






















































It can be difficult to understand why neural networks work so well. This introduction will look at them from two viewpoints. If you have an understanding of how linear regression works, the first viewpoint should be useful. The second viewpoint is more intuitive and less technical, but equally valid. I encourage you to read both and spend some time contemplating both overviews.
A conceptual overview of neural networks
Neural networks as an extension of linear regression
One of the simplest and oldest prediction models is regression. It predicts a continuous value (that is, a number) based on another value. The linear regression function is:
y=mx+b
Where y is the value you want to predict and x is your input variable. The linear regression coefficients (or parameters) are m (the slope of the line) and b (the intercept). The following R code creates a line with the y= 1.4x -2 function and plots it:
set.seed(42)
m <- 1.4
b <- -1.2
x <- 0:9
jitter<-0.6
xline <- x
y <- m*x+b
x <- x+rnorm(10)*jitter
title <- paste("y = ",m,"x ",b,sep="")
plot(xline,y,type="l",lty=2,col="red",main=title,xlim=c(0,max(y)),ylim=c(0,max(y)))
points(x[seq(1,10,2)],y[seq(1,10,2)],pch=1)
points(x[seq(2,11,2)],y[seq(2,11,2)],pch=4)
The o or x points are the values to be predicted given a value on the x axis and the line is the ground truth. Some random noise is added, so that the points are not exactly on the line. This code produces the following output:
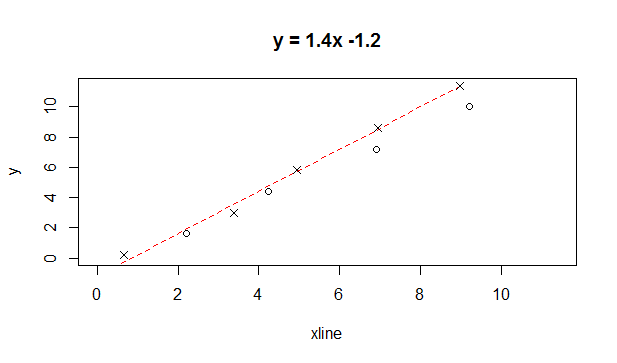
Figure 1.2: Example of a regression line fitted to data (that is, predict y from x)
In a regression task, you are given some x and corresponding y values, but are not given the underlying function to map x to y. The purpose of a supervised machine learning task is that given some previous examples of x and y, can we predict the y values for new data where we only have x and not y. An example might be to predict house prices based on the number of bedrooms in the house. So far, we have only considered a single input variable, x, but we can easily extend the example to handle multiple input variables. For the house example, we would use the number of bedrooms and square footage to predict the price of the house. Our code can accommodate this by changing the input, x, from a vector (one-dimensional array) into a matrix (two-dimensional array).
If we consider our model for predicting house prices, linear regression has a serious limitation: it can only estimate linear functions. If the mapping from x to y is not linear, it will not predict y very well. The function always results in a straight line for one variable and a hyperplane if multiple x predictor values are used. This means that linear regression models may not be accurate at the low and high extent of the data.
A simple trick to make the model fit nonlinear relationships is to add polynomial terms to the function. This is known as polynomial regression. For example, by adding a polynomial of degree 4, our function changes to:
y= m1x4+ m2x3+ m3x2+ m4x+b
By adding these extra terms, the line (or decision boundary) is no longer linear. The following code demonstrates this – we create some sample data and we create three regression models to fit this data. The first model has no polynomial terms, the model is a straight line and fits the data very poorly. The second model (blue circles) has polynomials up to degree 3, that is, X, X2, and X3. The last model has polynomials up to degree 12, that is, X, X2,....., X12. The first model (straight line) underfits the data and the last line overfits the data. Overfitting refers to situations where the model is too complex and ends up memorizing the data. This means that the model does not generalize well and will perform poorly on unseen data. The following code generates the data and creates three models with increasing levels of polynomial:
par(mfrow=c(1,2))
set.seed(1)
x1 <- seq(-2,2,0.5)
# y=x^2-6
jitter<-0.3
y1 <- (x1^2)-6
x1 <- x1+rnorm(length(x1))*jitter
plot(x1,y1,xlim=c(-8,12),ylim=c(-8,10),pch=1)
x <- x1
y <- y1
# y=-x
jitter<-0.8
x2 <- seq(-7,-5,0.4)
y2 <- -x2
x2 <- x2+rnorm(length(x2))*jitter
points(x2,y2,pch=2)
x <- c(x,x2)
y <- c(y,y2)
# y=0.4 *rnorm(length(x3))*jitter
jitter<-1.2
x3 <- seq(5,9,0.5)
y3 <- 0.4 *rnorm(length(x3))*jitter
points(x3,y3,pch=3)
x <- c(x,x3)
y <- c(y,y3)
df <- data.frame(cbind(x,y))
plot(x,y,xlim=c(-8,12),ylim=c(-8,10),pch=4)
model1 <- lm(y~.,data=df)
abline(coef(model1),lty=2,col="red")
max_degree<-3
for (i in 2:max_degree)
{
col<-paste("x",i,sep="")
df[,col] <- df$x^i
}
model2 <- lm(y~.,data=df)
xplot <- seq(-8,12,0.1)
yplot <- (xplot^0)*model2$coefficients[1]
for (i in 1:max_degree)
yplot <- yplot +(xplot^i)*model2$coefficients[i+1]
points(xplot,yplot,col="blue", cex=0.5)
max_degree<-12
for (i in 2:max_degree)
{
col<-paste("x",i,sep="")
df[,col] <- df$x^i
}
model3 <- lm(y~.,data=df)
xplot <- seq(-8,12,0.1)
yplot <- (xplot^0)*model3$coefficients[1]
for (i in 1:max_degree)
yplot <- yplot +(xplot^i)*model3$coefficients[i+1]
points(xplot,yplot,col="green", cex=0.5,pch=2)
MSE1 <- c(crossprod(model1$residuals)) / length(model1$residuals)
MSE2 <- c(crossprod(model2$residuals)) / length(model2$residuals)
MSE3 <- c(crossprod(model3$residuals)) / length(model3$residuals)
print(sprintf(" Model 1 MSE = %1.2f",MSE1))
[1] " Model 1 MSE = 14.17"
print(sprintf(" Model 2 MSE = %1.2f",MSE2))
[1] " Model 2 MSE = 3.63"
print(sprintf(" Model 3 MSE = %1.2f",MSE3))
[1] " Model 3 MSE = 0.07"
If we were selecting one of these models to use, we should select the middle model, even though the third model has a lower MSE (mean-squared error). In the following screenshot; the best model is the curved line from the top left corner:
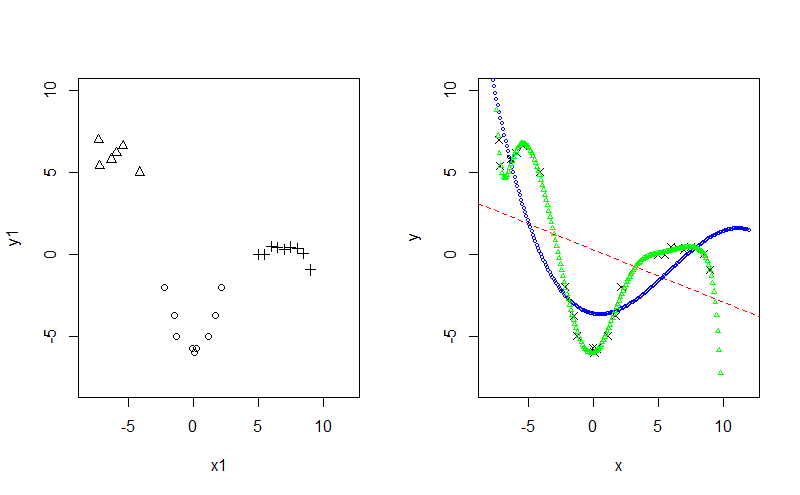
Figure 1.3: Polynomial regression
If we look at the three models and see how they handle the extreme left and right points, we see why overfitting can lead to poor results on unseen data. On the right side of the plot, the last series of points (plus signs) have a local linear relationship. However, the polynomial regression line with degree 12 (green triangles) puts too much emphasis on the last point, which is extra noise and the line moves down sharply. This would cause the model to predict extreme negative values for y as x increases, which is not justified if we look at the data. Overfitting is an important issue that we will look at in more detail in later chapters.
By adding square, cube, and more polynomial terms, the model can fit more complex data than if we just used linear functions on the input data. Neural networks use a similar concept, except that, instead of taking polynomial terms of the input variable, they chain multiple regression functions together with nonlinear terms between them.
The following is an example of a neural network architecture. The circles are nodes and the lines are the connections between nodes. If a connection exists between two nodes, the output from the node on the left is the input for the next node. The output value from a node is a matrix operation on the input values to the node and the weights of the node:
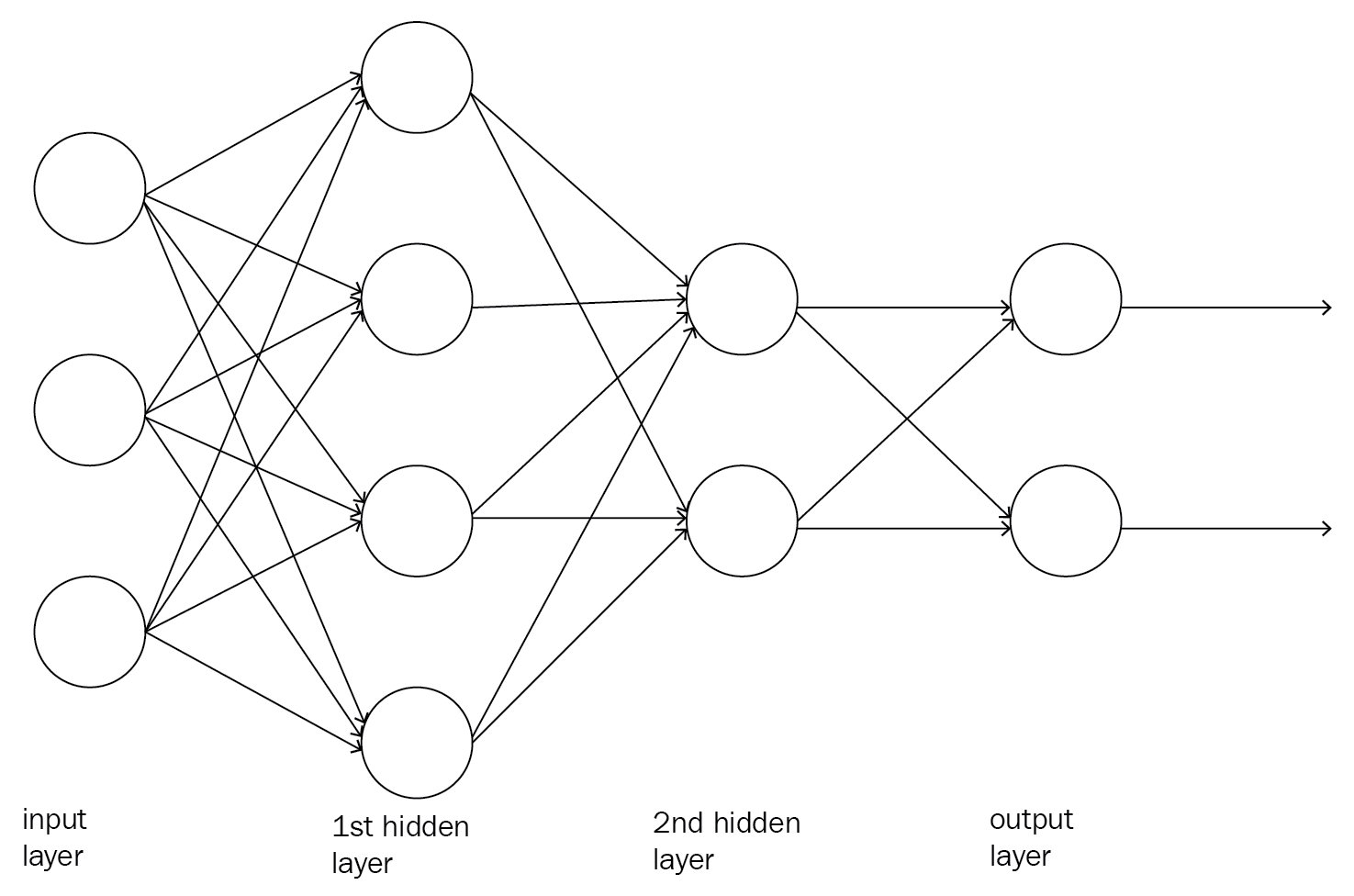
Figure 1.4: An example neural network
Before the output values from a node are passed to the next node as input values, a function is applied to the values to change the overall function to a non-linear function. These are known as activation functions and they perform the same role as the polynomial terms.
This idea of creating a machine learning model by combining multiple small functions together is a very common paradigm in machine learning. It is used in random forests, where many small independent decision trees vote for the result. It is also used in boosting algorithms, where the misclassified instances from one function are given more prominence in the next function.
By including many layers of nodes, the neural network model can approximate almost any function. It does make training the model more difficult, so we'll give a brief explanation of how to train a neural network. Each node is assigned a set of random weights initially. For the first pass, these weights are used to calculate and pass (or propagate) values from the input layer to the hidden layers and finally to the output layer. This is known as forward-propagation. Because the weights were set randomly, the final (prediction) values at the output layer will not be accurate compared to the actual values, so we need a method of calculating how different the predicted values are from the actual values. This is calculated using a cost function, which gives a measure of how accurate the model is during training. We then need to adjust the weights in the nodes from the output layer backward to get us nearer to the target values. This is done using backward-propagation; we move from right to left, updating the weights of the nodes in each layer very slightly to get us very slightly closer to the actual values. The cycle of forward-propagation and backward-propagation continues until the error value from the loss function stops getting smaller; this may require hundreds, or thousands of iterations, or epochs.
To update the node weights correctly, we need to know that the change will get us nearer to the target, which is to minimize the result from the cost function. We are able to do this because of a clever trick, we use activation functions that have derivative functions.
If your knowledge of calculus is limited, it can be difficult to get an understanding of derivatives initially. But in simple terms, a function may have a derivative formula that tells us how to change the input of a function so that the output of the function moves in a positive or negative manner. This derivative/formula enables the algorithm to minimize the cost function, which is a measurement of error. In more technical terms, the derivative of the function measures the rate of change in the function as the input changes. If we know the rate of change of a function as the input changes, and more importantly what direction it changes in, then we can use this to get nearer to minimizing that function. An example that you may have seen before is the following diagram:
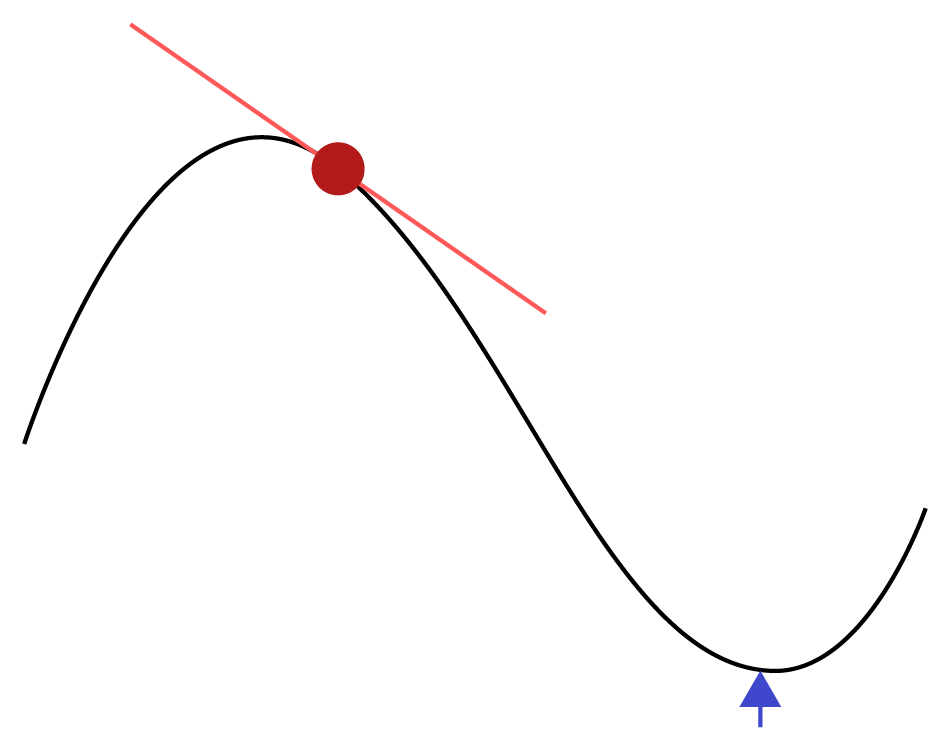
Figure 1.5: A function (curved) line and its derivative at a point
In this diagram, the curved line is a mathematical function we want to minimize over y, that is, we want to get to the lowest point (which is marked by the arrow). We are currently at the point in the red circle, and the derivative at that point is the slope of the tangent. The derivative function indicates the direction we need to move in to get there. The derivative value changes as we get nearer the target (the arrow), so we cannot make the move in one big step. Therefore, the algorithm moves in small steps and re-calculates the derivative after each step, but if we choose too small a step, it will take very long to converge (that is, get near the minimum). If we take too big a step, we run the risk of overshooting the minimum value. How big a step you take is known as the learning rate, and it effectively decides how long it takes the algorithm to train.
This might seem a bit abstract, so an analogy should make it somewhat clearer. This analogy may be over-simplified, but it explains derivatives, learning rates, and cost functions. Imagine a simple model of driving a car, where the speed must be set to a value that is suitable for the conditions and the speed limit. The difference between your current speed and the target speed is the error rate and this is calculated using a cost function (just simple subtraction, in this case). To change your speed, you apply the gas pedal to speed up or the brake pedal to slow down. The acceleration/deceleration (that is, the rate of change of the speed) is the derivative of the speed. The amount of force that is applied to the pedals changes how fast the acceleration/deceleration occurs, the force is similar to the learning rate in a machine learning algorithm. It controls how long it takes to get to the target value. If only a small change is applied to the pedals, you will eventually get to your target speed, but it will take much longer. However, you usually don't want to apply maximum force to the pedals, to do so may be dangerous (if you slam on the brakes) or a waste of fuel (if you accelerate too hard). There is a happy medium where you apply the change and get to the target speed safely and quickly.
Neural networks as a network of memory cells
Another way to consider neural networks is to compare them to how humans think. As their name suggests, neural networks draw inspiration from neural processes and neurons in the mind. Neural networks contain a series of neurons, or nodes, which are interconnected and process input. The neurons have weights that are learned from previous observations (data). The output of a neuron is a function of its input and its weights. The activation of some final neuron(s) is the prediction.
We will consider a hypothetical case where a small part of the brain is responsible for matching basic shapes, such as squares and circles. In this scenario, some neurons at the basic level fire for horizontal lines, another set of neurons fires for vertical lines, and yet another set of neurons fire for curved segments. These neurons feed into higher-order process that combines the input so that it recognizes more complex objects, for example, a square when the horizontal and vertical neurons both are activated simultaneously.
In the following diagram, the input data is represented as squares. These could be pixels in an image. The next layer of hidden neurons consists of neurons that recognize basic features, such as horizontal lines, vertical lines, or curved lines. Finally, the output may be a neuron that is activated by the simultaneous activation of two of the hidden neurons:
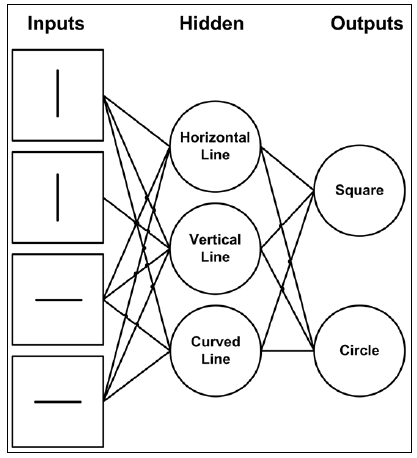
Figure 1.6: Neural networks as a network of memory cells
In this example, the first node in the hidden layer is good at matching horizontal lines, while the second node in the hidden layer is good at matching vertical lines. These nodes remember what these objects are. If these nodes combine, more sophisticated objects can be detected. For example, if the hidden layer recognizes horizontal lines and vertical lines, the object is more likely to be a square than a circle. This is similar to how convolutional neural networks work, which we will cover in Chapter 5, Image Classification Using Convolutional Neural Networks.
We have covered the theory behind neural networks very superficially here as we do not want to overwhelm you in the first chapter! In future chapters, we will cover some of these issues in more depth, but in the meantime, if you wish to get a deeper understanding of the theory behind neural networks, the following resources are recommended:
- Chapter 6 of Goodfellow-et-al (2016)
- Chapter 11 of Hastie, T., Tibshirani, R., and Friedman, J. (2009), which is freely available at https://web.stanford.edu/~hastie/Papers/ESLII.pdf
- Chapter 16 of Murphy, K. P. (2012)
Next, we will turn to a brief introduction to deep neural networks.






