






















































Spark requires a handful of environments to be present on your machine before you can install and use it. In this recipe, we will focus on getting your machine ready for Spark installation.
Installing Spark requirements
Getting ready
To execute this recipe, you will need a bash Terminal and an internet connection.
Also, before we start any work, you should clone the GitHub repository for this book. The repository contains all the codes (in the form of notebooks) and all the data you will need to follow the examples in this book. To clone the repository, go to http://bit.ly/2ArlBck, click on the Clone or download button, and copy the URL that shows up by clicking on the icon next to it:
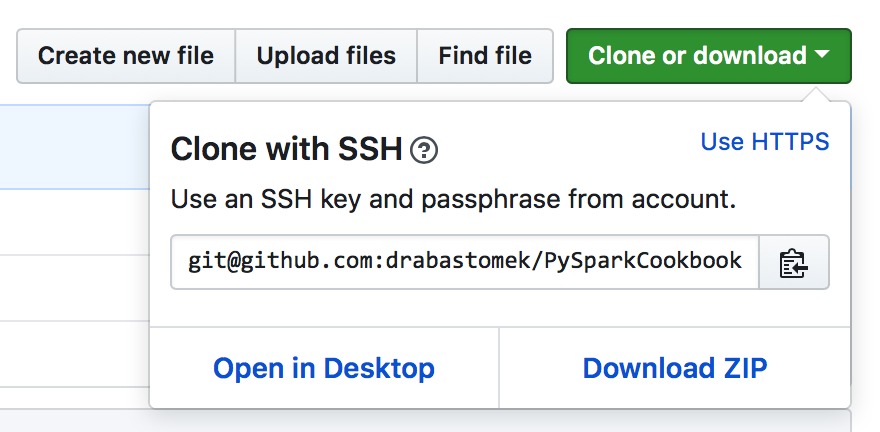
Next, go to your Terminal and issue the following command:
git clone [email protected]:drabastomek/PySparkCookbook.git
If your git environment is set up properly, the whole GitHub repository should clone to your disk. No other prerequisites are required.
How to do it...
There are just truly two main requirements for installing PySpark: Java and Python. Additionally, you can also install Scala and R if you want to use those languages, and we will also check for Maven, which we will use to compile the Spark sources.
To do this, we will use the checkRequirements.sh script to check for all the requirements: the script is located in the Chapter01 folder from the GitHub repository.
The following code block shows the high-level portions of the script found in the Chapter01/checkRequirements.sh file. Note that some portions of the code were omitted here for brevity:
#!/bin/bash
# Shell script for checking the dependencies
#
# PySpark Cookbook
# Author: Tomasz Drabas, Denny Lee
# Version: 0.1
# Date: 12/2/2017
_java_required=1.8
_python_required=3.4
_r_required=3.1
_scala_required=2.11
_mvn_required=3.3.9
# parse command line arguments
_args_len="$#"
...
printHeader
checkJava
checkPython
if [ "${_check_R_req}" = "true" ]; then
checkR
fi
if [ "${_check_Scala_req}" = "true" ]; then
checkScala
fi
if [ "${_check_Maven_req}" = "true" ]; then
checkMaven
fi
How it works...
First, we will specify all the required packages and their required minimum versions; looking at the preceding code, you can see that Spark 2.3.1 requires Java 1.8+ and Python 3.4 or higher (and we will always be checking for these two environments). Additionally, if you want to use R or Scala, the minimal requirements for these two packages are 3.1 and 2.11, respectively. Maven, as mentioned earlier, will be used to compile the Spark sources, and for doing that, Spark requires at least the 3.3.9 version of Maven.
You can check the Spark requirements here: https://spark.apache.org/docs/latest/index.html
You can check the requirements for building Spark here: https://spark.apache.org/docs/latest/building-spark.html.
You can check the requirements for building Spark here: https://spark.apache.org/docs/latest/building-spark.html.
Next, we parse the command-line arguments:
if [ "$_args_len" -ge 0 ]; then
while [[ "$#" -gt 0 ]]
do
key="$1"
case $key in
-m|--Maven)
_check_Maven_req="true"
shift # past argument
;;
-r|--R)
_check_R_req="true"
shift # past argument
;;
-s|--Scala)
_check_Scala_req="true"
shift # past argument
;;
*)
shift # past argument
esac
done
fi
You, as a user, can specify whether you want to check additionally for R, Scala, and Maven dependencies. To do so, run the following code from your command line (the following code will check for all of them):
./checkRequirements.sh -s -m -r
The following is also a perfectly valid usage:
./checkRequirements.sh --Scala --Maven --R
Next, we call three functions: printHeader, checkJava, and checkPython. The printHeader function is nothing more than just a simple way for the script to state what it does and it really is not that interesting, so we will skip it here; it is, however, fairly self-explanatory, so you are welcome to peruse the relevant portions of the checkRequirements.sh script yourself.
Next, we will check whether Java is installed. First, we just print to the Terminal that we are performing checks on Java (this is common across all of our functions, so we will only mention it here):
function checkJava() {
echo
echo "##########################"
echo
echo "Checking Java"
echo
Following this, we will check if the Java environment is installed on your machine:
if type -p java; then
echo "Java executable found in PATH"
_java=java
elif [[ -n "$JAVA_HOME" ]] && [[ -x "$JAVA_HOME/bin/java" ]]; then
echo "Found Java executable in JAVA_HOME"
_java="$JAVA_HOME/bin/java"
else
echo "No Java found. Install Java version $_java_required or higher first or specify JAVA_HOME variable that will point to your Java binaries."
exit
fi
First, we use the type command to check if the java command is available; the type -p command returns the location of the java binary if it exists. This also implies that the bin folder containing Java binaries has been added to the PATH.
If you are certain you have the binaries installed (be it Java, Python, R, Scala, or Maven), you can jump to the Updating PATH section in this recipe to see how to let your computer know where these binaries live.
If this fails, we will revert to checking if the JAVA_HOME environment variable is set, and if it is, we will try to see if it contains the required java binary: [[ -x "$JAVA_HOME/bin/java" ]]. Should this fail, the program will print the message that no Java environment could be found and will exit (without checking for other required packages, like Python).
If, however, the Java binary is found, then we can check its version:
_java_version=$("$_java" -version 2>&1 | awk -F '"' '/version/ {print $2}')
echo "Java version: $_java_version (min.: $_java_required)"
if [[ "$_java_version" < "$_java_required" ]]; then
echo "Java version required is $_java_required. Install the required version first."
exit
fi
echo
We first execute the java -version command in the Terminal, which would normally produce an output similar to the following screenshot:

We then pipe the previous output to awk to split (the -F switch) the rows at the quote '"' character (and will only use the first line of the output as we filter the rows down to those that contain /version/) and take the second (the $2) element as the version of the Java binaries installed on our machine. We will store it in the _java_version variable, which we also print to the screen using the echo command.
If you do not know what awk is or how to use it, we recommend this book from Packt: http://bit.ly/2BtTcBV.
Finally, we check if the _java_version we just obtained is lower than _java_required. If this evaluates to true, we will stop the execution, instead telling you to install the required version of Java.
The logic implemented in the checkPython, checkR, checkScala, and checkMaven functions follows in a very similar way. The only differences are in what binary we call and in the way we check the versions:
- For Python, we run "$_python" --version 2>&1 | awk -F ' ' '{print $2}', as checking the Python version (for Anaconda distribution) would print out the following to the screen: Python 3.5.2 :: Anaconda 2.4.1 (x86_64)
- For R, we use "$_r" --version 2>&1 | awk -F ' ' '/R version/ {print $3}', as checking the R's version would write (a lot) to the screen; we only use the line that starts with R version: R version 3.4.2 (2017-09-28) -- "Short Summer"
- For Scala, we utilize "$_scala" -version 2>&1 | awk -F ' ' '{print $5}', given that checking Scala's version prints the following: Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
- For Maven, we check "$_mvn" --version 2>&1 | awk -F ' ' '/Apache Maven/ {print $3}', as Maven prints out the following (and more!) when asked for its version: Apache Maven 3.5.2 (138edd61fd100ec658bfa2d307c43b76940a5d7d; 2017-10-18T00:58:13-07:00)
If you want to learn more, you should now be able to read the other functions with ease.
There's more...
If any of your dependencies are not installed, you need to install them before continuing with the next recipe. It goes beyond the scope of this book to guide you step-by-step through the installation process of all of these, but here are some helpful links to show you how to do it.
Installing Java
Installing Java is pretty straightforward.
On macOS, go to https://www.java.com/en/download/mac_download.jsp and download the version appropriate for your system. Once downloaded, follow the instructions to install it on your machine. If you require more detailed instructions, check this link: http://bit.ly/2idEozX.
On Linux, check the following link http://bit.ly/2jGwuz1 for Linux Java installation instructions.
Installing Python
We have been using (and highly recommend) the Anaconda version of Python as it comes with the most commonly used packages included with the installer. It also comes built-in with the conda package management tool that makes installing other packages a breeze.
You can download Anaconda from http://www.continuum.io/downloads; select the appropriate version that will fulfill Spark's requirements. For macOS installation instructions, you can go to http://bit.ly/2zZPuUf and for a Linux installation manual check, you can go to http://bit.ly/2ASLUvg.
Installing R
R is distributed via Comprehensive R Archive Network (CRAN). The macOS version can be downloaded from here, https://cran.r-project.org/bin/macosx/, whereas the Linux one is available here: https://cran.r-project.org/bin/linux/.
Download the version appropriate for your machine and follow the installation instructions on the screen. For the macOS version, you can choose to install just the R core packages without the GUI and everything else as Spark does not require those.
Installing Scala
Installing Scala is even simpler.
Go to http://bit.ly/2Am757R and download the sbt-*.*.*.tgz archive (at the time of writing this book, the latest version is sbt-1.0.4.tgz). Next, in your Terminal, navigate to the folder you have just downloaded Scala to and issue the following commands:
tar -xvf sbt-1.0.4.tgz
sudo mv sbt-1.0.4/ /opt/scala/
That's it. Now, you can skip to the Updating PATH section in this recipe to update your PATH.
Installing Maven
Maven's installation is quite similar to that of Scala. Go to https://maven.apache.org/download.cgi and download the apache-maven-*.*.*-bin.tar.gz archive. At the time of writing this book, the newest version was 3.5.2. Similarly to Scala, open the Terminal, navigate to the folder you have just downloaded the archive to, and type:
tar -xvf apache-maven-3.5.2-bin.tar.gz sudo mv apache-maven-3.5.2-bin/ /opt/apache-maven/
Once again, that is it for what you need to do with regards to installing Maven. Check the next subsection for instructions on how to update your PATH.
Updating PATH
Unix-like operating systems (Windows, too) use the concept of a PATH to search for binaries (or executables, in the case of Windows). The PATH is nothing more than a list of folders separated by the colon character ':' that tells the operating system where to look for binaries.
To add something to your PATH (and make it a permanent change), you need to edit either the .bash_profile (macOS) or .bashrc (Linux) files; these are located in the root folder for your user. Thus, to add both Scala and Maven binaries to the PATH, you can do the following (on macOS):
cp ~/.bash_profile ~/.bash_profile_old # make a copy just in case echo export SCALA_HOME=/opt/scala >> ~/.bash_profile echo export MAVEN_HOME=/opt/apache-maven >> ~/.bash_profile echo PATH=$SCALA_HOME/bin:$MAVEN_HOME/bin:$PATH >> ~/.bash_profile
On Linux, the equivalent looks as follows:
cp ~/.bashrc ~/.bashrc_old # make a copy just in case echo export SCALA_HOME=/opt/scala >> ~/.bashrc echo export MAVEN_HOME=/opt/apache-maven >> ~/.bashrc echo PATH=$SCALA_HOME/bin:$MAVEN_HOME/bin:$PATH >> ~/.bashrc
The preceding commands simply append to the end of either of the .bash_profile or .bashrc files using the redirection operator >>.
Once you execute the preceding commands, restart your Terminal, and:
echo $PATH
It should now include paths to both the Scala and Maven binaries.



