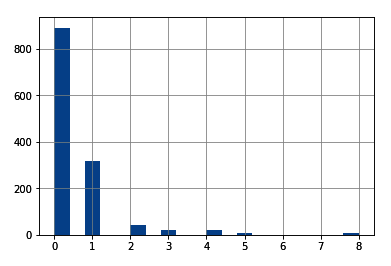
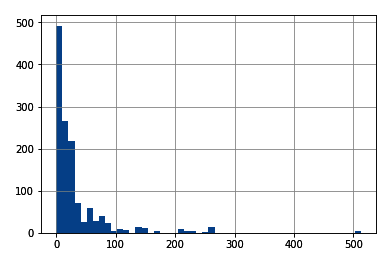
Numerical variables can be discrete or continuous. Discrete variables are those where the pool of possible values is finite and are generally whole numbers, such as 1, 2, and 3. Examples of discrete variables include the number of children, number of pets, or the number of bank accounts. Continuous variables are those whose values may take any number within a range. Examples of continuous variables include the price of a product, income, house price, or interest rate. Categorical variables are values that are selected from a group of categories, also called labels. Examples of categorical variables include gender, which takes values of male and female, or country of birth, which takes values of Argentina, Germany, and so on.
In this recipe, we will learn how to identify continuous, discrete, and categorical variables by inspecting their values and the data type that they are stored and loaded with in pandas.