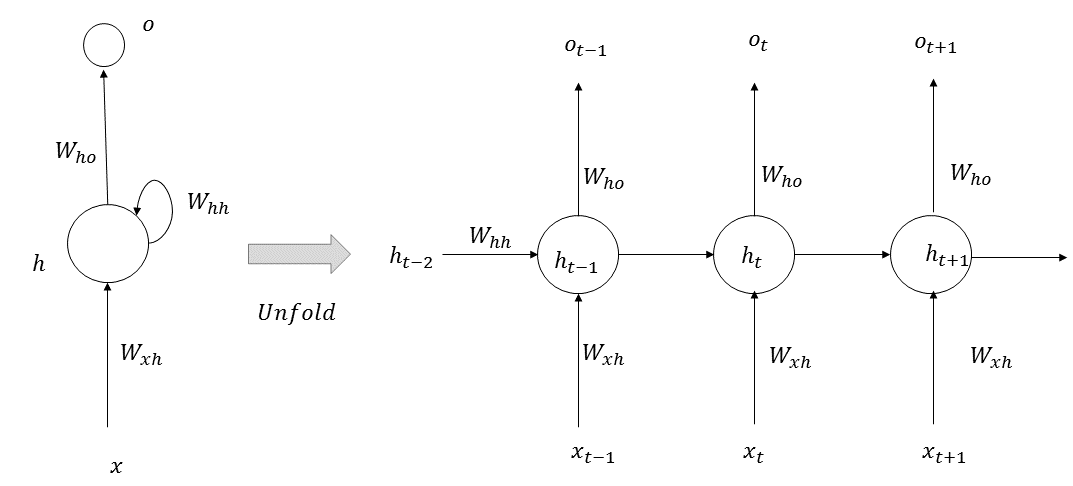
At each given time step, t, a memory state, ht, is computed, based on the previous state, ht-1, at step (t-1) and the input, xt, at time step t. The new state, ht, is used to predict the output, ot, at step t. The equations governing RNNs are as follows:
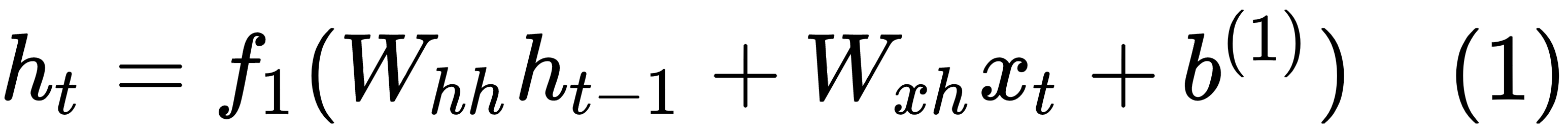
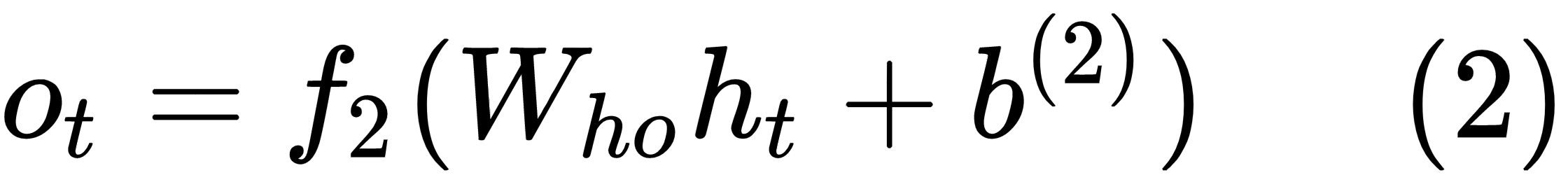
If we are predicting the next word in a sentence, then the function f2 is generally a softmax function over the words in the vocabulary. The function f1 can be any activation function based on the problem at hand.
In an RNN, an output error in step t tries to correct the prediction in the previous time steps, generalized by k ∈ 1, 2, . . . t-1, by propagating the error in the previous time steps. This helps the RNN to learn about long dependencies between words that are far apart from each other. In practice, it isn't always possible to learn such long dependencies through RNN because of the vanishing and exploding gradient problems.
As you know, neural networks learn through gradient descent, and the relationship of a word in time step t with a word at a prior sequence step k can be learned through the gradient of the memory state  with respect to the gradient of the memory state
with respect to the gradient of the memory state  ∀ i. This is expressed in the following formula:
∀ i. This is expressed in the following formula:

If the weight connection from the memory state  at the sequence step k to the memory state
at the sequence step k to the memory state  at the sequence step (k+1) is given by uii ∈ Whh, then the following is true:
at the sequence step (k+1) is given by uii ∈ Whh, then the following is true:
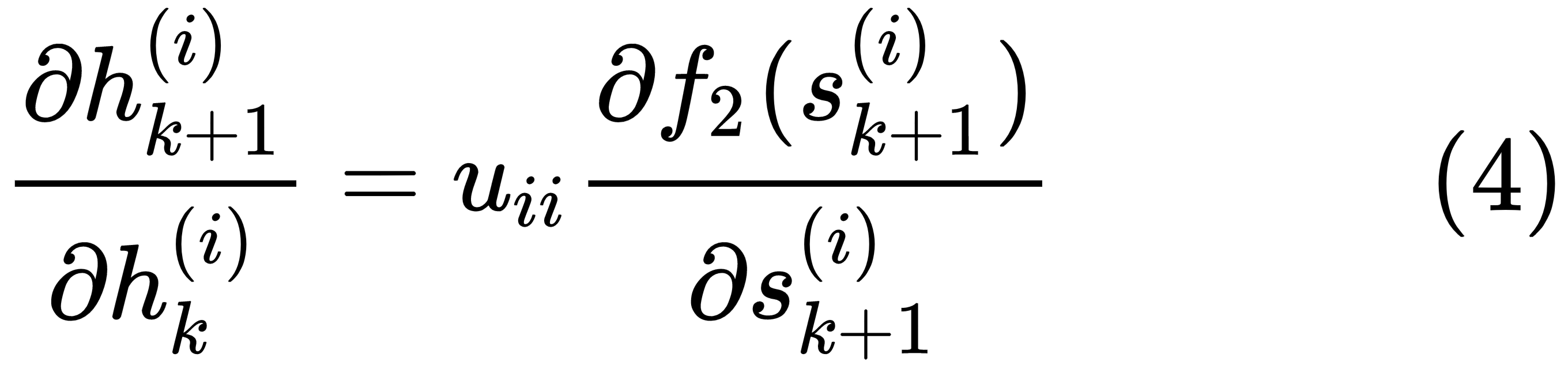
In the preceding equation,  is the total input to the memory state i at the time step (k+1), such that the following is the case:
is the total input to the memory state i at the time step (k+1), such that the following is the case:

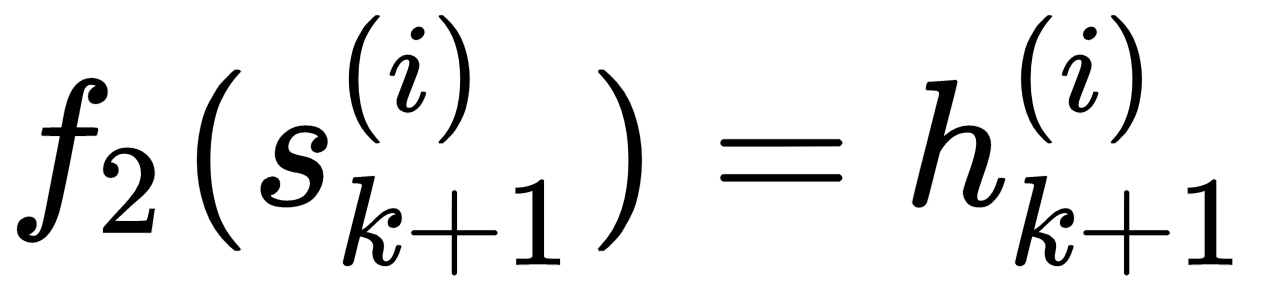
Now that we have everything in place, it's easy to see why the vanishing gradient problem may occur in an RNN. From the preceding equations, (3) and (4), we get the following:
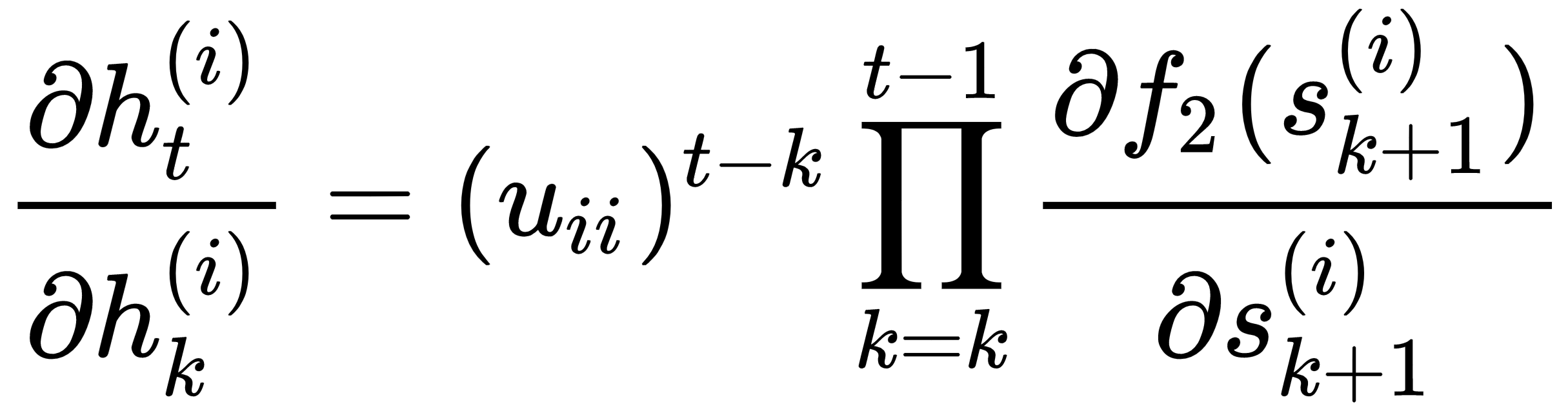
For RNNs, the function f2 is generally sigmoid or tanh, which suffers from the saturation problem of having low gradients beyond a specified range of values for the input. Now, since the f2 derivatives are multiplied with each other, the gradient  can become zero if the input to the activation functions is operating at the saturation zone, even for relatively moderate values of (t-k). Even if the f2 functions are not operating in the saturation zone, the gradients of the f2 function for sigmoids are always less than 1, and so it is very difficult to learn distant dependencies between words in a sequence. Similarly, there might be exploding gradient problems stemming from the factor
can become zero if the input to the activation functions is operating at the saturation zone, even for relatively moderate values of (t-k). Even if the f2 functions are not operating in the saturation zone, the gradients of the f2 function for sigmoids are always less than 1, and so it is very difficult to learn distant dependencies between words in a sequence. Similarly, there might be exploding gradient problems stemming from the factor  . Suppose that the distance between steps t and k is around 10, while the weight, uii, is around two. In such cases, the gradient would be magnified by a factor of two, 210 = 1024, leading to the exploding gradient problem.
. Suppose that the distance between steps t and k is around 10, while the weight, uii, is around two. In such cases, the gradient would be magnified by a factor of two, 210 = 1024, leading to the exploding gradient problem.



 , is expressed as follows:
, is expressed as follows: 



 in LSTM is given by
in LSTM is given by  , which can be expressed in a product form as follows:
, which can be expressed in a product form as follows:


 , becomes the following:
, becomes the following: 






