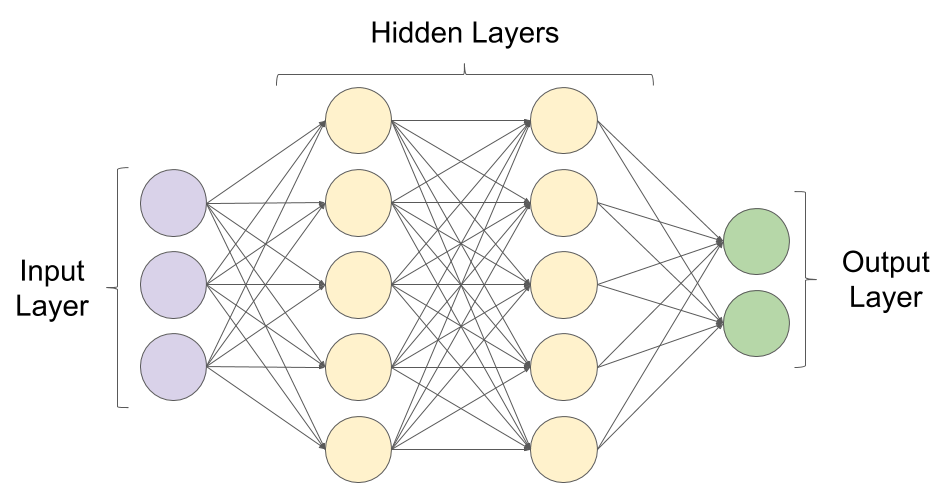
It is important to understand a few key concepts of machine learning and deep learning before you are able to work on solutions that are inclusive of the technologies and algorithms associated with the domain of AI. When we talk about the current state of AI, we often mean systems where we are able to churn a huge amount of data to find patterns and make predictions based on those patterns.
While the term "artificial intelligence" might bring up images of talking humanoid robots or cars that drive by themselves to a layman, to a person studying the field, the images might instead be in the form of graphs and networks of interconnected computing modules.
In the next section, we will begin with an introduction to machine learning.