






















































Combining models
A model takes in data (usually preprocessed) and produces predictive results. What if we employ multiple models; will we make better decisions by combining predictions from individual models? We will talk about this in this section.
Let's start with an analogy. In high school, we sit together with other students and learn together, but we aren't supposed to work together during the exam. The reason is, of course, that teachers want to know what we've learned, and if we just copy exam answers from friends, we may not have learned anything. Later in life, we discover that teamwork is important. For example, this book is the product of a whole team, or possibly a group of teams.
Clearly, a team can produce better results than a single person. However, this goes against Occam's razor, since a single person can come up with simpler theories compared to what a team will produce. In machine learning, we nevertheless prefer to have our models cooperate with the following schemes:
- Voting and averaging
- Bagging
- Boosting
- Stacking
Let's get into each of them now.
Voting and averaging
This is probably the most understandable type of model aggregation. It just means the final output will be the majority or average of prediction output values from multiple models. It is also possible to assign different weights to individual models in the ensemble, for example, some models that are more reliable might be given two votes.
Nonetheless, combining the results of models that are highly correlated to each other doesn't guarantee a spectacular improvement. It is better to somehow diversify the models by using different features or different algorithms. If you find two models are strongly correlated, you may, for example, decide to remove one of them from the ensemble and increase proportionally the weight of the other model.
Bagging
Bootstrap aggregating, or bagging, is an algorithm introduced by Leo Breiman, a distinguished statistician at the University of California, Berkeley, in 1994, which applies bootstrapping to machine learning problems. Bootstrapping is a statistical procedure that creates multiple datasets from the existing one by sampling data with replacement. Bootstrapping can be used to measure the properties of a model, such as bias and variance.
In general, a bagging algorithm follows these steps:
- We generate new training sets from input training data by sampling with replacement
- For each generated training set, we fit a new model
- We combine the results of the models by averaging or majority voting
The following diagram illustrates the steps for bagging, using classification as an example (the circles and crosses represent samples from two classes):
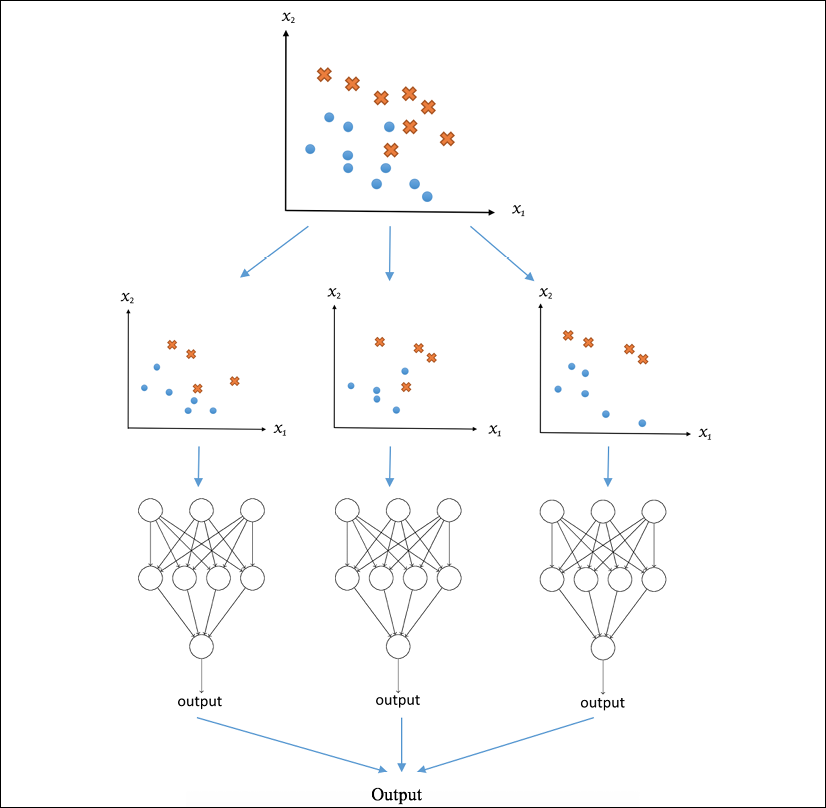
Figure 1.11: Workflow of bagging for classification
As you can imagine, bagging can reduce the chance of overfitting.
We will study bagging in depth in Chapter 4, Predicting Online Ad Click-Through with Tree-Based Algorithms.
Boosting
In the context of supervised learning, we define weak learners as learners who are just a little better than a baseline, such as randomly assigning classes or average values. Much like ants, weak learners are weak individually, but together they have the power to do amazing things.
It makes sense to take into account the strength of each individual learner using weights. This general idea is called boosting. In boosting, all models are trained in sequence, instead of in parallel as in bagging. Each model is trained on the same dataset, but each data sample is under a different weight factoring in the previous model's success. The weights are reassigned after a model is trained, which will be used for the next training round. In general, weights for mispredicted samples are increased to stress their prediction difficulty.
The following diagram illustrates the steps for boosting, again using classification as an example (the circles and crosses represent samples from two classes, and the size of a circle or cross indicates the weight assigned to it):
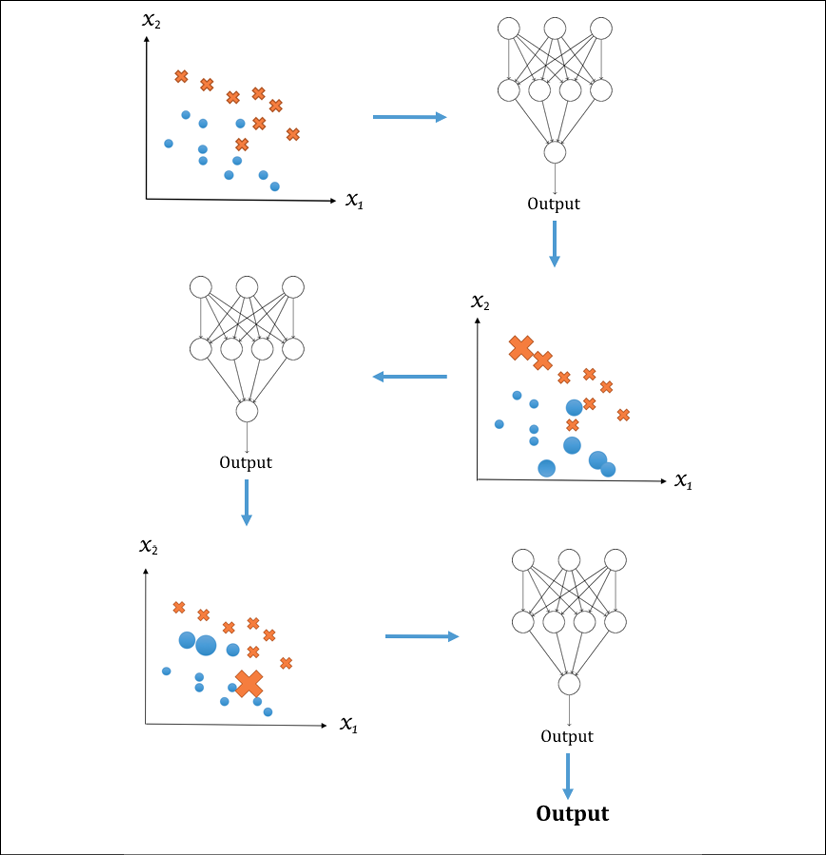
Figure 1.12: Workflow of boosting for classification
There are many boosting algorithms; boosting algorithms differ mostly in their weighting scheme. If you've studied for an exam, you may have applied a similar technique by identifying the type of practice questions you had trouble with and focusing on the hard problems.
Face detection in images is based on a specialized framework that also uses boosting. Detecting faces in images or videos is supervised learning. We give the learner examples of regions containing faces. There's an imbalance, since we usually have far more regions (about 10,000 times more) that don't have faces.
A cascade of classifiers progressively filters out negative image areas stage by stage. In each progressive stage, the classifiers use progressively more features on fewer image windows. The idea is to spend the most time on image patches that contain faces. In this context, boosting is used to select features and combine results.
Stacking
Stacking takes the output values of machine learning models and then uses them as input values for another algorithm. You can, of course, feed the output of the higher-level algorithm to another predictor. It's possible to use any arbitrary topology but, for practical reasons, you should try a simple setup first as also dictated by Occam's razor.
A fun fact is that stacking is commonly used in the winning models in the Kaggle competition. For instance, the first place for the Otto Group Product Classification challenge (www.kaggle.com/c/otto-group-product-classification-challenge) went to a stacking model composed of more than 30 different models.
So far, we have covered the tricks required to more easily reach the right generalization for a machine learning model throughout the data preprocessing and modeling phase. I know you can't wait to start working on a machine learning project. Let's get ready by setting up the working environment.






