






















































Replicating your data
AWS S3 replication is an automatic asynchronous process that involves copying objects to one or multiple destination buckets. Replication can be configured across buckets in the same AWS region with Same-Region Replication, which can be useful for scenarios such as isolating different workloads, segregating data for different teams, or achieving compliance requirements. Replication can also be configured for buckets across different AWS regions with Cross-Region Replication (CRR), which helps in reducing latency for accessing data, especially for enterprises with a large number of locations, by maintaining multiple copies of the objects in different geographies or different regions. It provides compliance and data redundancy for improved performance, availability, and disaster recovery capabilities.
In this recipe, we’ll learn how to set up replication between two buckets in different AWS regions and the same AWS account.
Getting ready
You need to have an S3 bucket in the destination AWS region to act as a target for the replication. Also, S3 versioning must be enabled for both the source and destination buckets.
How to do it…
- Sign in to the AWS Management Console (https://console.aws.amazon.com/console/home?nc2=h_ct&src=header-signin) and navigate to the S3 service.
- In the Buckets list, choose the source bucket you want to replicate.
- Go to the Management tab and select Create replication rule under Replication rules.
- Under Replication rule name in the Replication rule configuration section, give your rule a unique name.
- Under Status, either keep it Enabled for the rule to take effect once you save it or change it to Disabled to enable it later as required:
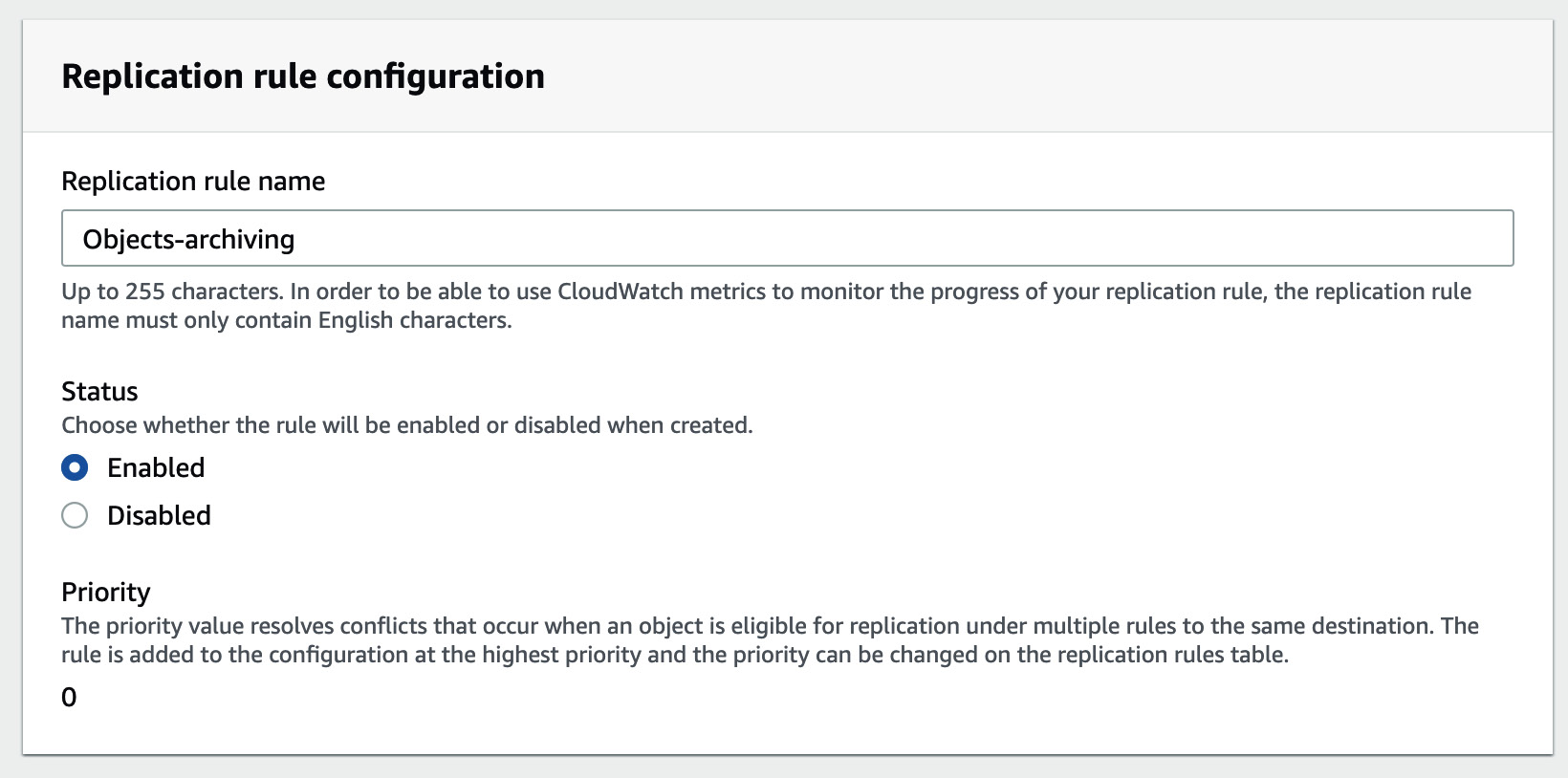
Figure 1.10 – Replication rule configuration
- If this is the first replication rule for the bucket, Priority will be set to 0. Subsequent rules that are added will be assigned higher priorities. When multiple rules share the same destination, the rule with the highest priority takes precedence during execution, typically the one created last. If you wish to control the priority for each rule, you can achieve this by setting the rule using XML. For guidance on how to configure this, refer to the See also section.
- In the Source bucket section, you have the option to replicate all objects in the bucket by selecting Apply to all objects in the bucket or you can narrow it down to specific objects by selecting Limit the scope of this rule using one or more filters and specifying a Prefix value (for example,
logs_orlogs/) to filter objects. Additionally, you have the option to replicate objects based on their tags. Simply choose Add tag and input key-value pairs. This process can be repeated so that you can include multiple tags:
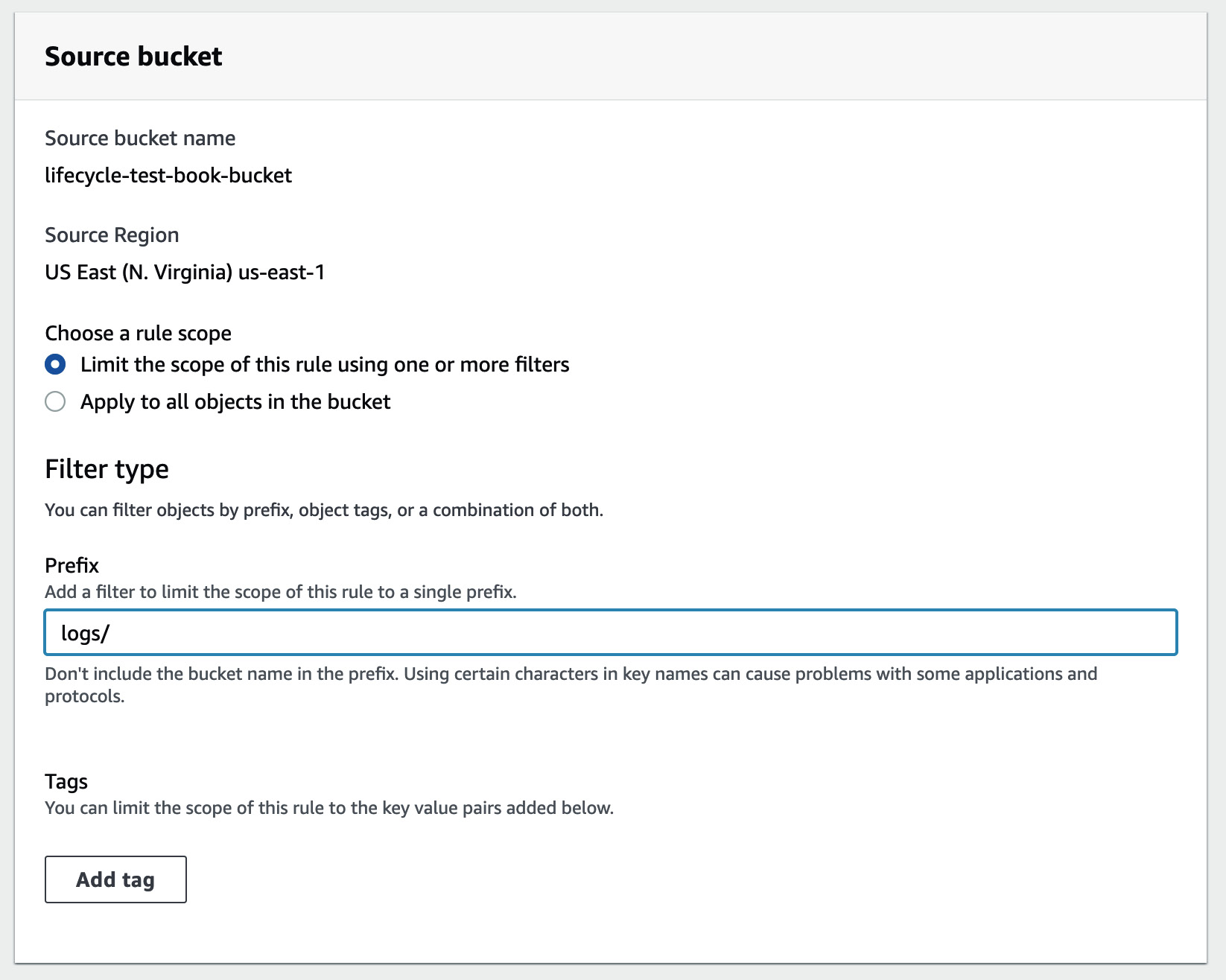
Figure 1.11 – Source bucket configuration
- Under Destination, select Choose a bucket in this account and enter or browse for the destination bucket name.
- Under IAM role, select Choose from existing IAM roles, then choose Create new role from the drop-down list.
- Under Destination storage class, you can select Change the storage class for the replicated objects and choose one of the storage classes to be set for the replicated objects in the destination bucket.
- Click on Save to save your changes.
How it works…
By adding this replication rule, you grant the source bucket permission to replicate objects to the destination bucket in the said region. Once the replication process is complete, the destination bucket will contain a copy of the objects from the source bucket. The objects in the destination bucket will have the same ownership, permissions, and metadata as the source objects. When you enable replication to your bucket, several background processes occur to facilitate this process. S3 continuously monitors changes to objects in your source bucket. Once a change is detected, S3 generates a replication request for the corresponding objects and initiates the process of transferring the data from the source to the destination bucket.
There’s more…
There are additional options that you can enable while setting the replication rule under Additional replication options. The Replication metrics option enables you to monitor the replication progress with S3 Replication metrics. It does this by tracking bytes pending, operations pending, and replication latency. The Replication Time Control (RTC) option can be beneficial if you have a strict service-level agreement (SLA) for data replication as it will ensure that approximately 99% of your objects will be replicated within a 15-minute timeframe. It also enables replication metrics to notify you of any instances of delayed object replication. The Delete marker replication option will replicate object versions with a delete marker. Finally, the Replica modification sync option will replicate the metadata changes of objects.
See also
- Replicating buckets in different AWS accounts: https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication-walkthrough-2.html
- Replication configuration: https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication-add-config.html











