






















































Moving away from explicit state management is a very prominent theme in programming. We always need a higher level of abstraction over the shared state model. As explained earlier, explicit locking does not cut it.
The various concurrency patterns that we will study in this book try to stay away from explicit locking. For example, immutability is a major theme, giving us persistent data structures. A persistent data structure performs a smart copy on a write, thereby avoiding mutation altogether, as shown in the following diagram:
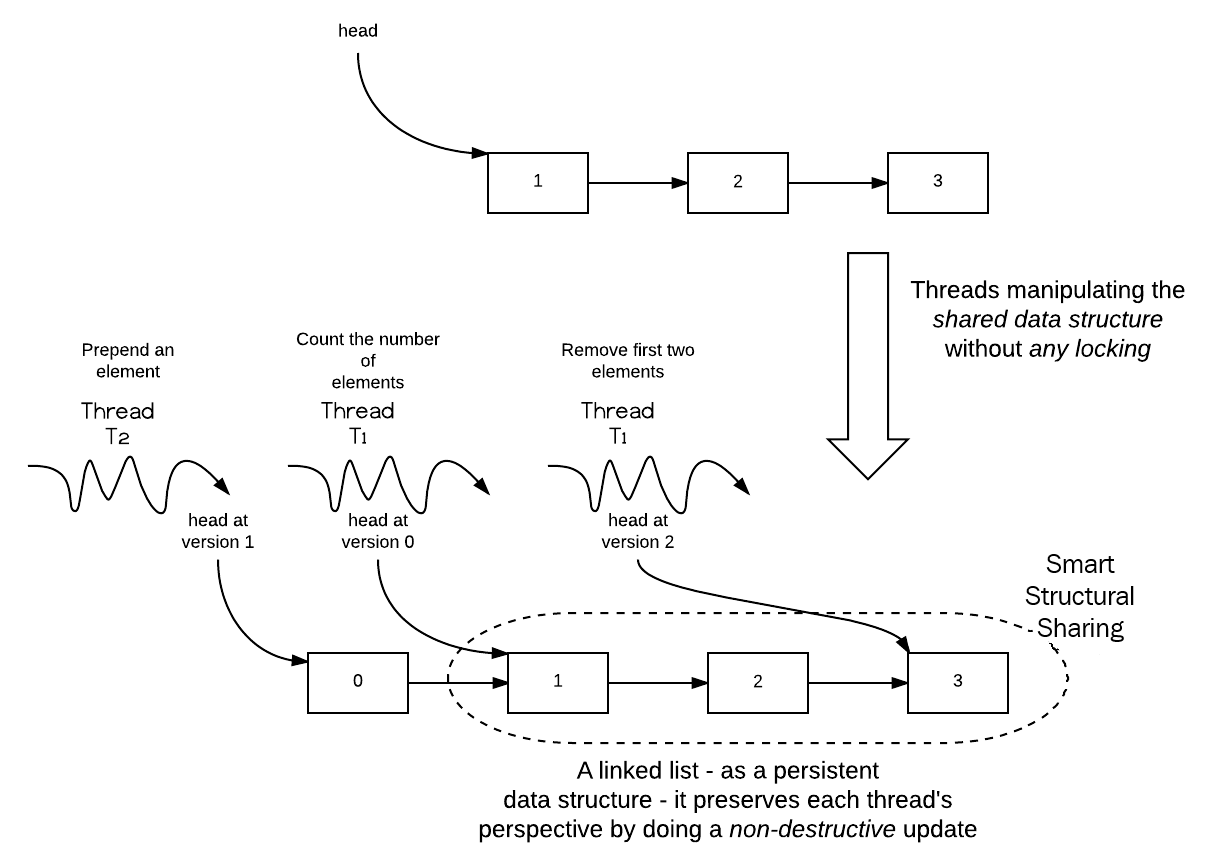
As shown in the preceding diagram, the original linked list has three elements, {1, 2, 3}. The head element of the list has the value 1. Thread T1 starts counting the number of elements in the list.
At any point in time, thread T2 can prepend an element to the original list. This should not disturb the world of thread T1; it should still see the original list as it is. In other words, T1's version of the list as it sees it is preserved. Any change in the list creates a new version of the data structure. As all the versions live as long as they are needed (that is, are persistent), we don't need any locking.
Similarly, thread T2 removes the first two elements. This is achieved by just setting its head to the third element; again, this doesn't disturb the state as seen by T1 and T2.
This is essentially copy-on-write. Immutability is a cornerstone of functional programming languages.
A typical concurrency pattern is an active object. For example, how would you consume a legacy code base from multiple threads? The code base was written without any parallelism in mind, the state is strewn around, and it is almost impossible to figure out.
A brute-force approach could be to just wrap up the code in a big God object. Each thread could lock this object, use it, and relinquish the lock. However, this design would hurt concurrency, as it means that other threads would simply have to wait! Instead, we could use an active object, as shown in the following diagram:
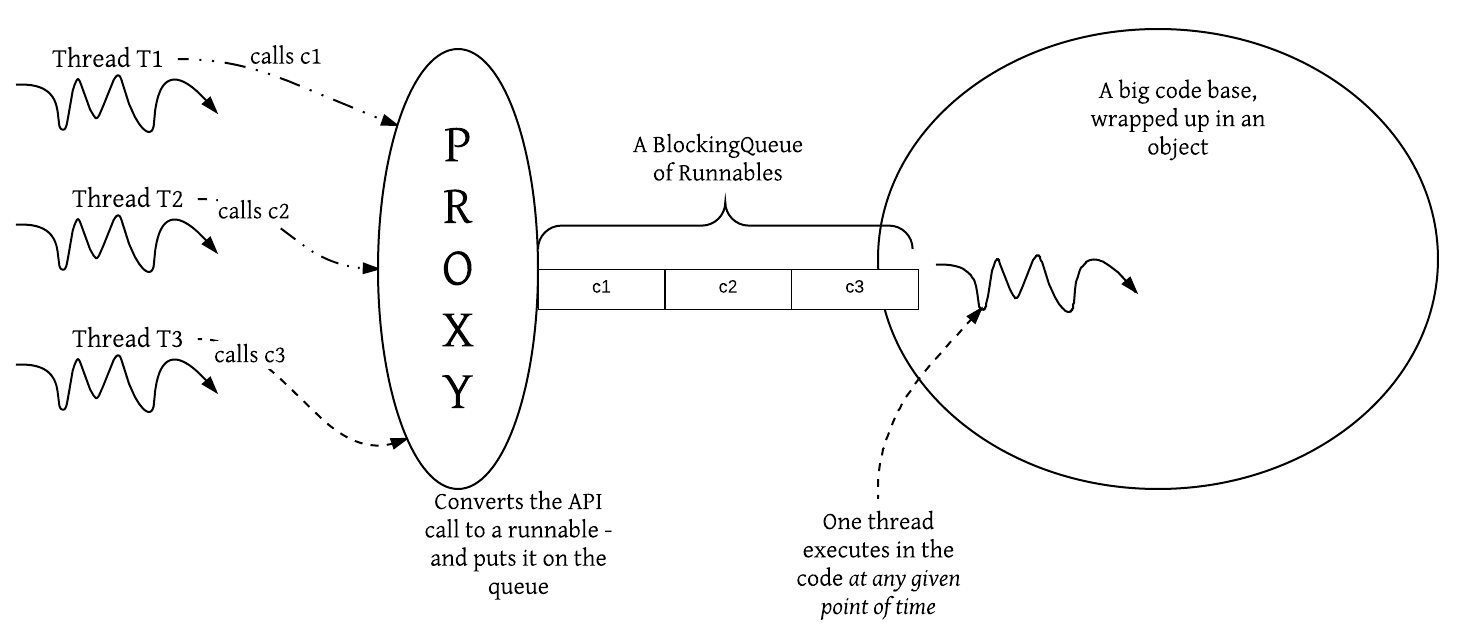
To use this active object, a proxy sits in between the caller threads and the actual code base. It converts each invocation of the API into a runnable and puts it in a blocking queue (a thread-safe FIFO queue).
There is just one thread running in the God object. It executes the runnables on the queue one by one, in contrast to how a typical Java object method is invoked (passively). Here, the object itself executes the work placed on the queue, hence the term active object.
The rest of this chapter describes the many patterns and paradigms, that have evolved over the years, and are used in order to avoid the explicit locking of the shared state.














