






















































Measures of variation
It is good to have knowledge of the variation of values in the dataset. Various statistical functions facilitate:
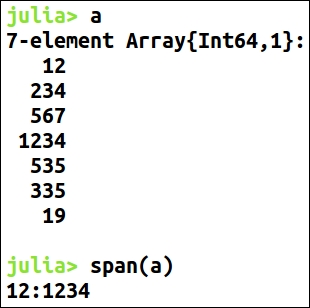
span(arr): span is used to calculate the total spread of the dataset, which ismaximum(arr)tominimum(arr):
variation(arr): Also called the coefficient of variance. It is the ratio of the standard deviation to the mean of the dataset. In relation to the mean of the population, CV denotes the extent of variability. Its advantage is that it is a dimensionless number and can be used to compare different datasets.

Standard error of mean: We work on different samples drawn from the population. We compute the means of these samples and call them sample means. For different samples, we wouldn't be having the same sample mean but a distribution of sample means. The standard deviation of the distribution of these sample means is called standard error of mean.
In Julia, we can compute standard error of mean using sem(arr).
Mean absolute deviation is a robust measure...


