






















































Download OnlineRetail.csv from the link provided with the book. Then, you can load the file using Pandas.
The following is a simple way of reading a local file using Pandas:
import pandas as pd
path = '/Users/sridharalla/Documents/OnlineRetail.csv'
df = pd.read_csv(path)
However, since we are analyzing data in a Hadoop cluster, we should be using hdfs not a local system. The following is an example of how the hdfs file can be loaded into a pandas DataFrame:
import pandas as pd
from hdfs import InsecureClient
client_hdfs = InsecureClient('http://localhost:9870')
with client_hdfs.read('/user/normal/OnlineRetail.csv', encoding = 'utf-8') as reader:
df = pd.read_csv(reader,index_col=0)
The following is what the following line of code does:
df.head(3)
You will get the following result:
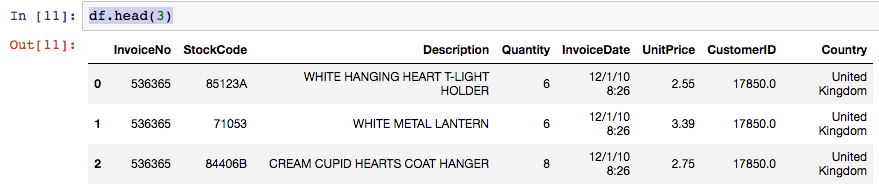
Basically, it displays the top three entries...




