






















































Data preprocessing and feature engineering
Data mining, a buzzword in the 1990s, is the predecessor of data science (the science of data). One of the methodologies popular in the data mining community is called the Cross-Industry Standard Process for Data Mining (CRISP-DM) (https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining). CRISP-DM was created in 1996, and machine learning basically inherits its phases and general framework.
CRISP-DM consists of the following phases, which aren't mutually exclusive and can occur in parallel:
- Business understanding: This phase is often taken care of by specialized domain experts. Usually, we have a businessperson formulate a business problem, such as selling more units of a certain product.
- Data understanding: This is also a phase that may require input from domain experts; however, often a technical specialist needs to get involved more than in the business understanding phase. The domain expert may be proficient with spreadsheet programs but have trouble with complicated data. In this machine learning book, it's usually termed the exploration phase.
- Data preparation: This is also a phase where a domain expert with only Microsoft Excel knowledge may not be able to help you. This is the phase where we create our training and test datasets. In this book, it's usually termed the preprocessing phase.
- Modeling: This is the phase most people associate with machine learning. In this phase, we formulate a model and fit our data.
- Evaluation: In this phase, we evaluate how well the model fits the data to check whether we were able to solve our business problem.
- Deployment: This phase usually involves setting up the system in a production environment (it's considered good practice to have a separate production system). Typically, this is done by a specialized team.
We will cover the preprocessing phase first in this section.
Preprocessing and exploration
When we learn, we require high-quality learning material. We can't learn from gibberish, so we automatically ignore anything that doesn't make sense. A machine learning system isn't able to recognize gibberish, so we need to help it by cleaning the input data. It's often claimed that cleaning the data forms a large part of machine learning. Sometimes, cleaning is already done for us, but you shouldn't count on it.
To decide how to clean the data, we need to be familiar with the data. There are some projects that try to automatically explore the data and do something intelligent, such as produce a report. For now, unfortunately, we don't have a solid solution in general, so you need to do some work.
We can do two things, which aren't mutually exclusive: first, scan the data and second, visualize the data. This also depends on the type of data we're dealing with—whether we have a grid of numbers, images, audio, text, or something else.
In the end, a grid of numbers is the most convenient form, and we will always work toward having numerical features. Let's pretend that we have a table of numbers in the rest of this section.
We want to know whether features have missing values, how the values are distributed, and what type of features we have. Values can approximately follow a normal distribution, a binomial distribution, a Poisson distribution, or another distribution altogether. Features can be binary: either yes or no, positive or negative, and so on. They can also be categorical: pertaining to a category, for instance, continents (Africa, Asia, Europe, South America, North America, and so on). Categorical variables can also be ordered, for instance, high, medium, and low. Features can also be quantitative, for example, the temperature in degrees or the price in dollars. Now, let me get into how we can cope with each of these situations.
Dealing with missing values
Quite often we miss values for certain features. This could happen for various reasons. It can be inconvenient, expensive, or even impossible to always have a value. Maybe we weren't able to measure a certain quantity in the past because we didn't have the right equipment or just didn't know that the feature was relevant. However, we're stuck with missing values from the past.
Sometimes, it's easy to figure out that we're missing values and we can discover this just by scanning the data or counting the number of values we have for a feature and comparing this figure with the number of values we expect based on the number of rows. Certain systems encode missing values with, for example, values such as 999,999 or -1. This makes sense if the valid values are much smaller than 999,999. If you're lucky, you'll have information about the features provided by whoever created the data in the form of a data dictionary or metadata.
Once we know that we're missing values, the question arises of how to deal with them. The simplest answer is to just ignore them. However, some algorithms can't deal with missing values, and the program will just refuse to continue. In other circumstances, ignoring missing values will lead to inaccurate results. The second solution is to substitute missing values with a fixed value—this is called imputing. We can impute the arithmetic mean, median, or mode of the valid values of a certain feature. Ideally, we will have some prior knowledge of a variable that is somewhat reliable. For instance, we may know the seasonal averages of temperature for a certain location and be able to impute guesses for missing temperature values given a date. We will talk about dealing with missing data in detail in Chapter 11, Machine Learning Best Practices. Similarly, techniques in the following sections will be discussed and employed in later chapters, in case you feel lost.
Label encoding
Humans are able to deal with various types of values. Machine learning algorithms (with some exceptions) require numerical values. If we offer a string such as Ivan, unless we're using specialized software, the program won't know what to do. In this example, we're dealing with a categorical feature—names, probably. We can consider each unique value to be a label. (In this particular example, we also need to decide what to do with the case—is Ivan the same as ivan?). We can then replace each label with an integer—label encoding.
The following example shows how label encoding works:
|
Label |
Encoded Label |
|
Africa |
1 |
|
Asia |
2 |
|
Europe |
3 |
|
South America |
4 |
|
North America |
5 |
|
Other |
6 |
Table 1.3: Example of label encoding
This approach can be problematic in some cases, because the learner may conclude that there is an order (unless it is expected, for example, bad=0, ok=1, good=2, excellent=3). In the preceding mapping table, Asia and North America in the preceding case differ by 4 after encoding, which is a bit counter-intuitive as it's hard to quantify them. One-hot encoding in the next section takes an alternative approach.
One-hot encoding
The one-of-K, or one-hot encoding, scheme uses dummy variables to encode categorical features. Originally, it was applied to digital circuits. The dummy variables have binary values such as bits, so they take the values zero or one (equivalent to true or false). For instance, if we want to encode continents, we will have dummy variables, such as is_asia, which will be true if the continent is Asia and false otherwise. In general, we need as many dummy variables as there are unique labels minus one. We can determine one of the labels automatically from the dummy variables, because the dummy variables are exclusive.
If the dummy variables all have a false value, then the correct label is the label for which we don't have a dummy variable. The following table illustrates the encoding for continents:
|
Label |
Is_africa |
Is_asia |
Is_europe |
Is_sam |
Is_nam |
|
Africa |
1 |
0 |
0 |
0 |
0 |
|
Asia |
0 |
1 |
0 |
0 |
0 |
|
Europe |
0 |
0 |
1 |
0 |
0 |
|
South America |
0 |
0 |
0 |
1 |
0 |
|
North America |
0 |
0 |
0 |
0 |
1 |
|
Other |
0 |
0 |
0 |
0 |
0 |
Table 1.4: Example of one-hot encoding
The encoding produces a matrix (grid of numbers) with lots of zeros (false values) and occasional ones (true values). This type of matrix is called a sparse matrix. The sparse matrix representation is handled well by the the scipy package and shouldn't be an issue. We will discuss the scipy package later in this chapter.
Scaling
Values of different features can differ by orders of magnitude. Sometimes, this may mean that the larger values dominate the smaller values. This depends on the algorithm we're using. For certain algorithms to work properly, we're required to scale the data.
There are the following several common strategies that we can apply:
- Standardization removes the mean of a feature and divides by the standard deviation. If the feature values are normally distributed, we will get a Gaussian, which is centered around zero with a variance of one.
- If the feature values aren't normally distributed, we can remove the median and divide by the interquartile range. The interquartile range is the range between the first and third quartile (or 25th and 75th percentile).
- Scaling features to a range is a common choice of range between zero and one.
We will use this method in many projects throughout the book.
An advanced version of data preprocessing is usually called feature engineering. We will cover that next.
Feature engineering
Feature engineering is the process of creating or improving features. It is more of a dark art than a science. Features are often created based on common sense, domain knowledge, or prior experience. There are certain common techniques for feature creation; however, there is no guarantee that creating new features will improve your results. We are sometimes able to use the clusters found by unsupervised learning as extra features. Deep neural networks are often able to derive features automatically.
We will briefly look at several techniques such as polynomial features, power transformations, and binning.
Polynomial transformation
If we have two features, a and b, we can suspect that there is a polynomial relationship, such as a2 + ab + b2. We can consider each term in the sum to be a feature—in the previous example, we have three features, which are a, b, and a2 + ab + b2. The product ab in the middle is called an interaction. An interaction doesn't have to be a product—although this is the most common choice—it can also be a sum, a difference, or a ratio. If we're using a ratio to avoid dividing by zero, we should add a small constant to the divisor and dividend.
The number of features and the order of the polynomial for a polynomial relation aren't limited. However, if we follow Occam's razor, we should avoid higher-order polynomials and interactions of many features. In practice, complex polynomial relations tend to be more difficult to compute and tend to overfit, but if you really need better results, they may be worth considering. We will see polynomial transformation in action in the Best practice 12 – performing feature engineering without domain expertise section in Chapter 11, Machine Learning Best Practices.
Power transforms
Power transforms are functions that we can use to transform numerical features in order to conform better to a normal distribution. A very common transformation for values that vary by orders of magnitude is to take the logarithm.
Taking the logarithm of a zero value and negative values isn't defined, so we may need to add a constant to all of the values of the related feature before taking the logarithm. We can also take the square root for positive values, square the values, or compute any other power we like.
Another useful power transform is the Box-Cox transformation, named after its creators, two statisticians called George Box and Sir David Roxbee Cox. The Box-Cox transformation attempts to find the best power needed to transform the original data into data that's closer to the normal distribution. In case you are interested, the transform is defined as follows:
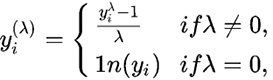
Binning
Sometimes, it's useful to separate feature values into several bins. For example, we may only be interested in whether it rained on a particular day. Given the precipitation values, we can binarize the values, so that we get a true value if the precipitation value isn't zero, and a false value otherwise. We can also use statistics to divide values into high, low, and medium bins. In marketing, we often care more about the age group, such as 18 to 24, than a specific age, such as 23.
The binning process inevitably leads to loss of information. However, depending on your goals, this may not be an issue, and actually reduces the chance of overfitting. Certainly, there will be improvements in speed and reduction of memory or storage requirements and redundancy.
Any real-world machine learning system should have two modules: a data preprocessing module, which we just covered in this section, and a modeling module, which will be covered next.






