Its easy to add or remove libraries from the Anaconda prompt. Once you have an the preferred environment activated, the simple Conda install command will search the Anaconda cloud repo for a matching package, and will begin download if it exists. Conda will warn if there are version dependencies with your other libraries. Always pay attention to these warnings, so that you know if any other library versions are affected. If, at any time, you need a reminder of what is in your environment, use the Conda list command to check package names and versions.
Let's look at some example commands:
- Create a new environment called my_env with Python version 3 using the following command:
(base) $ Conda create -n my_env Python=3
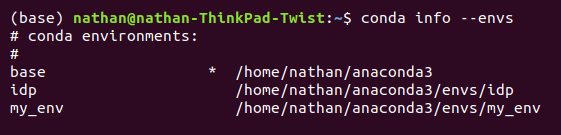
- Check whether my_env was created successfully by using the following command:
(base) $ Conda info --envs
You will see the following screen on the execution of the preceding command:
- Activate a new environment by using the following command:
(base) $ Conda activate my_env
- Install the numpy math library by using the following command:
(my_env) $ Conda install numpy
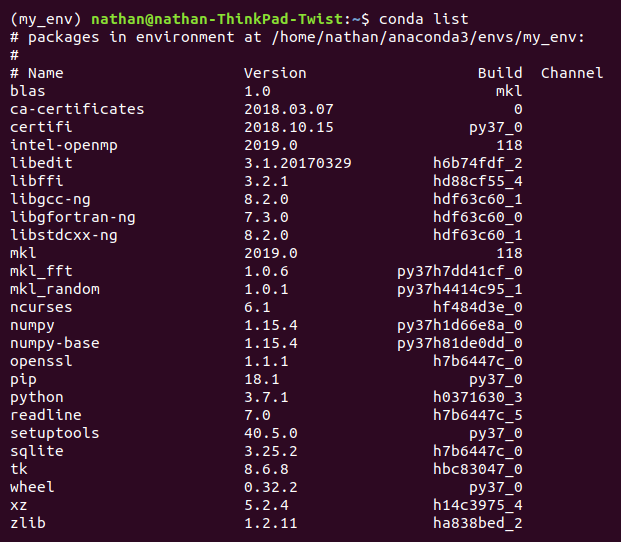
- Use Conda list as follows, to check whether a new library was installed or not and all other libraries and versions in my_env:
(my_env) $ Conda list
You will see the following screen on the execution of the preceding command: