






















































Chapter 8: Tips and Tricks of the Trade
Activity 21: Classifying Images using InceptionV3
Solution:
- Create functions to get images and labels. Here PATH variable contains the path to the training dataset.
from PIL import Image
def get_input(file):
return Image.open(PATH+file)
def get_output(file):
class_label = file.split('.')[0]
if class_label == 'dog': label_vector = [1,0]
elif class_label == 'cat': label_vector = [0,1]
return label_vector
- Set SIZE and CHANNELS. SIZE is the dimension of the square image input. CHANNELS is the number of channels in the training data images. There are 3 channels in a RGB image.
SIZE = 200
CHANNELS = 3
- Create a function to preprocess and augment images:
def preprocess_input(image):
# Data preprocessing
image = image.resize((SIZE,SIZE))
image = np.array(image).reshape(SIZE,SIZE,CHANNELS)
# Normalize image
image = image/255.0
return image
- Finally, develop the generator that will generate the batches:
import numpy as np
def custom_image_generator(images, batch_size = 128):
while True:
# Randomly select images for the batch
batch_images = np.random.choice(images, size = batch_size)
batch_input = []
batch_output = []
# Read image, perform preprocessing and get labels
for file in batch_images:
# Function that reads and returns the image
input_image = get_input(file)
# Function that gets the label of the image
label = get_output(file)
# Function that pre-processes and augments the image
image = preprocess_input(input_image)
batch_input.append(image)
batch_output.append(label)
batch_x = np.array(batch_input)
batch_y = np.array(batch_output)
# Return a tuple of (images,labels) to feed the network
yield(batch_x, batch_y)
- Next, we will read the validation data. Create a function to read the images and their labels:
from tqdm import tqdm
def get_data(files):
data_image = []
labels = []
for image in tqdm(files):
label_vector = get_output(image)
img = Image.open(PATH + image)
img = img.resize((SIZE,SIZE))
labels.append(label_vector)
img = np.asarray(img).reshape(SIZE,SIZE,CHANNELS)
img = img/255.0
data_image.append(img)
data_x = np.array(data_image)
data_y = np.array(labels)
return (data_x, data_y)
- Read the validation files:
import os
files = os.listdir(PATH)
random.shuffle(files)
train = files[:7000]
test = files[7000:]
validation_data = get_data(test)
7. Plot a few images from the dataset to see whether you loaded the files correctly:
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
columns = 5
for i in range(columns):
plt.subplot(5 / columns + 1, columns, i + 1)
plt.imshow(validation_data[0][i])
A random sample of the images is shown here:

Figure 8.16: Sample images from the loaded dataset
- Load the Inception model and pass the shape of the input images:
from keras.applications.inception_v3 import InceptionV3
base_model = InceptionV3(weights='imagenet', include_top=False, input_shape=(SIZE,SIZE,CHANNELS))
- Add the output dense layer according to our problem:
from keras.layers import GlobalAveragePooling2D, Dense, Dropout
from keras.models import Model
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(256, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(2, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
- Next, compile the model to make it ready for training:
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics = ['accuracy'])
And then perform the training of the model:
EPOCHS = 50
BATCH_SIZE = 128
model_details = model.fit_generator(custom_image_generator(train, batch_size = BATCH_SIZE),
steps_per_epoch = len(train) // BATCH_SIZE,
epochs = EPOCHS,
validation_data= validation_data,
verbose=1)
- Evaluate the model and get the accuracy:
score = model.evaluate(validation_data[0], validation_data[1])
print("Accuracy: {0:.2f}%".format(score[1]*100))
The accuracy is as follows:
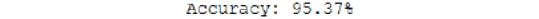
Figure 8.17: Model accuracy
Activity 22: Using Transfer Learning to Predict Images
Solution:
- First, set the random number seed so that the results are reproducible:
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(1)
- Set SIZE and CHANNELS
SIZE is the dimension of the square image input. CHANNELS is the number of channels in the training data images. There are 3 channels in a RGB image.
SIZE = 200
CHANNELS = 3
- Create functions to get images and labels. Here PATH variable contains the path to the training dataset.
from PIL import Image
def get_input(file):
return Image.open(PATH+file)
def get_output(file):
class_label = file.split('.')[0]
if class_label == 'dog': label_vector = [1,0]
elif class_label == 'cat': label_vector = [0,1]
return label_vector
- Create a function to preprocess and augment images:
def preprocess_input(image):
# Data preprocessing
image = image.resize((SIZE,SIZE))
image = np.array(image).reshape(SIZE,SIZE,CHANNELS)
# Normalize image
image = image/255.0
return image
- Finally, create the generator that will generate the batches:
import numpy as np
def custom_image_generator(images, batch_size = 128):
while True:
# Randomly select images for the batch
batch_images = np.random.choice(images, size = batch_size)
batch_input = []
batch_output = []
# Read image, perform preprocessing and get labels
for file in batch_images:
# Function that reads and returns the image
input_image = get_input(file)
# Function that gets the label of the image
label = get_output(file)
# Function that pre-processes and augments the image
image = preprocess_input(input_image)
batch_input.append(image)
batch_output.append(label)
batch_x = np.array(batch_input)
batch_y = np.array(batch_output)
# Return a tuple of (images,labels) to feed the network
yield(batch_x, batch_y)
- Next, we will read the development and test data. Create a function to read the images and their labels:
from tqdm import tqdm
def get_data(files):
data_image = []
labels = []
for image in tqdm(files):
label_vector = get_output(image)
img = Image.open(PATH + image)
img = img.resize((SIZE,SIZE))
labels.append(label_vector)
img = np.asarray(img).reshape(SIZE,SIZE,CHANNELS)
img = img/255.0
data_image.append(img)
data_x = np.array(data_image)
data_y = np.array(labels)
return (data_x, data_y)
- Now read the development and test files. The split for the train/dev/test set is 70%/15%/15%.
import random
random.shuffle(files)
train = files[:7000]
development = files[7000:8500]
test = files[8500:]
development_data = get_data(development)
test_data = get_data(test)
- Plot a few images from the dataset to see whether you loaded the files correctly:
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
columns = 5
for i in range(columns):
plt.subplot(5 / columns + 1, columns, i + 1)
plt.imshow(validation_data[0][i])
Check the output in the following screenshot:

Figure 8.18: Sample images from the loaded dataset
- Load the Inception model and pass the shape of the input images:
from keras.applications.inception_v3 import InceptionV3
base_model = InceptionV3(weights='imagenet', include_top=False, input_shape=(200,200,3))
10. Add the output dense layer according to our problem:
from keras.models import Model
from keras.layers import GlobalAveragePooling2D, Dense, Dropout
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(256, activation='relu')(x)
keep_prob = 0.5
x = Dropout(rate = 1 - keep_prob)(x)
predictions = Dense(2, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
- This time around, we will freeze the first five layers of the model to help with the training time:
for layer in base_model.layers[:5]:
layer.trainable = False
- Compile the model to make it ready for training:
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics = ['accuracy'])
- Create callbacks for Keras:
from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping, TensorBoard
callbacks = [
TensorBoard(log_dir='./logs',
update_freq='epoch'),
EarlyStopping(monitor = "val_loss",
patience = 18,
verbose = 1,
min_delta = 0.001,
mode = "min"),
ReduceLROnPlateau(monitor = "val_loss",
factor = 0.2,
patience = 8,
verbose = 1,
mode = "min"),
ModelCheckpoint(monitor = "val_loss",
filepath = "Dogs-vs-Cats-InceptionV3-{epoch:02d}-{val_loss:.2f}.hdf5",
save_best_only=True,
period = 1)]
Note
Here, we are making use of four callbacks: TensorBoard, EarlyStopping, ReduceLROnPlateau, and ModelCheckpoint.
Perform training on the model. Here we train our model for 50 epochs only and with a batch size of 128:
EPOCHS = 50
BATCH_SIZE = 128
model_details = model.fit_generator(custom_image_generator(train, batch_size = BATCH_SIZE),
steps_per_epoch = len(train) // BATCH_SIZE,
epochs = EPOCHS,
callbacks = callbacks,
validation_data= development_data,
verbose=1)
The training logs on TensorBoard are shown here:

Figure 8.19: Training set logs from TensorBoard
- You can now fine-tune the hyperparameters taking accuracy of the development set as the metric.
The logs of the development set from the TensorBoard tool are shown here:

Figure 8.20: Validation set logs from TensorBoard
The learning rate decrease can be observed from the following plot:

Figure 8.21: Learning rate log from TensorBoard
- Evaluate the model on the test set and get the accuracy:
score = model.evaluate(test_data[0], test_data[1])
print("Accuracy: {0:.2f}%".format(score[1]*100))
To understand fully, refer to the following output screenshot:
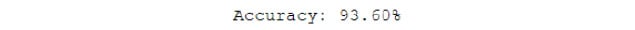
Figure 8.22: The final accuracy of the model on the test set
As you can see, the model gets an accuracy of 93.6% on the test set, which is different from the accuracy of the development set (93.3% from the TensorBoard training logs). The early stopping callback stopped training when there wasn't a significant improvement in the loss of the development set; this helped us save some time. The learning rate was reduced after nine epochs, which helped training, as can be seen here:






