






















































Discovering Optimus internals
Optimus is designed to be easy to use for non-technical users and developers. Once you know how some of the internals work, you'll know how some transformations work, and hopefully how to avoid any unexpected behavior. Also, you'll be able to expand Optimus or make more advanced or engine-specific transformations if the situation requires it.
Engines
Optimus handles all the details that are required to initialize any engine. Although pandas, Vaex, and Ibis won't handle many configuration parameters because they are non-distributed engines, Dask and Spark handle many configurations, some of which are mapped and some of which are passed via the *args or **kwargs arguments.
Optimus always keeps a reference to the engine you initialize. For example, if you want to get the Dask client from the Optimus instance, you can use the following command:
op.client
This will show you the following information:
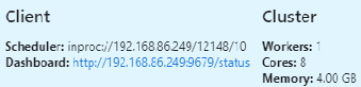
Figure 1.11 – Dask client object inside Optimus
One interesting thing about Optimus is that you can use multiple engines at the same time. This might seem weird at first, but it opens up amazing opportunities if you get creative. For example, you can combine Spark, to load data from a database, and pandas, to profile a data sample in real time, or use pandas to load data and use Ibis to output the instructions as a set of SQL instructions.
At the implementation level, all the engines inherit from BaseEngine. Let's wrap all the engine functionality to make three main operations:
- Initialization: Here, Optimus handles all the initialization processes for the engine you select.
- Dataframe creation:
op.create.dataframemaps to the DataFrame's creation, depending on the engine that was selected. - Data Loading:
op.loadhandles file loading and databases.
The DataFrame behind the DataFrame
The Optimus DataFrame is a wrapper that exposes and implements a set of functions to process string and numerical data. Internally, when Optimus creates a DataFrame, it creates it using the engine you select to keep a reference in the .data property. The following is an example of this:
op = Optimus("pandas")
df = op.load.csv("foo.txt", sep=",")
type(df.data)
This produces the following result:
Pandas.core.frame.DataFrame
A key point is that Optimus always keeps the data representation as DataFrames and not as a Series. This is important because in pandas, for example, some operations return a Series as result.
In pandas, use the following code:
import pandas as pd
type(pd.DataFrame({"A":["A",2,3]})["A"].str.lower())
pandas.core.series.Series
In Optimus, we use the following code:
from optimus import Optimus
op = Optimus("pandas")
type(op.create.dataframe({"A":["A",2,3]}).cols.lower().data)
pandas.core.frame.DataFrame
As you can see, both values have the same types.
Meta
Meta is used to keep some data that does not belong in the core dataset, but can be useful for some operations, such as saving the result of a top-N operation in a specific column. To achieve this, we save metadata in our DataFrames. This can be accessed using df.meta. This metadata is used for three main reasons. Let's look at each of them.
Saving file information
If you're loading a DataFrame from a file, it saves the file path and filename, which can be useful for keeping track of the data being handled:
from optimus import Optimus
op = Optimus("pandas")
df = op.load.csv("foo.txt", sep=",")
df.meta
You will get the following output:
{'file_name': 'foo.txt', 'name': 'foo.txt'}
Data profiling
Data cleaning is an iterative process; maybe you want to calculate the histogram or top-N values in the dataset to spot some data that you want to remove or modify. When you calculate profiling for data using df.profile(), Optimus will calculate a histogram or frequency chart, depending on the data type. The idea is that while working with the Actions data, we can identify when the histogram or top-N values should be recalculated. Next, you will see how Actions work.
Actions
As we saw previously, Optimus tries to cache certain operations to ensure that you do not waste precious compute time rerunning tasks over data that has not changed.
To optimize the cache usage and reconstruction, Optimus handles multiple internal Actions to operate accordingly.
You can check how Actions are saved by trying out the following code:
from optimus import Optimus
op = Optimus("pandas")
df = op.load.csv("foo.txt", sep=",")
df = df.cols.upper("*")
To check the actions you applied to the DataFrame, use the following command:
df.meta["transformations"]
You will get a Python dictionary with the action name and the column that's been affected by the action:
{'actions': [[{'upper': ['name']}], [{'upper': ['function']}]]}
A key point is that different actions have different effects on how the data is profiled and how the DataFrame's metadata is handled. Every Optimus operation has a unique Action name associated with it. Let's look at the five Actions that are available in Optimus and what effect they have on the DataFrame:
- Columns: These actions are triggered when operations are applied to entire Optimus columns; for example,
df.cols.lower()ordf.cols.sqrt(). - Rows: These actions are triggered when operations are applied to any row in an Optimus column; for example,
df.rows.set()ordf.rows.drop_duplicate(). - Copy: Triggered only for a copy column operation, such as
df.cols.copy(). Internally, it just creates a new key on thedictmeta with the source metadata column. If you copy an Optimus column, a profiling operation is not triggered over it. - Rename: Triggered only for a rename column operation, such as
df.cols.rename(). Internally, it just renames a key in the meta dictionary. If you copy an Optimus column, a profiling operation is not triggered over it. - Drop: Triggered only for a rename column operation, such as
df.cols.drop(). Internally, it removes a key in the meta dictionary. If you copy an Optimus column, a profiling operation is not triggered over it.
Dummy functions
There are some functions that do not apply to all the DataFrame technologies. Functions such as .repartition(), .cache(), and compute() are used in distributed DataFrames such as Spark and Dask to trigger operations in the workers, but these concepts do not exist in pandas or cuDF. To preserve the API's cohesion in all the engines, we can simply use pass or return the same DataFrame object.
Diagnostics
When you use Dask and Spark as your Optimus engine, you have access to their respective diagnostics dashboards. For very complex workflows, it can be handy to understand what operations have been executed and what could be slowing down the whole process.
Let's look at how this works in the case of Dask. To gain access to the diagnostic panel, you can use the following command:
op.client()
This will provide you with information about the Dask client:
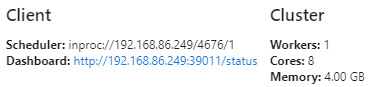
Figure 1.12 – Dask client information
In this case, you can point to http://192.168.86.249:39011/status in your browser to see the Dask Diagnostics dashboard:
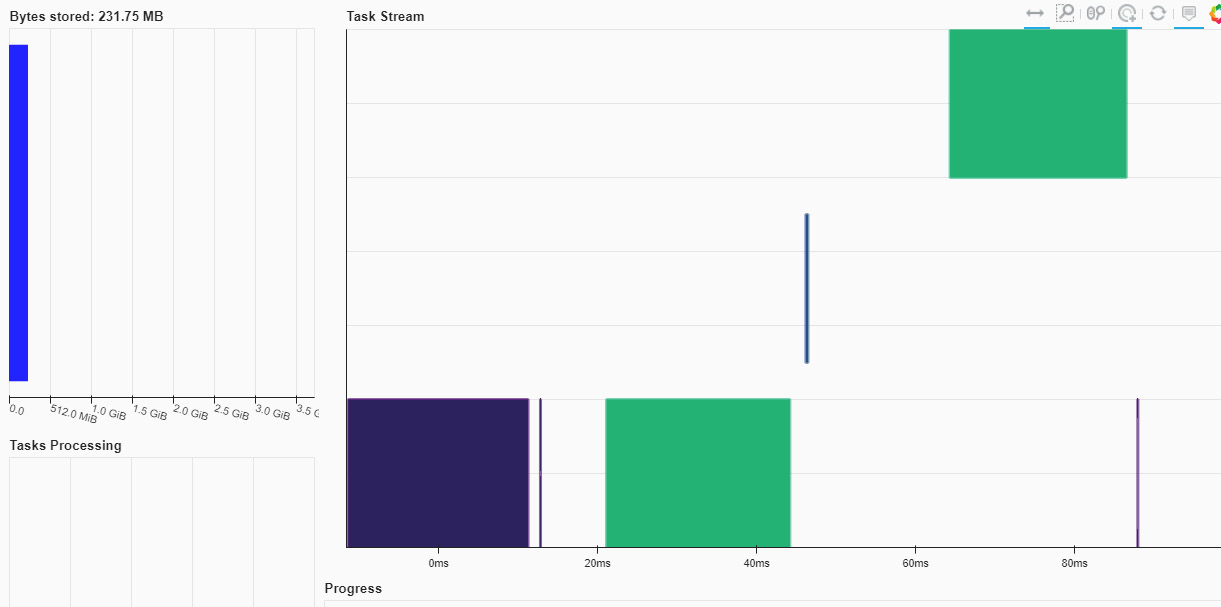
Figure 1.13 – Dask Diagnostics dashboard
An in-depth discussion about diagnostics is beyond the scope of this book. To find out more about this topic, go to https://docs.dask.org/en/latest/diagnostics-distributed.html.


