We actually recommend applying the first rule to all clusters, as suggested in the Introducing indirection recipe. It's especially important here as the focus is specifically centered on maximizing availability.
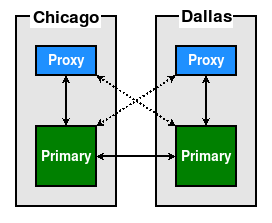
Unlike a standard PostgreSQL node, a cluster containing multiple primary nodes does not require the promotion of alternate systems to writable status. This means we can switch to them in a nearly instantaneous manner. A properly configured proxy layer means this is possible without directly alerting the application layer. Such a cluster could resemble this diagram:
Given this configuration, it's possible to switch from one Primary to the other with a pause of mere milliseconds in between. This effectively means zero RTO contribution for that action. This allows us to perform maintenance on any node, essentially without disturbing the application layer at all.
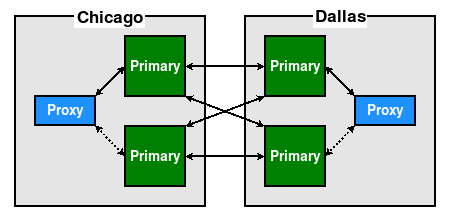
In the preceding configuration, however, we only have one node per location. In the event that the Primary in Chicago fails or is undergoing maintenance, applications in that location will be interacting with the Dallas node. A better design would be something like this:
With two nodes per data center, we're free to swap between them as necessary. If the proxy uses a connection check mechanism, it can even autodetect online status and ensure traffic always goes to the online node in the same location.
The extra Primary per data center need not remain idle when not in use. Some proxy systems can allocate application sessions by user, account, or some other identifying characteristic. This allows safe load balancing that avoids risks associated with multi-master systems, such as conflict resolution.
Pay attention to the preceding diagrams and try to find one common attribute they both share.
Find it yet?
Each cluster has an even number of nodes. Also note that we didn't compensate for this by adding any kind of witness node to help arbitrate the quorum state. This is because each node is a Primary with no failover process to manage. As a consequence, we no longer have the usual cause of split brain, nor must we worry too much about network partition events.
Finally, try, if possible, to arrange the cluster such that data is as closely associated with its users as possible. If users are bank clients interacting with their own account and can be regionalized by country, this is an easy choice. If it's a shared service microarchitecture with applications indiscriminately modifying data from arbitrary accounts, that's not so simple.
For those more advanced circumstances, it's possible to approach the problem from a smaller scale. Perhaps servers in the same rack only communicate with the database nearest to them physically. Perhaps the proxy layer can use sticky sessions and route connections to specific primary nodes based on a stable metric.
The goal here is data locality. While multi-master PostgreSQL allows multiple nodes to ingest writes simultaneously, consider transmission latency. We can observe this in a simple two-node interaction:
- Node A accepts a write for Account X.
- Node A sends the result to Node B.
- The application is stateless and connects to Node B.
- The application notices data is missing in node B and submits a change again.
- Node B replays data from Node A.
- Account X has now been modified twice.
If the application session was tightly coupled to one primary node, this scenario would not be possible. There are numerous ways to accomplish this coupling, and it helps ensure fastest turnaround for associated data that was previously modified in any case.