






















































Dealing with missing values
In this recipe, we’ll cover how to impute time series missing values. We’ll discuss different methods of imputing missing values and the factors to consider when choosing a method. We’ll show an example of how to solve this problem using pandas.
Getting ready
Missing values are an issue that plagues all kinds of data, including time series. Observations are often unavailable for various reasons, such as sensor failure or annotation errors. In such cases, data imputation can be used to overcome this problem. Data imputation works by assigning a value based on some rule, such as the mean or some predefined value.
How to do it…
We start by simulating missing data. The following code removes 60% of observations from a sample of two years of the solar radiation time series:
import numpy as np sample_with_nan = series_daily.head(365 * 2).copy() size_na=int(0.6 * len(sample_with_nan)) idx = np.random.choice(a=range(len(sample_with_nan)), size=size_na, replace=False) sample_with_nan[idx] = np.nan
We leverage the np.random.choice() method from numpy to select a random sample of the time series. The observations of this sample are changed to a missing value (np.nan).
In datasets without temporal order, it is common to impute missing values using central statistics such as the mean or median. This can be done as follows:
average_value = sample_with_nan.mean() imp_mean = sample_with_nan.fillna(average_value)
Time series imputation must take into account the temporal nature of observations. This means that the assigned value should follow the dynamics of the series. A more common approach in time series is to impute missing data with the last known observation. This approach is implemented in the ffill() method:
imp_ffill = sample_with_nan.ffill()
Another, less common, approach that uses the order of observations is bfill():
imp_bfill = sample_with_nan.bfill()
The bfill() method imputes missing data with the next available observation in the dataset.
How it works…
The following figure shows the reconstructed time series after imputation with each method:
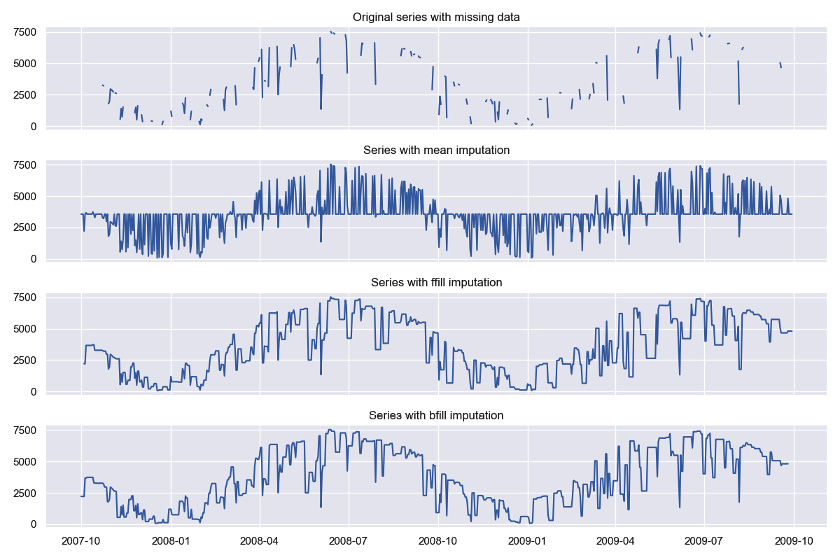
Figure 1.2: Imputing missing data with different strategies
The mean imputation approach misses the time series dynamics, while both ffill and bfill lead to a reconstructed time series with similar dynamics as the original time series. Usually, ffill is preferable because it does not break the temporal order of observations, that is, using future information to alter (impute) the past.
There’s more…
The imputation process can also be carried out using some conditions, such as limiting the number of imputed observations. You can learn more about this in the documentation pages of these functions, for example, https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.ffill.html.


