






















































Elements of a RL problem
So far, we have covered the types of problems that can be modeled using RL. In the next chapters, we will dive into state-of-the-art algorithms that will solve those problems. However, in between, we need to formally define the elements in an RL problem. This will lay the ground for the more technical material by establishing our vocabulary. After providing these definitions, we then look into what these concepts correspond to in a tic-tac-toe example.
RL concepts
Let's start with defining the most fundamental components in an RL problem.
- At the center of a RL problem, there is the learner, which is called the agent in RL terminology. Most of the problem classes we deal with has a single agent. On the other hand, if there are more than one agent, that problem class is called a multi-agent RL, or MARL for short. In MARL, the relationship between the agents could be cooperative, competitive or the mix of the two.
- The essence of an RL problem is the agent learning what to do, that is which action to take, in different situations in the world it lives in. We call this world the environment and it refers to everything outside of the agent.
- The set of all the information that precisely and sufficiently describes the situation in the environment is called the state. So, if the environment is in the same state at different points in time, it means everything about the environment is exactly the same - like a copy-paste.
- In some problems, the knowledge of the state is fully available to the agent. In a lot of other problems, and especially in more realistic ones, the agent does not fully observe the state, but only part of it (or a derivation of a part of the state). In such cases, the agent uses its observation to take actions. When this is the case, we say that the problem is partially observable. Unless we say otherwise, we assume that the agent is able to fully observe the state that the environment is in and is basing its actions on the state.
Info
The term state and its notation
 is more commonly used during abstract discussions, especially when the environment is assumed to be fully observable, although observation is a more general term: What the agent receives is always an observation, which is sometimes just the state itself, and sometimes a part of or a derivation from the state, depending on the environment. Don't get confused if you see them used interchangeably in some contexts.
is more commonly used during abstract discussions, especially when the environment is assumed to be fully observable, although observation is a more general term: What the agent receives is always an observation, which is sometimes just the state itself, and sometimes a part of or a derivation from the state, depending on the environment. Don't get confused if you see them used interchangeably in some contexts.
So far, we have not really defined what makes an action good or bad. In RL, every time the agent takes an action, it receives a reward from the environment (albeit it is sometimes zero). Reward could mean many things in general, but in RL terminology, its meaning is very specific: it is a scalar number. The greater the number is, the higher also is the reward. In an iteration of an RL problem, the agent observes the state the environment is in (fully or partially) and takes an action based on its observation. As a result, the agent receives a reward and the environment transitions into a new state. This process is described in Figure 2 below, which is probably familiar to you.
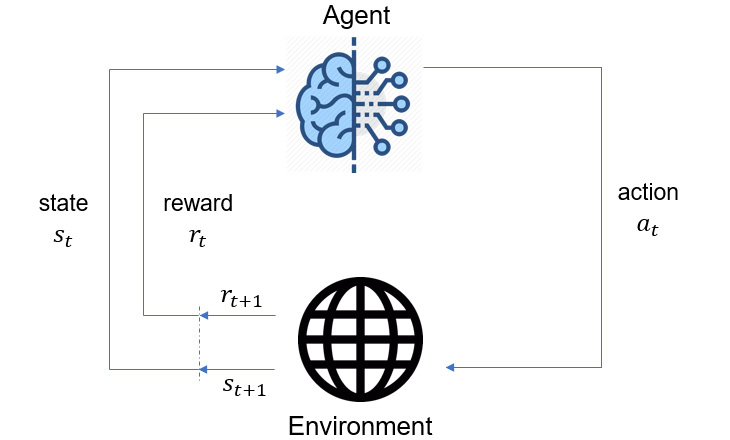
Figure 1.2 – RL process diagram
Remember that in RL, the agent is interested in actions that will be beneficial over the long term. This means the agent must consider the long-term consequences of its actions. Some actions might lead the agent to immediate high rewards only to be followed by very low rewards. The opposite might also be true. So, the agent's goal is to maximize the cumulative reward it receives. The natural follow up question is over what time horizon? The answer depends on whether the problem of interest is defined over a finite or an infinite horizon.
- If it is the former, the problem is described as an episodic task where an episode is defined as the sequence of interactions from an initial state to a terminal state. In episodic tasks, the agent's goal is to maximize the expected total cumulative reward collected over an episode.
- If problem is defined over an infinite horizon, it is called a continuing task. In that case, the agent will try to maximize the average reward since the total reward would go up to infinity.
- So, how does an agent achieve this objective? The agent identifies the best action(s) to take given its observation of the environment. In other words, the RL problem is all about finding a policy, which maps a given observation to one (or more) of the actions, that maximizes the expected cumulative reward.
All these concepts have concrete mathematical definitions, which we will cover in detail in later chapters. But for now, let's try to understand what these concepts would correspond to in a concrete example.
Casting Tic-Tac-Toe as a RL problem
Tic-tac-toe is a simple game, in which two players take turns to mark the empty spaces in a  grid. We now cast this as a RL problem to map the definitions provided above to the concepts in the game. The goal for a player is to place three of their marks in a vertical, horizontal or diagonal row to become the winner. If none of the players are able to achieve this before running out of the empty spaces on the grid, the game ends in a draw. Mid-game, a tic-tac-toe board might look like this:
grid. We now cast this as a RL problem to map the definitions provided above to the concepts in the game. The goal for a player is to place three of their marks in a vertical, horizontal or diagonal row to become the winner. If none of the players are able to achieve this before running out of the empty spaces on the grid, the game ends in a draw. Mid-game, a tic-tac-toe board might look like this:
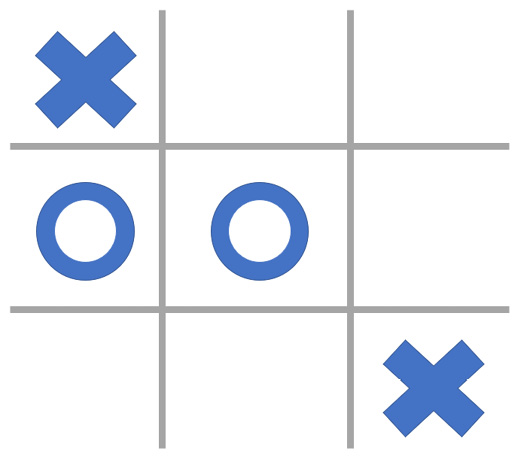
Figure 1.3 – An example board configuration in tic-tac-toe
Now, imagine that we have an RL agent playing against a human player.
- The action the agent takes is to place its mark (say a cross) in one of the empty spaces on the board when it is the agent's turn.
- Here, the board is the entire environment; and the position of the marks on the board is the state, which is fully observable to the agent.
- In a 3x3 tic-tac-toe game, there are 765 states (unique board positions, excluding rotations and reflections) and the agent's goal is to learn a policy that will suggest an action for each of these states so as to maximize the chance of winning.
- The game can be defined as an episodic RL task. Why? Because the game will last for a maximum 9 turns and the environment will reach a terminal state. A terminal state is one where either three Xs or Os make a row; or one where no single mark makes a row and there is no space left on the board (a draw).
- Note that no reward is given as the players make their moves during the game, except at the very end if a player wins. So, the agent receives +1 reward if it wins, -1 if it loses and 0 if the game is a draw. In all the iterations until the end, the agent receives 0 reward.
- We can turn this into a multi-agent RL problem by replacing the human player with another RL agent to compete with the first one.
Hopefully, this refreshes your mind on what agent, state, action, observation, policy and reward mean. This was just a toy example and rest assured that it will get much more advanced later. With this introductory context out of the way, what we need to do is to setup our computer environment to be able to run the RL algorithms we will cover in the following chapters.






