In this section, we want to visualize the humidity distribution for the city of Vancouver. We'll create a histogram for humidity data using qplot and ggplot.
Let's begin by implementing the following steps:
- Create a plot with RStudio by using the following command: qplot(df_hum$Vancouver):
- Use ggplot to create the same plot using the following command:
ggplot(df_hum,aes(x=Vancouver))
This command does not do anything; ggplot2 requires the name of the object that we wish to make. To make a histogram, we have to specify the geom type (in other words, a histogram). aes stands for aesthetics, or the quantities that get plotted on the x- and y-axes, and their qualities. We will work on changing the aesthetics later, in order to visualize the plot more effectively.
Notice that there are some warning messages, as follows:
'stat_bin()' using 'bins = 30'. Pick better value with 'binwidth'.
Warning message:
Removed 1826 rows containing non-finite values (stat_bin).
You can ignore these messages; ggplot automatically detects and removes null or NA values.
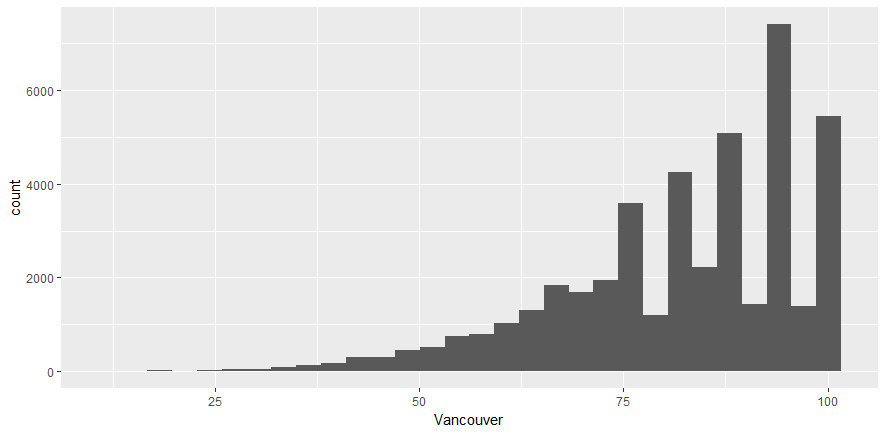
- Obtain the histogram with ggplot by using the following command:
ggplot (df_hum, aes(x=Vancouver)) + geom_histogram()
You'll see the following output:
Here's the output code:
require("ggplot2")
require("tibble")
#Load a data file - Read the Humidity Data
df_hum <- read.csv("data/historical-hourly-weather-data/humidity.csv")
#Display the summary
str(df_hum)
qplot(df_hum$Vancouver)
ggplot(df_hum, aes(x=Vancouver)) + geom_histogram()
Refer to the complete code at https://goo.gl/tu7t4y.
In order for ggplot to work, you will need to specify the geometric object. Note that the column name should not be enclosed in strings.























































































