






















































Tensors and the computational graph
Tensors are arrays of numbers that transform based on specific rules. The simplest kind of tensor is a single number. This is also called a scalar. Scalars are sometimes referred to as rank-zero tensors.
The next tensor is a vector, also known as a rank-one tensor. The next The next ones up the order are matrices, called rank-two tensors; cube matrices, called rank-three tensors; and so on. You can see the rankings in the following table:
|
Rank |
Name |
Expresses |
|---|---|---|
|
0 |
Scalar |
Magnitude |
|
1 |
Vector |
Magnitude and Direction |
|
2 |
Matrix |
Table of numbers |
|
3 |
Cube Matrix |
Cube of numbers |
|
n |
n-dimensional matrix |
You get the idea |
This book mostly uses the word tensor for rank-three or higher tensors.
TensorFlow and every other deep learning library perform calculations along a computational graph. In a computational graph, operations, such as matrix multiplication or an activation function, are nodes in a network. Tensors get passed along the edges of the graph between the different operations.
A forward pass through our simple neural network has the following graph:
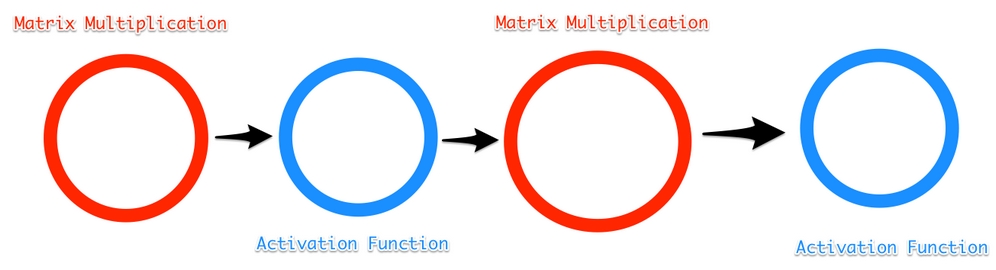
A simple computational graph
The advantage of structuring computations as a graph is that it's easier to run nodes in parallel. Through parallel computation, we do not need one very fast machine; we can also achieve fast computation with many slow computers that split up the tasks.
This is the reason why GPUs are so useful for deep learning. GPUs have many small cores, as opposed to CPUs, which only have a few fast cores. A modern CPU might only have four cores, whereas a modern GPU can have hundreds or even thousands of cores.
The entire graph of just a very simple model can look quite complex, but you can see the components of the dense layer. There is a matrix multiplication (matmul), adding bias and a ReLU activation function:
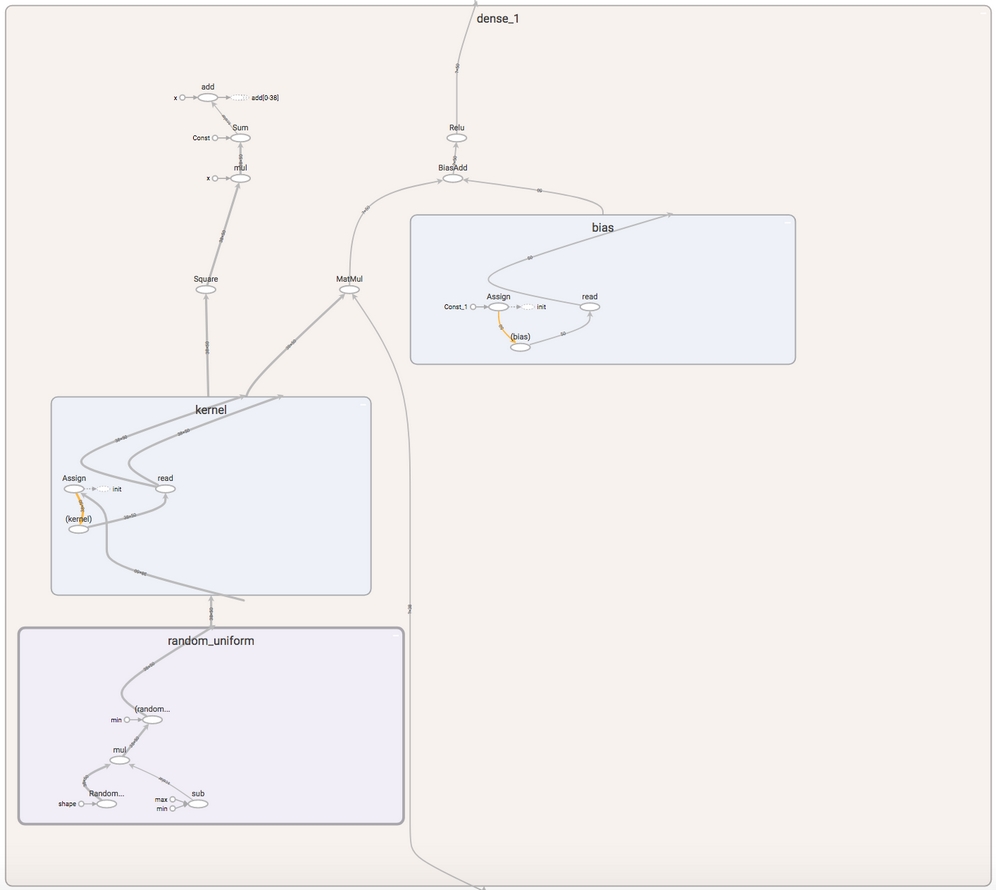
The computational graph of a single layer in TensorFlow. Screenshot from TensorBoard.
Another advantage of using computational graphs such as this is that TensorFlow and other libraries can quickly and automatically calculate derivatives along this graph. As we have explored throughout this chapter, calculating derivatives is key for training neural networks.





