






















































Uncovering relationships between variables
If we are not dealing with a univariate time-series where there's only a single variable, the relationship between the variables needs to be investigated. This includes the direction and rough size of any correlations. This is important to avoid feature leakage and collinearity.
Feature leakage is when a variable unintentionally gives away the target. For example, the variable named amount_paid would give away the label has_paid. A more complex example would be if we were analyzing data for an online supermarket, and our dataset consisted of customer variables such as age, number of purchases in the past, length of visit, and finally the contents of their cart. What we want to predict, our target, is the result of their buying decision as either abandoned (when they canceled their purchase) or paid. We could find that a purchase is highly correlated with bags in their cart due to just the simple fact that bags are added at the last step. However, concluding we should offer bags to customers when they land on our site would probably miss the point, when it's the length of their stay that could be, in fact, the determining variable, and an intervention through a widget or customer service agent might be much more effective.
Collinearity means that independent variables (features) are correlated. The latter case can be problematic in linear models. Therefore, if we carry out linear regression and find two variables that are highly correlated between themselves, we should remove one of them or use dimensionality reduction techniques such as Principal Component Analysis (PCA).
The Pearson correlation coefficient was developed by Karl Pearson, whom we've discussed in the previous chapter, and named in his honor to distinguish it from other correlation coefficients. The Pearson correlation coefficient between two variables X and Y is defined as follows:

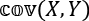 is the covariance between the two variables defined as the expected value (the mean) between the differences of each point to the variable mean:
is the covariance between the two variables defined as the expected value (the mean) between the differences of each point to the variable mean:

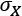 is the standard deviation of the variable X.
is the standard deviation of the variable X.
Expanded, the formula looks like this:

There are three types of correlation: positive, negative, and no correlation. Positive correlation means that as one variable increases the other does as well. In the case of the Pearson correlation coefficient, the increase of one variable to the other should be linear.
If we looked at a plot of global life expectancy from 1800 onward, we'd see an increase of years lived with the time axis. You can see the plot of global life expectancy based on data on OWID:

Figure 2.4: Life expectancy from 1800 to today
We can see how life expectancy has been increasing steadily since the end of the 19th century until today.
This plot is called a run chart or temporal line chart.
In order to calculate the Pearson correlation, we can use a function from SciPy:
from scipy import stats
def ignore_nans(a, b):
index = ~a.isnull() & ~b.isnull()
return a[index], b[index]
stats.pearsonr(*ignore_nans(pollution['Smoke'], pollution['SPM']))
Here's the Pearson correlation and the p-value that indicates significance (the lower, the more significant)
(0.9454809183096181, 3.313283689287137e-10
We see a very strong positive correlation of time with life expectancy, 0.94, at very high significance (the second number in the return). You can find more details about the dataset on the OWID website.
Conversely, we would see a negative correlation of time with child mortality – as the year increases, child mortality decreases. This plot shows the child mortality per 1,000 children on data taken from OWID:
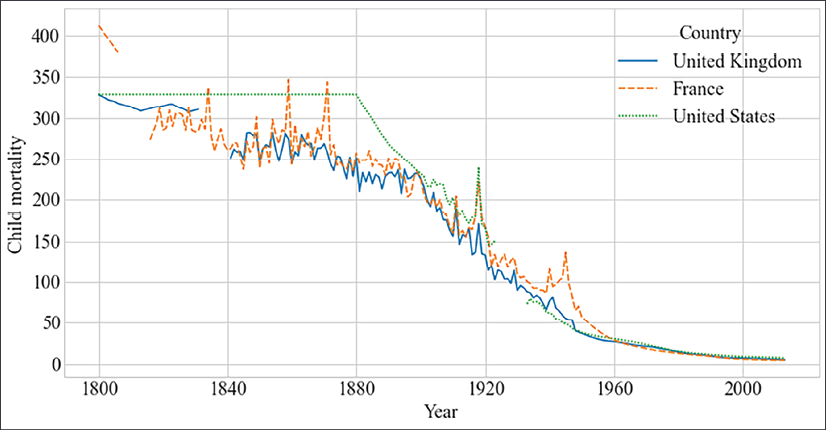
Figure 2.5: Child mortality from 1800 to today in the UK, France, and the USA
In this plot, we can see that in all three countries child mortality has been decreasing since the start of the 19th century until today.
In the case of the United States, we'll find a negative correlation of -0.95 between child mortality and time.
We can also compare the countries to each other. We can calculate correlations between each feature. In this case, each feature contains the values for the three countries.
This gives a correlation matrix of 3x3, which we can visualize as a heatmap:

Figure 2.6: Correlation heatmap of child mortality between the UK, France, and the USA
In this correlation heatmap, we can see that countries are highly correlated (for example, a correlation of 0.78 between France and the United Kingdom).
The diagonal of the correlation matrix is always 1.0, and the matrix is symmetrical across the diagonal. Therefore, sometimes we only show the lower triangle below the diagonal (or sometimes the upper triangle). We can see that child mortality in the United Kingdom is more similar to that of the United States than that of France.
Does this mean that the UK went through a similar development as the United States? These statistics and visualizations can often generate questions to answer, or hypotheses that we can test.
As mentioned before, the full notebooks for the different datasets are available on GitHub, however, here's the snippet for the heatmap:
import dython
dython.nominal.associations(child_mortality[countries], figsize=(12, 6));
The correlation coefficient struggles with cases where the increases are non-linear or non-continuous, or (because of the squared term) when there are outliers. For example, if we looked at air pollution from the 1700s onward, we'd see a steep increase in air pollutants from coal and – with the introduction of the steam engine – a decrease in pollutants.
A scatter plot can be used for showing and comparing numeric values. It plots values of two variables against each other. Usually, the variables are numerical – otherwise, we'd call this a table. Scatter plots can be crowded in certain areas, and therefore are deceptive if this can't be appreciated visually. Adding jitter and transparency can help to some degree, however, we can combine a scatter plot with the histograms of the variables we are plotting against each other, so we can see how many points on one or the other variable are being displayed. Scatter plots often have a best-fit line superimposed in order to visualize how one variable is the function of another variable.
Here's an example of how to plot a scatter plot with marginal histograms of the two variables in the pollution dataset:
plt.figure(figsize=(12, 6))
sns.jointplot(
x="Smoke", y="SPM",
edgecolor="white",
data=pollution
)
plt.xlabel("Smoke")
plt.ylabel("SPM");
Here's the resulting plot:

Figure 2.7: Scatter plot with marginal histograms of Smoke against SPM
In the scatter plot, we can see that the two variables are extremely similar – the values are all on the diagonal. The correlation between these two variables is perfect, 1.0, which means that they are in fact identical.
We've seen the dataset of Suspended Particulate Matter (SPM) before. Let's plot SPM over time:
pollution = pollution.pivot("Year", "City", "SPM")
plt.figure(figsize=(12, 6))
sns.lineplot(data=pollution)
plt.ylabel('SPM');
Here's the plot:

Figure 2.8: Suspended particle matter from the 1700s to today
We can see in the plot that the air quality (measured as suspended particle matter) in London was getting worse until around 1880 (presumably because of heating materials such as wood and coal), however, has since been improving.
We find a correlation coefficient of -0.36 with high significance. The steep decline of pollutants from 1880 onward dominates over the 180 years of slow growth. If we looked separately at the time from 1700 to 1880 and from 1880 to the present, we'd find 0.97 and -0.97 respectively, examples of very strong correlation and very strong anti-correlation.
The Spearman rank correlation can handle outliers and non-linear relationships much better than the Pearson correlation coefficient – although it can't handle non-continuous cases like the one above. The Spearman correlation is the Pearson correlation, only applied on ranks of variables' values instead of the variables' values directly. The Spearman correlation of the time-series for air pollution is -0.19, and for the two time periods before and after 1880 we get 0.99 and -0.99, respectively.
In the case of the Spearman correlation coefficient, the numerical differences are ignored – what counts is the order of the points. In this case, the order of the points within the two time periods aligns nearly perfectly.
In the next section, we'll talk about trend and seasonality.


