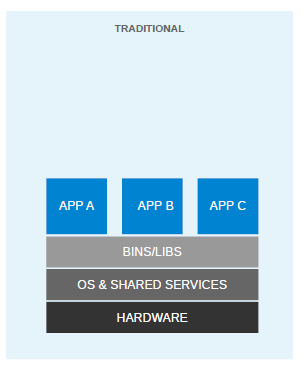
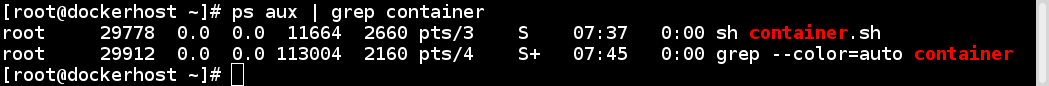At the very start of the IT revolution, most applications were deployed directly on physical hardware, over the host OS. Because of that single user space, runtime was shared between applications. The deployment was stable, hardware-centric, and had a long maintenance cycle. It was mostly managed by an IT department, and gave much less flexibility to developers. In such cases, the hardware resources were underutilized most of the time. The following diagram depicts such a setup:
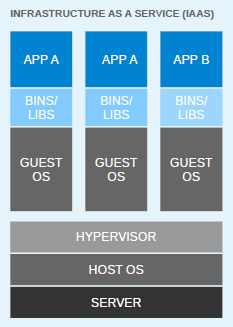
For flexible deployments, and in order to better utilize the resources of the host system, virtualization was invented. With hypervisors, such as KVM, XEN, ESX, Hyper-V, and so on, we emulated the hardware for virtual machines (VMs) and deployed a guest OS on each virtual machine. VMs can have a different OS than their host; this means that we are responsible for managing patches, security, and the performance of that VM. With virtualization, applications are isolated at VM level and are defined by the life cycle of VMs. This gives us a better return on our investment and higher flexibility at the cost of increased complexity and redundancy. The following diagram depicts a typical virtualized environment:
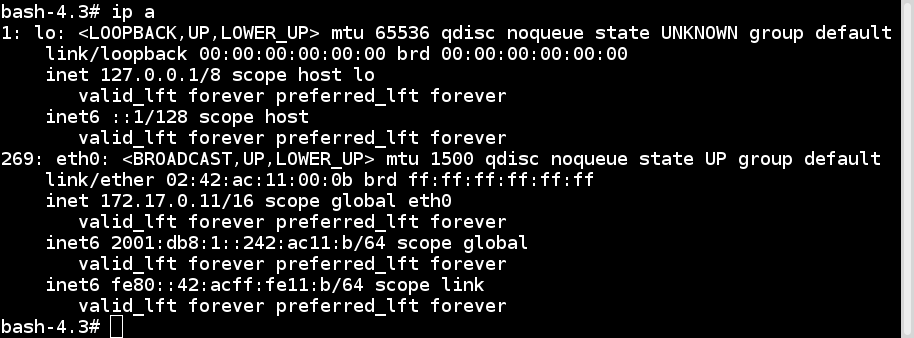
Since virtualization was developed, we have been moving towards more application-centric IT. We have removed the hypervisor layer to reduce hardware emulation and complexity. The applications are packaged with their runtime environment, and are deployed using containers. OpenVZ, Solaris Zones, and LXC are a few examples of container technology. Containers are less flexible compared to VMs; for example, we cannot run Microsoft Windows on Linux OS as of writing. Containers are also considered less secure than VMs, because with containers, everything runs on the host OS. If a container gets compromised, then it might be possible to get full access to the host OS. It can be a bit too complex to set up, manage, and automate. These are a few of the reasons why we have not seen the mass adoption of containers in the last few years, even though we had the technology. The following diagram shows how an application is deployed using containers:
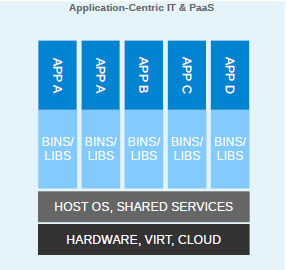
With Docker, containers suddenly became first-class citizens. All big corporations, such as Google, Microsoft, Red Hat, IBM, and others, are now working to make containers mainstream.
Docker was started as an internal project by dotCloud founder Solomon Hykes. It was released as open source in March 2013 under the Apache 2.0 license. With dotCloud's platform as a service experience, the founders and engineers of Docker were aware of the challenges of running containers. So with Docker, they developed a standard way to manage containers.
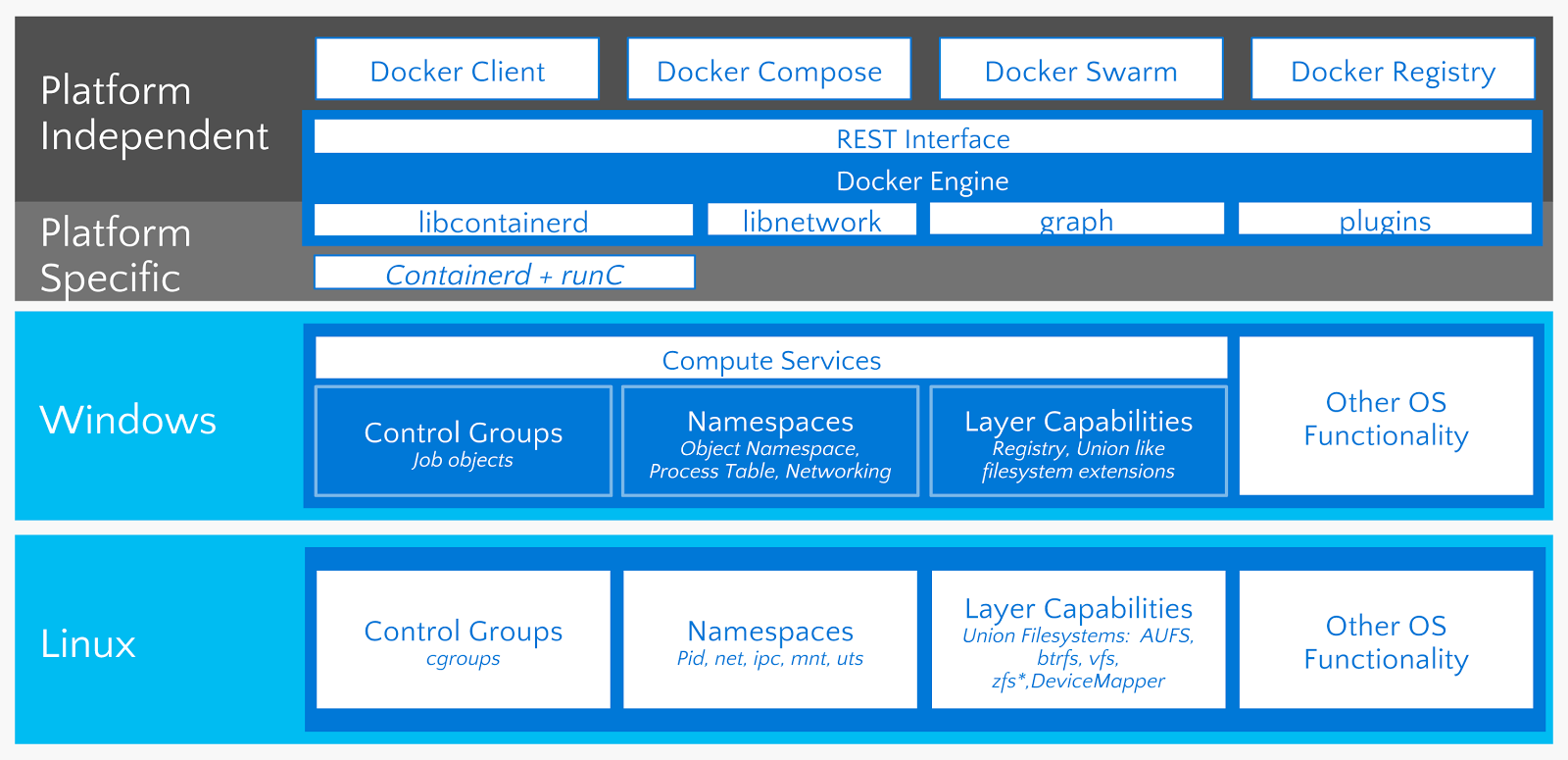
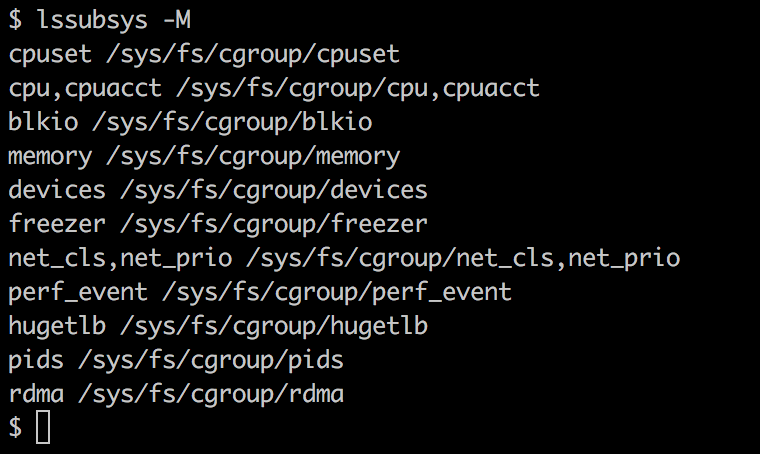
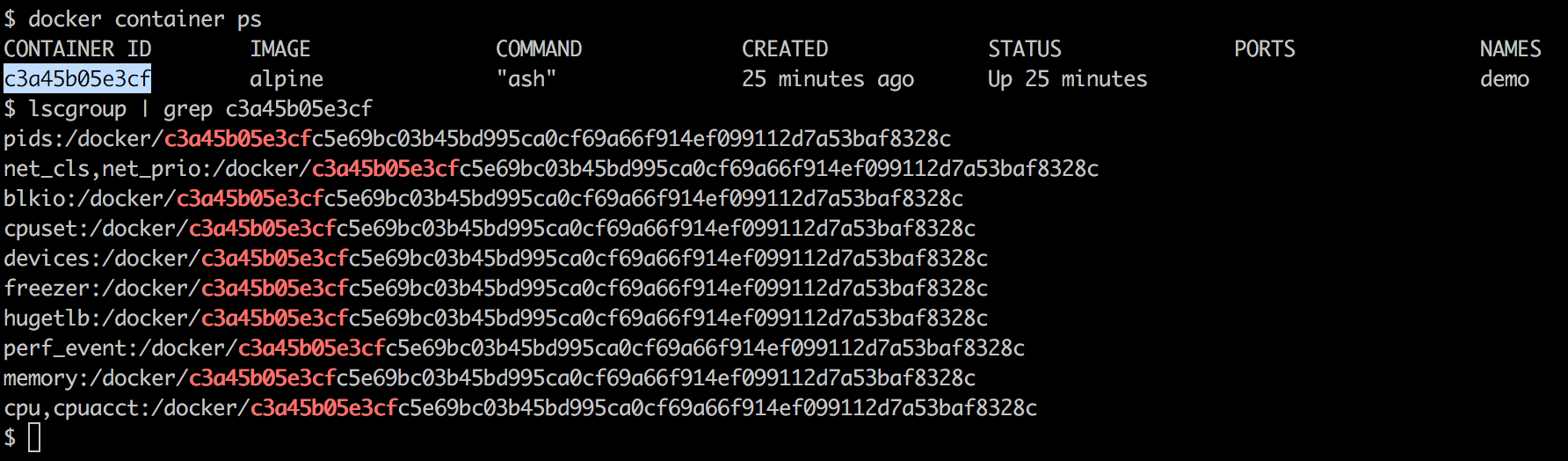
Docker uses the operating system's underlying kernel features, which enable containerization. The following diagram depicts the Docker platform and the kernel features used by Docker. Let's look at some of the major kernel features that Docker uses: