C# provides an extensive set of operators for built-in types. Operators are broadly classified in the following categories: arithmetic, relational, logical, bitwise, assignment, and other operators. Some operators can be overloaded for user-defined types. This topic will be further discussed in Chapter 5, Object-Oriented Programming in C#.
When evaluating an expression, operator precedence and associativity determine the order in which the operations are performed. You can change this order by using parentheses, just like you would do with a mathematical expression.
The following table lists the order of the operators with the highest precedence at the top and the lowest at the bottom. Operators that are listed together, on the same row, have equal precedence:
For operators with the same precedence, associativity determines which one is evaluated first. There are two types of associativity:
- Left-associativity: This determines operators to be evaluated from left to right. All of the binary operators are left-associative except for the assignment operators and the null coalescing operators.
- Right-associativity: This determines operators to be evaluated from right to left. The assignment operator, the null-coalescing operator, and the conditional operator are right-associative.
In the following sections, we will take a closer look at each category of operators.
Arithmetic operators
Arithmetic operators perform arithmetic operations on the numerical type and can be unary or binary operators. A unary operator has a single operand, and a binary operator has two operands. The following set of arithmetic operators are defined in C#:
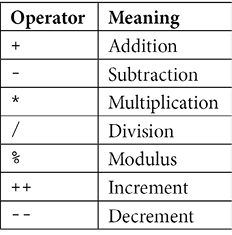
+, -, and * will work as per the mathematical rules of addition, subtraction, and multiplication respectively. However, the / operator behaves a bit differently. When applied to an integer, it will truncate the remainder of the division. For example, 20/3 will return 6. To get the remainder, we need to use the modulus operator. For example, 20%3 will return 2.
Among these, the increment and decrement operators require special attention. These operators have two forms:
- A postfix form
- A prefix form
The increment operator will increase the value of its operand by 1, whereas the decrement operator will decrease the value of its operand by 1. In the following example, the a variable is initially 10, but after applying the increment operator, its value will be 11:
int a = 10;
a++;
The prefix and the postfix variants differ in the following way:
- The prefix operator first performs the operation and then returns the value.
- The postfix operator first retains the value, then increments it, and then returns the original value.
Let's understand this with the help of the following code snippet. In the following example, a is 10. When a++ is assigned to b, b takes the value 10 and a is incremented to 11:
int a = 10;
int b = a++;
However, if we change this so that we assign ++a to b, then a will be incremented to 11, and that value will be assigned to b, so both a and b will have the value 11:
int a = 10;
int b = ++a;
The next category of operators that we will learn about is the relational operator.
Relational operators
Relational operators, also called comparison operators, perform a comparison on their operands. C# defines the following sets of relational operators:
The result of a relational operator is a bool value. These operators support all of the built-in numerical and floating-point types. However, enumerations also support these operators. For operands of the same enumeration type, the corresponding values of the underlying integral types are compared. Enumerations will be later discussed in Chapter 4, Understanding the Various User-Defined Types.
The next code listing shows several relational operators being used:
int a = 42;
int b = 10;
bool v1 = a != b;
bool v2 = 0 <= a && a <= 100;
if(a == 42) { /* ... */ }
The <, >, <=, and >= operators can be overloaded for user-defined types. However, if a type overloads < or >, it must overload both of them. Similarly, if a type overloads <= or >=, it must overload both of them.
Logical operators
Logical operators perform a logical operation on bool operands. The following set of logical operators are defined in C#:
The following example shows these operands in use:
bool a = true, b = false;
bool c = a && b;
bool d = a || !b;
In this example, since a is true and b is false, c will be false and d will be true.
Bitwise and shift operators
A bitwise operator will work directly on the bits of their operands. A bitwise operator can only be used with integer operands. The following table lists all of the bitwise and shift operators:
In the following example, a is 10, which in binary is 1010, and b is 5, which in binary is 0101. The result of the bitwise AND is 0000, so c will have the value 0, and the result of bitwise OR is 1111, so d will have the value 15:
int a = 10; // 1010
int b = 5; // 0101
int c = a & b; // 0000
int d = a | b; // 1111
The left-shift operator shifts the left-hand operand to the left by the number of bits defined by the right-hand operand. Similarly, the right-shift operator shifts the left-hand operand to the right by the number of bits defined by the right-hand operand. The left-shift operator discards the higher-order bits that are outside the range of the result type and sets the lower-order bits to zero. The right-shift operator discards the lower-order bits and the higher-order bits are set as follows:
- If the value that is shifted is
int or long, an arithmetic shift is performed. That means the sign bit is propagated to the right on the higher-order empty bits. As a result, for a positive number, the higher-order bits are set to zero (because the sign bit is 0) and for a negative number, the higher-order bits are set to one (because the sign bit is 1).
- If the value that is shifted is
uint or ulong, a logical shift is performed. In this case, the higher-order bits are always set to 0.
The shift operations are only defined for int, uint, long, and ulong. If the left-hand operand is of another integral type, it is converted to int before the operation is applied. The result of a shift operation will always contain at least 32 bits.
The following listing shows examples of shifting operations:
// left-shifting
int x = 0b_0000_0110;
x = x << 4; // 0b_0110_0000
uint y = 0b_1111_0000_0000_0000_1111_1110_1100_1000;
y = y << 2; // 0b_1100_0000_0000_0011_1111_1011_0010_0000;
// right-shifting
int x = 0b_0000_0000;
x = x >> 4; // 0b_0110_0000
uint y = 0b_1111_0000_0000_0000_1111_1110_1100_1000;
y = y >> 2; // 0b_0011_1100_0000_0000_0011_1111_1011_0010;
In this example, we initialized the x and y variables with binary literals to make it easier to understand how shifting works. The value of the variables after shifting is also shown in binary in the comments.
Assignment operators
An assignment operator assigns a value to its left operand based on the value of its right operand. The following assignment operators are available in C#:
In this table, we have the simple assignment operator (=) that assigns the right-hand value to the left operand, and then we have compound assignment operators, that first perform an operation (arithmetical, shifting, or bitwise) and then assign the result of the operation to the left operand. Therefore, operations such as a = a + 2 and a += 2 are equivalent.
Other operators
Apart from the operators discussed so far, there are other useful operators in C# that work both on built-in types and user-defined types. These include the conditional operator, the null-conditional operators, the null-coalescing operator, and the null-coalescing assignment operator. We will look at these operators in the following pages.
The ternary conditional operator
The ternary conditional operator is denoted by ?: and often simply referred to as the conditional operator. It allows you to return a value from two available options based on whether a Boolean condition evaluates to true or false.
The syntax of the ternary operator is as follow:
condition ? consequent : alternative;
If the Boolean condition evaluates to true, the consequent expression will be evaluated, and its result returned. Otherwise, the alternative expression will be evaluated, and its result returned. The ternary conditional operator can also be perceived as a shorthand for an if-else statement.
In the following example, the function called max() returns the maximum of two integers. The conditional operator is used to check whether a is greater or equal to b, in which case the value of a is returned; otherwise, the result is the value of b:
static int max(int a, int b)
{
return a >= b ? a : b;
}
There is another form of this operator called conditional ref expression (available since C# 7.2) that allows returning the reference to the result of one of the two expressions. The syntax, in this case, is as follows:
condition ? ref consequent : ref alternative;
The result reference can be assigned to a ref local or ref read-only local variable and uses it as a reference return value or as a ref method parameter. The conditional ref expression requires the type of consequent and alternative to be the same.
In the following example, the conditional ref expression is used to select between two alternatives based on user input. If an even number is introduced, the v variable will hold a reference to a; otherwise, it will hold a reference to b. The value of v is incremented and then a and b are printed to the console:
int a = 42;
int b = 21;
int.TryParse(Console.ReadLine(), out int alt);
ref int v = ref (alt % 2 == 0 ? ref a : ref b);
v++;
Console.WriteLine($"a={a}, b={b}");
While the conditional operator checks whether a condition is true or not, the null-conditional operator checks whether an operand is null or not. We will look at this operator in the next section.
The null-conditional operators
The null-conditional operator has two forms: ?. (also known as the Elvis operator) to apply member access and ?[] to apply element access for an array. These operators apply the operation to their operand if and only if that operand is not null. Otherwise, the result of applying the operator is also null.
The following example shows how to use the null-conditional operator to invoke a method called run() from an instance of a class called foo, through an object that might be null. Notice that the result is a nullable type (int?) because if the operand of ?. is null, then the result of its evaluation is also null:
class foo
{
public int run() { return 42; }
}
foo f = null;
int? i = f?.run()
The null-conditional operators can be chained together. However, if one operator in the chain is evaluated to null, the rest of the chain is short-circuited and does not evaluate.
In the following example, the bar class has a property of the foo type. An array of bar objects is created and we try to retrieve the value from the execution of the run() method from the f property of the first bar element in the array:
class bar
{
public foo f { get; set; }
}
bar[] bars = new bar[] { null };
int? i = bars[0]?.f?.run();
We can avoid the use of a nullable type if we combine the null-conditional operator with the null-coalescing operator and provide a default value in case the null-conditional operator returns null. An example is shown here:
int i = bars[0]?.f?.run() ?? -1;
The null-coalescing operator is discussed in the following section.
The null-coalescing and null-coalescing assignment operators
The null-coalescing operator, denoted by ??, will return the left-hand operand if it is not null; otherwise, it will evaluate the right-hand operand and return its result. The left-hand operand cannot be a non-nullable value type. The right-hand operand is only evaluated if the left-hand operand is null.
The null-coalescing assignment operator, denoted by ??=, is a new operator added in C# 8. It assigns the value of its right-hand operand to its left-hand operand, if and only if the left-hand operand evaluates to null. If the left-hand operand is not null, then the right-hand operand is not evaluated.
Both ?? and ??= are right-associative. That means, the expression a ?? b ?? c is evaluated as a ?? (b ?? c). Similarly, the expression a ??= b ??= c is evaluated as a ??= (b ??= c).
Take a look at the following code snippet:
int? n1 = null;
int n2 = n1 ?? 2; // n2 is set to 2
n1 = 5;
int n3 = n1 ?? 2; // n3 is set to 5
We have defined a nullable variable, n1, and initialized it to null. The value of n2 will be set to 2 as n1 is null. After assigning n1 a non-null value, we will apply the conditional operator on n1 and integer 2. In this case, since n1 is not null, the value of n3 will be the same as that of n1.
The null-coalescing operator can be used multiple times in an expression. In the following example, the GetDisplayName() function returns the value of name if this is not null; otherwise, it returns the value of email if it is not null; if email is also null, then it returns "unknown":
string GetDisplayName(string name, string email)
{
return name ?? email ?? "unknown";
}
The null-coalescing operator can also be used in argument checking. If a parameter is expected to be non-null, but it is in fact null, you can throw an exception from the right-hand operand. This is shown in the following example:
class foo
{
readonly string text;
public foo(string value)
{
text = value ?? throw new
ArgumentNullException(nameof(value));
}
}
The null-coalescing assignment operator is useful in replacing code that checks whether a variable is null before assigning it with a simpler, more succinct form. Basically, the ??= operator is syntactic sugar for the following code:
if(a is null)
a = b;
This can be replaced with a ??= b.

 Germany
Germany
 Slovakia
Slovakia
 Canada
Canada
 Brazil
Brazil
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 United States
United States
 Great Britain
Great Britain
 India
India
 Spain
Spain
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 France
France
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Australia
Australia
 Japan
Japan
 Russia
Russia




















