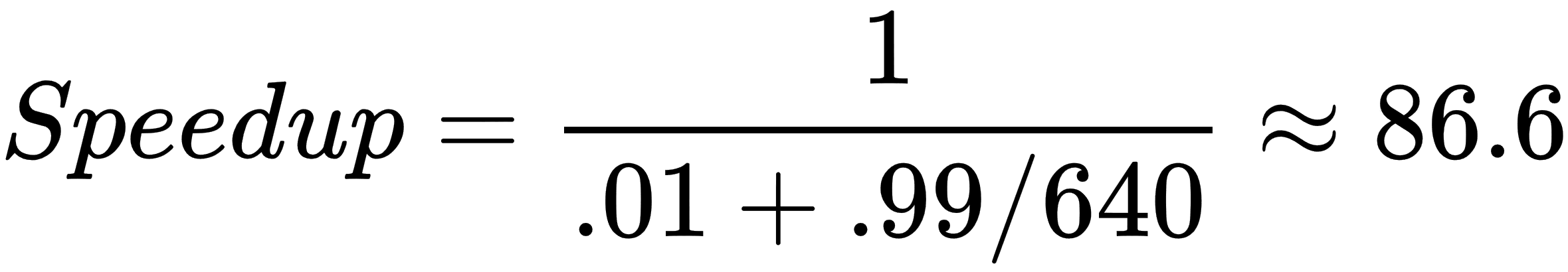Before we can dive in and unlock the potential of GPUs, we first have to realize where their computational power lies in comparison to a modern Intel/AMD central processing unit (CPU)—the power does not lie in the fact that it has a higher clock speed than a CPU, nor in the complexity or particular design of the individual cores. An individual GPU core is actually quite simplistic, and at a disadvantage when compared to a modern individual CPU core, which use many fancy engineering tricks, such as branch prediction to reduce the latency of computations. Latency refers to the beginning-to-end duration of performing a single computation.
The power of the GPU derives from the fact that there are many, many more cores than in a CPU, which means a huge step forward in throughput. Throughput here refers to the number of computations that can be performed simultaneously. Let's use an analogy to get a better understanding of what this means. A GPU is like a very wide city road that is designed to handle many slower-moving cars at once (high throughput, high latency), whereas a CPU is like a narrow highway that can only admit a few cars at once, but can get each individual car to its destination much quicker (low throughput, low latency).
We can get an idea of the increase in throughput by seeing how many cores these new GPUs have. To give you an idea, the average Intel or AMD CPU has only two to eight cores—while an entry-level, consumer-grade NVIDIA GTX 1050 GPU has 640 cores, and a new top-of-the-line NVIDIA RTX 2080 Ti has 4,352 cores! We can exploit this massive throughput, provided we know how properly to parallelize any program or algorithm we wish to speed up. By parallelize, we mean to rewrite a program or algorithm so that we can split up our workload to run in parallel on multiple processors simultaneously. Let's think about an analogy from real-life.
Suppose that you are building a house and that you already have all of the designs and materials in place. You hire a single laborer, and you estimate it will take 100 hours to construct the house. Let's suppose that this particular house can be built in such a way that the work can be perfectly divided between every additional laborer you hire—that is to say, it will take 50 hours for two laborers, 25 hours for four laborers, and 10 hours for ten laborers to construct the house—the number of hours to construct your house will be 100 divided by the number of laborers you hire. This is an example of a parallelizable task.
We notice that this task is twice as fast to complete for two laborers, and ten times as fast for ten laborers to complete together (that is, in parallel) as opposed to one laborer building the house alone (that is, in serial)—that is, if N is the number of laborers, then it will be N times as fast. In this case, N is known as the speedup of parallelizing our task over the serial version of our task.
Before we begin to program a parallel version of a given algorithm, we often start by coming up with an estimate of the potential speedup that parallelization would bring to our task. This can help us determine whether it is worth expending resources and time writing a parallelization of our program or not. Because real life is more complicated than the example we gave here, it's pretty obvious that we won't be able to parallelize every program perfectly, all of the time—most of the time, only a part of our program will be nicely parallelizable, while the rest will have to run in serial.
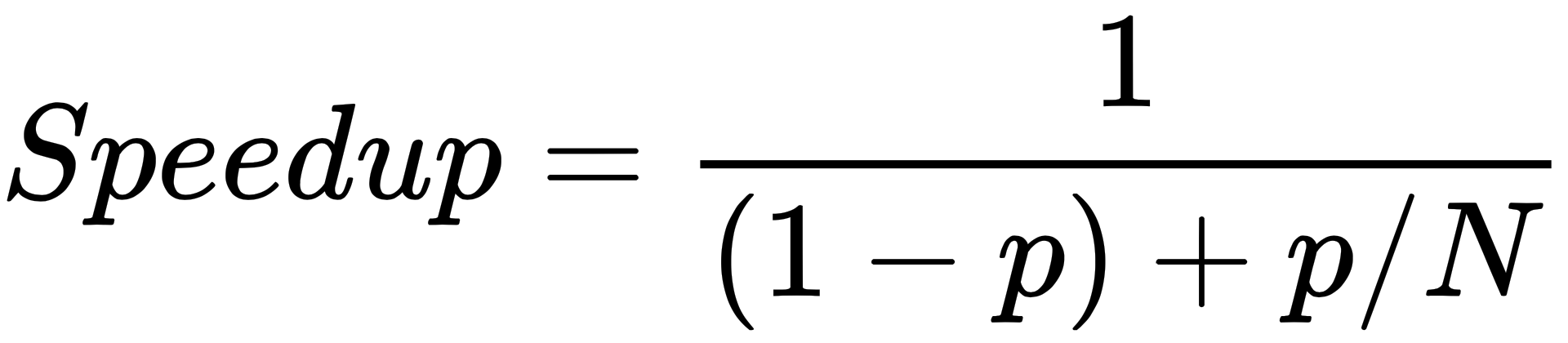
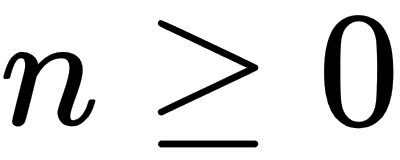 , with
, with 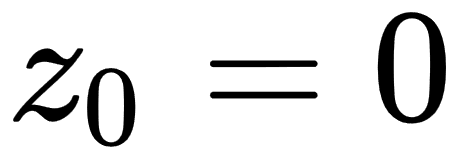 and
and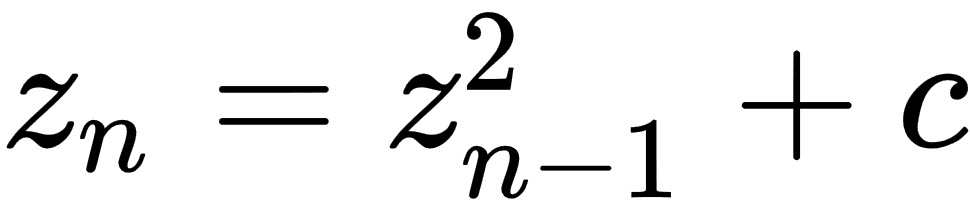 for
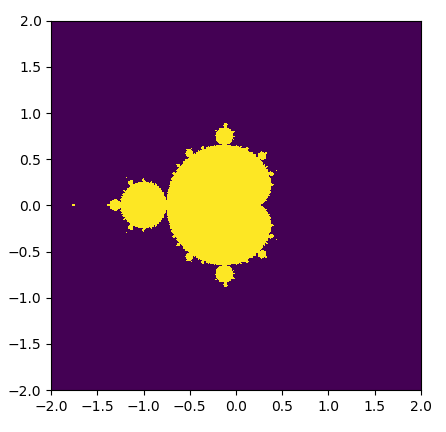
for 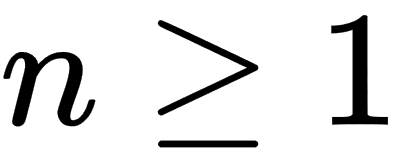 . If |zn| remains bounded by 2 as n increases to infinity, then we will say that c is a member of the Mandelbrot set.
. If |zn| remains bounded by 2 as n increases to infinity, then we will say that c is a member of the Mandelbrot set.