






















































Setting up retention policies for your objects
Amazon S3’s storage lifecycle allows you to manage the lifecycle of objects in an S3 bucket based on predefined rules. The lifecycle management feature consists of two main actions: transitions and expiration. Transitions involve automatically moving objects between different storage classes based on a defined duration. This helps in optimizing costs by storing less frequently accessed data in a cheaper storage class. Expiration, on the other hand, allows users to set rules to automatically delete objects from an S3 bucket. These rules can be based on a specified duration. Additionally, you can apply a combination of transitions and expiration actions to objects. Amazon S3’s storage lifecycle provides flexibility and ease of management for users and it helps organizations optimize storage costs while ensuring that data is stored according to its relevance and access patterns.
In this recipe, we will learn how to set up a lifecycle policy to archive objects in S3 Glacier after a certain period and then expire them.
Getting ready
To complete this recipe, you need to have a Glacier vault, which is a separate storage container that can be used to store archives, independent from S3. You can create one by following these steps:
- Open the AWS Management Console (https://console.aws.amazon.com/console/home?nc2=h_ct&src=header-signin) and navigate to the Glacier service.
- Click on Create vault to start creating a new Glacier vault.
- Provide a unique and descriptive name for your vault in the Vault name field.
- Optionally, you can choose to receive notifications for events by clicking Turn on notifications under the Event notifications section.
- Click on Create to create the vault.
How to do it…
- Open the AWS Management Console (https://console.aws.amazon.com/console/home?nc2=h_ct&src=header-signin) and navigate to the S3 service.
- Select the desired bucket for which you want to configure the lifecycle policy and navigate to the Management tab.
- In the left panel, select Lifecycle and click on Create lifecycle rule.
- Under Rule name, name the lifecycle rule to identify it.
- Under Choose a rule scope, you can choose Apply to all objects in the bucket or Limit the scope of this rule using one or more filters to specify the objects for which the rule will be applied. You can use one of the following filters or a combination of them:
- Filter objects based on prefixes (for example, logs)
- Filter objects based on tags; you can add multiple key-value pair tags to filter on
- Filter objects based on object size by setting Specify minimum object size and/or Specify maximum object size and specifying the size value and unit
The following screenshot shows a rule that’s been restricted to a set of objects based on a prefix:
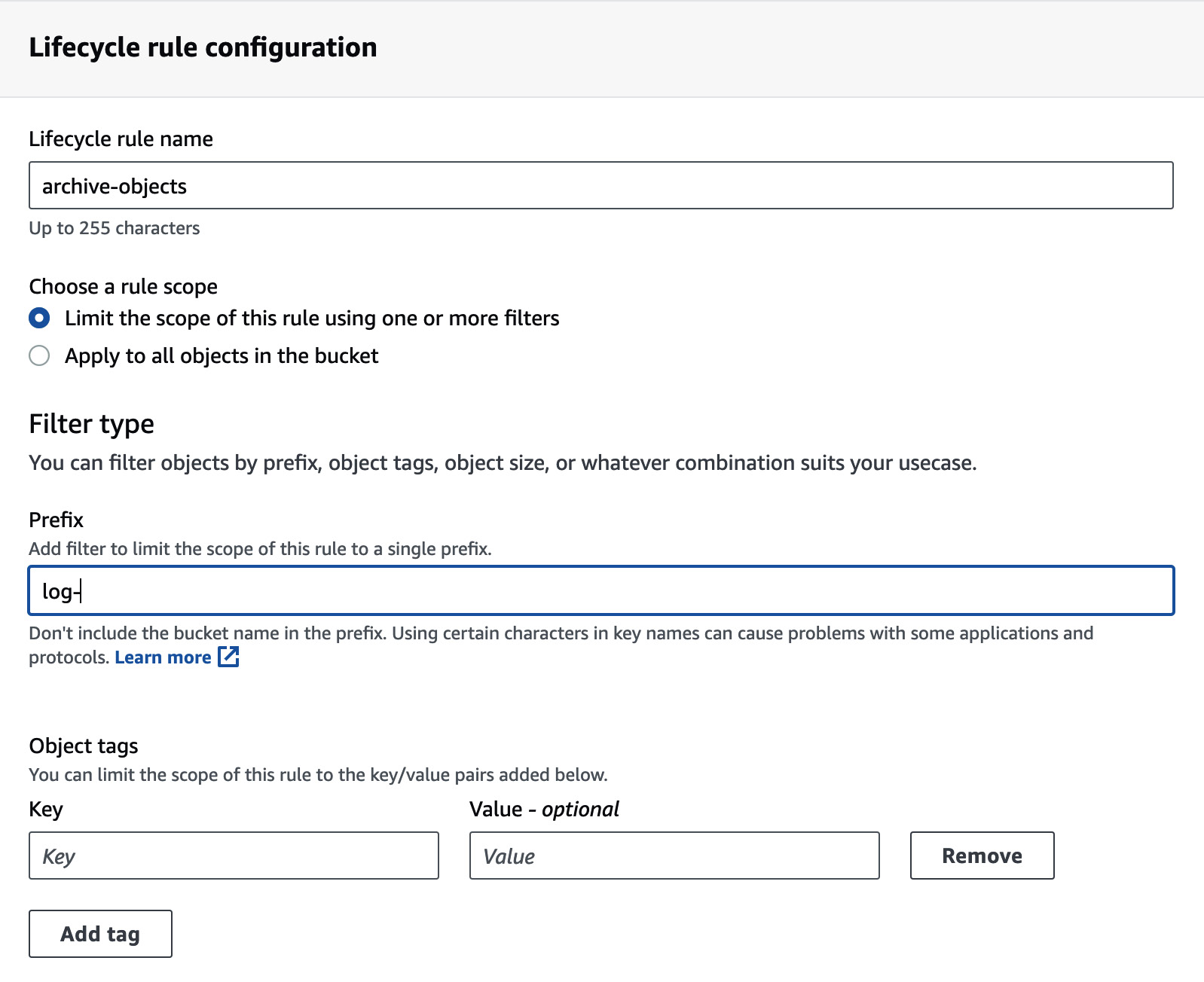
Figure 1.4 – Lifecycle rule configuration
- Under Lifecycle rule actions, select the following options:
- Move current versions of objects between storage classes. Then, choose one of the Glacier classes and set Days after object creation in which the object will be transitioned (for example,
60days). - Expire current versions of objects. Then, set Days after object creation in which the object will expire. Choose a value higher than the one you set for transitioning the object to Glacier (for example,
100).
Review the transition and expiration actions you have set and click on Create rule to apply the lifecycle policy to the bucket:
- Move current versions of objects between storage classes. Then, choose one of the Glacier classes and set Days after object creation in which the object will be transitioned (for example,

Figure 1.5 – Reviewing the lifecycle rule
Note
It may take some time for the lifecycle rule to be applied to all the selected objects, depending on the size of the bucket and the number of objects. The rule will affect existing files, not just new ones, so ensure that no applications are accessing files that will be archived or deleted as they will no longer be accessible via direct S3 retrieval.
How it works…
After you save the lifecycle rule, Amazon S3 will periodically evaluate it to find objects that meet the criteria specified in the lifecycle rule. In this recipe, the object will remain in its default storage type for the specified period (for example, 60 days) after which it will automatically be moved to the Glacier storage class. This transition is handled transparently, and the object’s metadata and properties remain unchanged. Once the objects are transitioned to Glacier, they are stored in a Glacier vault and become part of the Glacier storage infrastructure. Objects will then remain in Glacier for the remaining period of expiry (for example, 40 days), after which they will expire and be permanently deleted from your S3 bucket.
Please note that once the objects have expired, they will be queued for deletion, so it might take a few days after the object reaches the end of its lifetime for it to be deleted.
There’s more…
Lifecycle configuration can be specified as an XML when using the S3 API or AWS console, which can be helpful if you are planning on using the same lifecycle rules on multiple buckets. You can read more on setting this up at https://docs.aws.amazon.com/AmazonS3/latest/userguide/intro-lifecycle-rules.html.
See also
- Setting up notifications for events related to your lifecycle rule: https://docs.aws.amazon.com/AmazonS3/latest/userguide/lifecycle-configure-notification.html
- Supported lifecycle transitions and related constraints: https://docs.aws.amazon.com/AmazonS3/latest/userguide/lifecycle-transition-general-considerations.html











