Regression algorithms are a type of supervised algorithm that uses features of the input data to predict a value, such as the cost of a house, given certain features, such as size, age, number of bathrooms, number of floors, and location. Regression analysis tries to find the value of the parameters for the function that best fits an input dataset.
In a linear-regression algorithm, the goal is to minimize a cost function by finding appropriate parameters for the function, over the input data that best approximates the target values. A cost function is a function of the error, that is, how far we are from getting a correct result. A popular cost function is the mean square error (MSE), where we take the square of the difference between the expected value and the predicted result. The sum over all the input examples gives us the error of the algorithm and represents the cost function.
Say we have a 100-square-meter house that was built 25 years ago with 3 bathrooms and 2 floors. Let's also assume that the city is divided into 10 different neighborhoods, which we'll denote with integers from 1 to 10, and say this house is located in the area denoted by 7. We can parameterize this house with a five-dimensional vector, x = (100, 25, 3, 2, 7). Say that we also know that this house has an estimated value of €100,000. What we want is to create a function, f, such that f(x) = 100000.
In linear regression, this means finding a vector of weights, w= (w1, w2, w3, w4, w5), such that the dot product of the vectors, x • w = 10000, would be 100*w1 + 25*w2 + 3*w3 + 2*w4 + 7*w5 = 100000 or 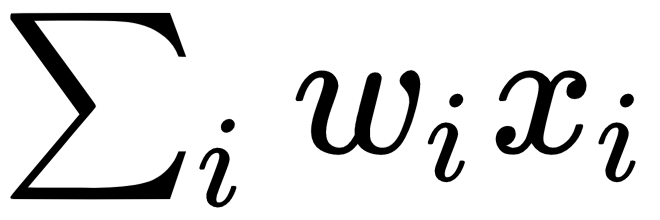 . If we had 1,000 houses, we could repeat the same process for every house, and ideally we would like to find a single vector, w, that can predict the correct value that is close enough for every house. The most common way to train a linear regression model can be seen in the following pseudocode block:
. If we had 1,000 houses, we could repeat the same process for every house, and ideally we would like to find a single vector, w, that can predict the correct value that is close enough for every house. The most common way to train a linear regression model can be seen in the following pseudocode block:
Initialize the vector w with some random values
repeat:
E = 0 # initialize the cost function E with 0
for every sample/target pair (xi, ti) of the training set:
E += 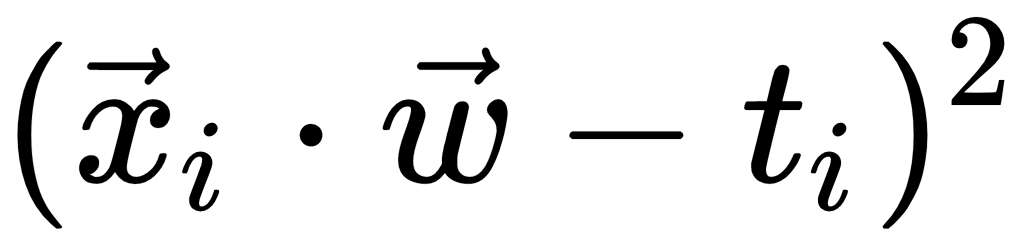 # here ti is the real cost of the house
# here ti is the real cost of the house
MSE = E / total_number_of_samples # Mean Square Error
use gradient descent to update the weights w based on MSE
until MSE falls below threshold
First, we iterate over the training data to compute the cost function, MSE. Once we know the value of MSE, we'll use the gradient-descent algorithm to update w. To do this, we'll calculate the derivatives of the cost function with respect to each weight, wi . In this way, we'll know how the cost function changes (increase or decrease) with respect to wi . Then we'll update its value accordingly. In Chapter 2, Neural Networks, we will see that training neural networks and linear/logistic regressions have a lot in common.
We demonstrated how to solve a regression problem with linear regression. Let's take another task: trying to determine whether a house is overvalued or undervalued. In this case, the target data would be categorical [1, 0] - 1 for overvalued, 0 for undervalued, if the price of the house will be an input parameter instead of target value as before. To solve the task, we'll use logistic regression. This is similar to linear regression but with one difference: in linear regression, the output is 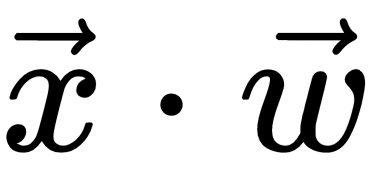 . However, here the output will be a special logistic function (https://en.wikipedia.org/wiki/Logistic_function),
. However, here the output will be a special logistic function (https://en.wikipedia.org/wiki/Logistic_function), 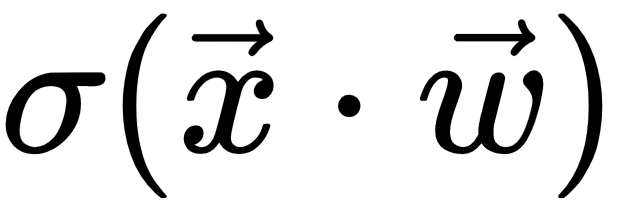 . This will squash the value of
. This will squash the value of 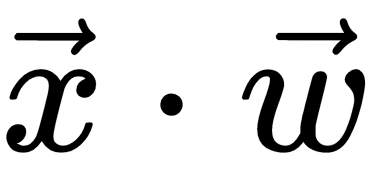 in the (0:1) interval. You can think of the logistic function as a probability, and the closer the result is to 1, the more chance there is that the house is overvalued, and vice versa. Training is the same as with linear regression, but the output of the function is in the (0:1) interval and the labels is either 0 or 1.
in the (0:1) interval. You can think of the logistic function as a probability, and the closer the result is to 1, the more chance there is that the house is overvalued, and vice versa. Training is the same as with linear regression, but the output of the function is in the (0:1) interval and the labels is either 0 or 1.
Logistic regression is not a classification algorithm, but we can turn it into one. We just have to introduce a rule that determines the class based on the logistic function output. For example, we can say that a house is overvalued if the value of 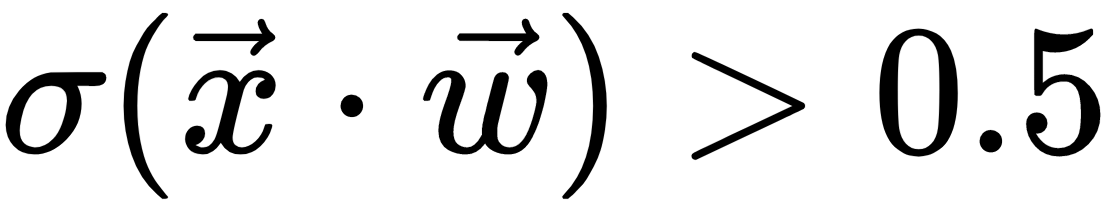 and undervalued otherwise.
and undervalued otherwise.

 Germany
Germany
 Slovakia
Slovakia
 Canada
Canada
 Brazil
Brazil
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 United States
United States
 Great Britain
Great Britain
 India
India
 Spain
Spain
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 France
France
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Australia
Australia
 Japan
Japan
 Russia
Russia























